What is Elasticsearch?Elasticsearch InstallationElasticsearch Data TypesElasticsearch Modeling DataElasticsearch MappingElasticsearch CAT APIElasticsearch Document APIElasticsearch Search APIElasticsearch SortingElasticsearch FilterElasticsearch AggregationElasticsearch Geo-PointElasticsearch Snapshot
Elasticsearch Table of Content
Elasticsearch Filter
The goal of filters is to reduce the number of documents that have to be examined by the query. Queries have to not only find matching documents, but also calculate how relevant each document is, which typically makes queries heavier than filters. Also, query results are not cachable. Filter is quick to calculate and easy to cache in memory, using only 1 bit per document. These cached filters can be reused efficiently for subsequent requests.
When to Use filter vs query?
As a general rule, use query clauses for full-text search or for any condition that should affect the relevance score, and use filter clauses for everything else.
There are two ways to filter search results.
- Use a boolean query with a
filterclause. Search requests apply boolean filters to both search hits and aggregations. - Use the search API’s
post_filterparameter. Search requests apply post filters only to search hits, not aggregations. You can use a post filter to calculate aggregations based on a broader result set, and then further narrow the results. A post filter has no impact on the aggregation results.
Term filter
The term filter is used to filter by exact values, be they numbers, dates, Booleans, or not_analyzed exact-value string fields. Here we are filtering out all users whose rating is not 5. In other words, only retrieve users with rating of 5.
GET elasticsearch_learning/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "rating": 5 }}
]
}
}
}
/**
* https://www.elastic.co/guide/en/elasticsearch/reference/current/filter-search-results.html
*/
@Test
void filterQuery() {
int pageNumber = 0;
int pageSize = 5;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
searchSourceBuilder.fetchSource(new String[]{"id", "firstName", "lastName", "rating", "dateOfBirth"}, new String[]{""});
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.termQuery("rating", 5));
searchSourceBuilder.query(boolQuery);
searchRequest.source(searchSourceBuilder);
searchRequest.preference("rating");
if (searchSourceBuilder.query() != null && searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
log.warn("IOException, msg={}", e.getLocalizedMessage());
e.printStackTrace();
} catch (Exception e) {
log.warn("Exception, msg={}", e.getLocalizedMessage());
e.printStackTrace();
}
}
Range filter
The range filter allows you to find numbers or dates that fall into a specified range. Here we are filtering out all users whose rating is either a 2, 3, or 4.
GET elasticsearch_learning/_search
{
"query":{
"bool" : {
"filter" : [
{
"range" : {
"rating" : {
"from" : 2,
"to" : 4
}
}
}
]
}
}
}
/**
* https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html
*/
@Test
void filterQueryWithRange() {
int pageNumber = 0;
int pageSize = 5;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
searchSourceBuilder.fetchSource(new String[]{"id", "firstName", "lastName", "rating", "dateOfBirth"}, new String[]{""});
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.rangeQuery("rating").gte(2).lte(4));
searchSourceBuilder.query(boolQuery);
searchRequest.source(searchSourceBuilder);
searchRequest.preference("rating");
if (searchSourceBuilder.query() != null && searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
log.warn("IOException, msg={}", e.getLocalizedMessage());
e.printStackTrace();
} catch (Exception e) {
log.warn("Exception, msg={}", e.getLocalizedMessage());
e.printStackTrace();
}
}
Exists Filter
The exists and missing filters are used to find documents in which the specified field either has one or more values (exists) or doesn’t have any values (missing). It is similar in nature to IS_NULL (missing) and NOT IS_NULL (exists)in SQL.
{
"exists": {
"field": "name"
}
}
Here we are filtering out all users that have logged into the system.
GET elasticsearch_learning/_search
{
"query":{
"bool" : {
"filter" : [
{
"exists" : {
"field" : "lastLoggedInAt"
}
}
]
}
}
/**
* https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html
*/
@Test
void filterQueryWithExists() {
int pageNumber = 0;
int pageSize = 5;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
searchSourceBuilder.fetchSource(new String[]{"id", "firstName", "lastName", "rating", "dateOfBirth"}, new String[]{""});
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.filter(QueryBuilders.existsQuery("lastLoggedInAt"));
searchSourceBuilder.query(boolQuery);
searchRequest.source(searchSourceBuilder);
searchRequest.preference("rating");
if (searchSourceBuilder.query() != null && searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
log.warn("IOException, msg={}", e.getLocalizedMessage());
e.printStackTrace();
} catch (Exception e) {
log.warn("Exception, msg={}", e.getLocalizedMessage());
e.printStackTrace();
}
}
Elasticsearch Sorting
By default, search results are returned sorted by relevance, with the most relevant docs first.
Relevance Score
The relevance score of each document is represented by a positive floating-point number called the _score. The higher the _score, the more relevant the document.
A query clause generates a _score for each document. How that score is calculated depends on the type of query clause. Different query clauses are used for different purposes: a fuzzy query might determine the _score by calculating how similar the spelling of the found word is to the original search term; a terms query would incor‐ porate the percentage of terms that were found. However, what we usually mean by relevance is the algorithm that we use to calculate how similar the contents of a full- text field are to a full-text query string.
The standard similarity algorithm used in Elasticsearch is known as term frequency/ inverse document frequency, or TF/IDF, which takes the following factors into account. The more often, the more relevant. A field containing five mentions of the same term is more likely to be relevant than a field containing just one mention.
Order
Sorting allows you to add one or more sorts on specific fields. Each sort can be reversed(ascending or descending) as well. The sort is defined on a per field level, with special field name for _score to sort by score, and _doc to sort by index order.
The order option can have either asc or desc.
The order defaults to desc when sorting on the _score, and defaults to asc when sorting on anything else.
GET users/_search
{
"query" : {
"filtered" : {
"filter" : { "term" : { "id" : 1 }}
}
},
"sort": { "date": { "order": "desc" }}
}
Perhaps we want to combine the _score from a query with the date, and show all matching results sorted first by date, then by relevance.
GET /_search
{
"query" : {
"filtered" : {
"query": { "match": { "description": "student" }},
"filter" : { "term" : { "id" : 2 }}
}
},
"sort": [
{
"date": {"order":"desc"}
},
{
"_score": { "order": "desc" }
}
]
}
Order is important. Results are sorted by the first criterion first. Only results whose first sort value is identical will then be sorted by the second criterion, and so on. Multilevel sorting doesn’t have to involve the _score. You could sort by using several different fields, on geo-distance or on a custom value calculated in a script.
Elasticsearch supports sorting by array or multi-valued fields. The mode option controls what array value is picked for sorting the document it belongs to. The mode option can have the following values.
min |
Pick the lowest value. |
max |
Pick the highest value. |
sum |
Use the sum of all values as sort value. Only applicable for number based array fields. |
avg |
Use the average of all values as sort value. Only applicable for number based array fields. |
median |
Use the median of all values as sort value. Only applicable for number based array fields. |
The default sort mode in the ascending sort order is min — the lowest value is picked. The default sort mode in the descending order is max — the highest value is picked.
Note that filters have no bearing on _score, and the missing-but-implied match_all query just sets the _score to a neutral value of 1 for all documents. In other words, all documents are considered to be equally relevant.
Sorting Numeric Fields
For numeric fields it is also possible to cast the values from one type to another using the numeric_type option. This option accepts the following values: ["double", "long", "date", "date_nanos"] and can be useful for searches across multiple data streams or indices where the sort field is mapped differently.
Geo Distance Sorting
Sometimes you want to sort by how close a location is to a single point(lat/long). You can do this in elasticsearch.
GET elasticsearch_learning/_search
{
"sort":[{
"_geo_distance" : {
"addresses.location" : [
{
"lat" : 40.414897,
"lon" : -111.881186
}
],
"unit" : "m",
"distance_type" : "arc",
"order" : "desc",
"nested" : {
"path" : "addresses",
"filter" : {
"geo_distance" : {
"addresses.location" : [
-111.881186,
40.414897
],
"distance" : 1609.344,
"distance_type" : "arc",
"validation_method" : "STRICT",
"ignore_unmapped" : false,
"boost" : 1.0
}
}
},
"validation_method" : "STRICT",
"ignore_unmapped" : false
}
}]
}
/**
* https://www.elastic.co/guide/en/elasticsearch/reference/7.x/query-dsl-nested-query.html<br>
* https://www.elastic.co/guide/en/elasticsearch/reference/7.3/search-request-body.html#geo-sorting<br>
* Sort results based on how close locations are to a certain point.
*/
@Test
void sortQueryWithGeoLocation() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
searchSourceBuilder.fetchSource(new String[]{"id", "firstName", "lastName", "rating", "dateOfBirth", "addresses.street", "addresses.zipcode", "addresses.city"}, new String[]{""});
/**
* Lehi skate park: 40.414897, -111.881186<br>
* get locations/addresses close to skate park(from a radius).<br>
*/
searchSourceBuilder.sort(new GeoDistanceSortBuilder("addresses.location", 40.414897,
-111.881186).order(SortOrder.DESC)
.setNestedSort(
new NestedSortBuilder("addresses").setFilter(QueryBuilders.geoDistanceQuery("addresses.location").point(40.414897, -111.881186).distance(1, DistanceUnit.MILES))));
log.info("\n{\n\"sort\":{}\n}", searchSourceBuilder.sorts().toString());
searchRequest.source(searchSourceBuilder);
searchRequest.preference("nested-address");
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("hits={}, isTimedOut={}, totalShards={}, totalHits={}", searchResponse.getHits().getHits().length, searchResponse.isTimedOut(), searchResponse.getTotalShards(),
searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
log.warn("IOException, msg={}", e.getLocalizedMessage());
e.printStackTrace();
} catch (Exception e) {
log.warn("Exception, msg={}", e.getLocalizedMessage());
e.printStackTrace();
}
}
Query with explain
Adding explain produces a lot of output for every hit, which can look overwhelming, but it is worth taking the time to understand what it all means. Don’t worry if it doesn’t all make sense now; you can refer to this section when you need it. We’ll work through the output for one hit bit by bit.
GET users/_search?explain
{
"query" :{"match":{"description":"student"}} }
}
Producing the explain output is expensive. It is a debugging tool only. Don’t leave it turned on in production.
Fielddata
To make sorting efficient, Elasticsearch loads all the values for the field that you want to sort on into memory. This is referred to as fielddata. Elasticsearch doesn’t just load the values for the documents that matched a particular query. It loads the values from every docu‐ ment in your index, regardless of the document type.
The reason that Elasticsearch loads all values into memory is that uninverting the index from disk is slow. Even though you may need the values for only a few docs for the current request, you will probably need access to the values for other docs on the next request, so it makes sense to load all the values into memory at once, and to keep them there.
All you need to know is what fielddata is, and to be aware that it can be memory hungry. We will talk about how to determine the amount of memory that fielddata is using, how to limit the amount of memory that is available to it, and how to preload fielddata to improve the user experience.
Elasticsearch Installation
Local Installation
Installing Elasticsearch on your local Mac computer. I have a Mac laptop so this local installation will be for Mac users but you can google Elasticsearch Windows installation.
I use docker and here is the docker command,
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.1.0
Once you have pulled the elasticsearch image, run the following command to start Elasticsearch
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.1.0
If you want to keep your local Elasticsearch server running at all times then run this command. Even when you turn off your computer, it will start back up when you computer comes back on.
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch -e "discovery.type=single-node" -dit --restart unless-stopped -d docker.elastic.co/elasticsearch/elasticsearch:7.1.0
To check if installation well, go to localhost:9200/_cat/nodes?v&pretty on your browser.
You should see something like this which is the status of your Elasticsearch node.
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.17.0.3 20 96 0 0.00 0.02 0.00 mdi * f3056ceb45a2
You also need to install kibana which is a UI interface that works with Elasticsearch
Docker command to pull kibana docker image
docker pull docker.elastic.co/kibana/kibana:7.1.0
Run this command to start your kibana server
docker run --link YOUR_ELASTICSEARCH_CONTAINER_NAME_OR_ID:elasticsearch -p 5601:5601 {docker-repo}:{version}
Elasticsearch Search API
You can search data in Elasticsearch by sending a get request with query string as a parameter or post a query in the message body of post request. A search query, or query, is a request for information about data in Elasticsearch data streams or indices.
GET doctor_ut/_search
{
"query": {
"match_all": {}
}
}
String indexName = Index.DOCTOR_UT.name().toLowerCase();
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("addresses.state.keyword", "UT"));
int from = 1;
int size = 1000;
searchSourceBuilder.from(from);
searchSourceBuilder.size(size);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(searchSourceBuilder);
// with sorting
// log.info("{\"query\":{}, \"sort\":{}}", searchSourceBuilder.query().toString(),
// searchSourceBuilder.sorts().toString());
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
SearchResponse searchResponse = null;
try {
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
log.info("search got response from elastic!, totalHits={}, maxScore={}, hitLength={}", searchResponse.getHits().getTotalHits().value, searchResponse.getHits().getMaxScore(),searchResponse.getHits().getHits().length);
Iterator<SearchHit> it = searchResponse.getHits().iterator();
while (it.hasNext()) {
SearchHit searchHit = it.next();
try {
// log.info(searchHit.getSourceAsString());
DoctorIndex doctorIndex = ObjectUtils.getObjectMapper().readValue(searchHit.getSourceAsString(), DoctorIndex.class);
log.info("doctorIndex={}", ObjectUtils.toJson(doctorIndex));
// ObjectUtils.getObjectMapper().writeValue(new FileOutputStream("output-2.json", true),
// doctorIndex);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
By default, the Search API returns the top 10 matching documents.
To paginate through a larger set of results, you can use the search API’s size and from parameters. The size parameter is the number of matching documents to return. The from parameter is a zero-indexed offset from the beginning of the complete result set that indicates the document you want to start with.
By default, you cannot page through more than 10,000 documents using the from and size parameters. This limit is set using the index.max_result_window index setting.
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("addresses.state.keyword", "UT"));
int from = 1;
int size = 1000;
searchSourceBuilder.from(from);
searchSourceBuilder.size(size);
GET doctor_ut/_search
{
"from": 5,
"size": 5,
"query": {
"match_all": {}
}
}
The Scroll API can be used to retrieve a large number of results from a search request.
While a search request returns a single “page” of results, the scroll API can be used to retrieve large numbers of results (or even all results) from a single search request, in much the same way as you would use a cursor on a traditional database.
Scrolling is not intended for real time user requests, but rather for processing large amounts of data, e.g. in order to reindex the contents of one data stream or index into a new data stream or index with a different configuration.
The scroll API requires a scroll ID. To get a scroll ID, submit a search API request that includes an argument for the scroll query parameter . The scroll parameter indicates how long Elasticsearch should retain the search context for the request.
The search response returns a scroll ID in the _scroll_id response body parameter. You can then use the scroll ID with the scroll API to retrieve the next batch of results for the request.
You can also use the scroll API to specify a new scroll parameter that extends or shortens the retention period for the search context.
The scroll API returns the same response body as the search API.
GET doctor_ut/_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
searchRequest.scroll(scroll);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(1000);
searchSourceBuilder.query(QueryBuilders.termQuery("addresses.state.keyword", "UT"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("search got response from elastic!, totalHits={}, maxScore={}, hitLength={}", searchResponse.getHits().getTotalHits().value, searchResponse.getHits().getMaxScore(),
searchResponse.getHits().getHits().length);
// process searchResponse
String scrollId = searchResponse.getScrollId();
SearchHit[] searchHits = searchResponse.getHits().getHits();
while (searchHits != null && searchHits.length > 0) {
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);
log.info("search got response from elastic!, totalHits={}, maxScore={}, hitLength={}", searchResponse.getHits().getTotalHits().value, searchResponse.getHits().getMaxScore(),
searchResponse.getHits().getHits().length);
// process searchResponse
scrollId = searchResponse.getScrollId();
searchHits = searchResponse.getHits().getHits();
}
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
boolean succeeded = clearScrollResponse.isSucceeded();
Full Body Search
You should use the request body search API because most parameters are passed in the HTTP request body instead of in the query string with the GET request.
Request body search not only handles the query itself, but also allows you to return highlighted snippets from your results, aggregate analytics across all results or subsets of results, and return did-you-mean suggestions, which will help guide your users to the best results quickly.
POST /_search
{
"from": 30,
"size": 10
}
Multiple Query Clauses
Query clauses are simple building blocks that can be combined with each other to create complex queries.
{
"bool": {
"must": { "match": { "email": "folau@gmail.com" }},
"must_not": { "match": { "name": "folau" }},
"should": { "match": { "lastName": "kaveinga" }}
} }
It is important to note that a compound clause can combine any other query clauses, including other compound clauses. This means that compound clauses can be nested within each other, allowing the expression of very complex logic.
{
"bool": {
"must": { "match": { "email": "folau@gmail.com" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "folder": "inbox" }},
"must_not": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}
Queries and Filters
A filter asks a yeso r no question of every document and is used for fields that contain exact values. For examples:
- Does the status field contain the term published?
- Is the lat_lon field within 10km of a specified point?
The goal of filters is to reduce the number of documents that have to be examined by the query.
A query is similar to a filter, but also asks the question: How well does this document match?
- Best matching the words full text search
- Containing the word run, but maybe also matching runs, running, jog, or sprint
A query calculates how relevant each document is to the query, and assigns it a relevance _score, which is later used to sort matching documents by relevance. This concept of relevance is well suited to full-text search, where there is seldom a completely “correct” answer.
Queries have to not only find matching documents, but also calculate how relevant each document is, which typically makes queries heavier than filters. Also, query results are not cachable.
The match_all query simply matches all documents. It is the default query that is used if no query has been specified. It returns all rows and columns.
{
"match_all": {}
}
The match query should be the standard query that you reach for whenever you want to query for a full-text or exact value in almost any field.
If you run a match query against a full-text field, it will analyze the query string by using the correct analyzer for that field before executing the search
{
"match": {
"email": "folau"
}
}
If you use it on a field containing an exact value, such as a number, a date, a Boolean, or a not_analyzed string field, then it will search for that exact value
Note that for exact-value searches, you probably want to use a filter instead of a query, as a filter will be cached.
The match query does not use a query syntax like +user_id:2 +tweet:search. It just looks for the words that are specified. This means that it is safe to expose to your users via a search field; you control what fields they can query, and it is not prone to throwing syntax errors.
match_phrase query analyzes the text and creates a phrase query out of the analyzed text.
@Test
void searchWithMatchPhrase() {
String description = "His biggest fear";
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* match query is like contain in mysql
*/
searchSourceBuilder.query(QueryBuilders.matchPhraseQuery("description", description));
searchRequest.source(searchSourceBuilder);
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("totalShards={}, totalHits={}", searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
multi_match query builds on the match query to allow multi-field queries. Use * to query against all fields. Note that * will not query against nested fields.
{
"multi_match": {
"query": "full text search",
"fields": ["title","body"]
}
}
@Test
void searchWithMultiMatchAllFields() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* match query is like contain in mysql<br>
* * means all fields<br>
* Isabell - firstName of a diff user <br>
* 3102060312 - phoneNumber of a diff user<br>
* biggest fear - description of a diff user<br>
*/
//searchSourceBuilder.query(QueryBuilders.multiMatchQuery("Isabell 3102060312 biggest fear", "*"));
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("Best Buy", "*"));
searchRequest.source(searchSourceBuilder);
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("totalShards={}, totalHits={}", searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
You can use the term query to find documents based on a precise value such as a price, a product ID, or a username.
To better search text fields, the match query also analyzes your provided search term before performing a search. This means the match query can search text fields for analyzed tokens rather than an exact term.
The term query does not analyze the search term. The term query only searches for the exact term you provide. This means the term query may return poor or no results when searching text fields.
@Test
void searchWithTerm() {
String firstName = "Isabell";
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* term query looks for exact match. Use keyword
*/
searchSourceBuilder.query(QueryBuilders.termQuery("firstName.keyword", firstName));
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Test
void searchWithTermAndMultiValues() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* term query looks for exact match. Use keyword
*/
searchSourceBuilder.query(QueryBuilders.termsQuery("firstName.keyword", "Leland","Harmony","Isabell"));
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Return documents that has a value for a field.
GET elasticsearch_learning/_search
{
"query":{
"exists" : {
"field" : "firstName",
"boost" : 1.0
}
}
}
@Test
void searchWithExistQuery() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* term query looks for exact match. Use keyword
*/
searchSourceBuilder.query(QueryBuilders.existsQuery("firstName"));
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Returns documents that have terms matching a wildcard pattern.
GET elasticsearch_learning/_search
{
"query":{
"wildcard" : {
"firstName" : {
"wildcard" : "H*y",
"boost" : 1.0
}
}
}
}
@Test
void searchWithWildcardQuery() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
/**
* Filter<br>
* term query looks for exact match. Use keyword<br>
* These matching terms can include Honey, Henny, or Horsey.<br>
*/
searchSourceBuilder.query(QueryBuilders.wildcardQuery("firstName", "H*y"));
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Returns documents that contain terms matching a regular expression.
The performance of the regexp query can vary based on the regular expression provided. To improve performance, avoid using wildcard patterns, such as .* or .*?+, without a prefix or suffix.
GET elasticsearch_learning/_search
{
"query":{
"regexp" : {
"firstName" : {
"value" : "S.e",
"flags_value" : 255,
"case_insensitive" : true,
"max_determinized_states" : 10000,
"boost" : 1.0
}
}
}
}
/**
* https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html<br>
* https://www.elastic.co/guide/en/elasticsearch/reference/current/regexp-syntax.html
*/
@Test
void searchWithRegexQuery() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName","description"}, new String[]{""});
/**
* Query<br>
* Sydnee<br>
* . means match any character.<br>
* * Repeat the preceding character zero or more times.<br>
*/
searchSourceBuilder.query(QueryBuilders.regexpQuery("firstName", "S.*e")
.flags(RegexpQueryBuilder.DEFAULT_FLAGS_VALUE)
.caseInsensitive(true));
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
The bool query, like the bool filter, is used to combine multiple query clauses. However, there are some differences. Remember that while filters give binary yes/no answers, queries calculate a relevance score instead. The bool query combines the _score from each must or should clause that matches. This query accepts the following parameters:
must
Clauses that must match for the document to be included.
must_not
Clauses that must not match for the document to be included.
should
If these clauses match, they increase the _score; otherwise, they have no effect. They are simply used to refine the relevance score for each document.
The bool query takes a more-matches-is-better approach, so the score from each matching must or should clause will be added together to provide the final _score for each document.
The following query finds documents whose title field matches the query string how to make millions and that are not marked as spam. If any documents are starred or are from 2014 onward, they will rank higher than they would have otherwise. Documents that match both conditions will rank even higher.
GET elasticsearch_learning/_search
{
"query":{
"bool" : {
"must" : [
{
"match" : {
"firstName" : {
"query" : "Leland",
"operator" : "OR",
"prefix_length" : 0,
"max_expansions" : 50,
"fuzzy_transpositions" : true,
"lenient" : false,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"boost" : 1.0
}
}
}
],
"filter" : [
{
"match" : {
"firstName" : {
"query" : "Leland",
"operator" : "OR",
"prefix_length" : 0,
"max_expansions" : 50,
"fuzzy_transpositions" : true,
"lenient" : false,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"boost" : 1.0
}
}
}
],
"must_not" : [
{
"match" : {
"firstName" : {
"query" : "Leilani",
"operator" : "OR",
"prefix_length" : 0,
"max_expansions" : 50,
"fuzzy_transpositions" : true,
"lenient" : false,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"boost" : 1.0
}
}
}
],
"should" : [
{
"match" : {
"firstName" : {
"query" : "Lelanddd",
"operator" : "OR",
"prefix_length" : 0,
"max_expansions" : 50,
"fuzzy_transpositions" : true,
"lenient" : false,
"zero_terms_query" : "NONE",
"auto_generate_synonyms_phrase_query" : true,
"boost" : 1.0
}
}
}
],
"adjust_pure_negative" : true,
"boost" : 1.0
}
}
}
@Test
void searchWithBooleanQuery() {
int pageNumber = 0;
int pageSize = 10;
SearchRequest searchRequest = new SearchRequest(database);
searchRequest.allowPartialSearchResults(true);
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNumber * pageSize);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
/**
* fetch only a few fields
*/
// searchSourceBuilder.fetchSource(new String[]{ "id", "firstName", "lastName", "cards" }, new String[]{""});
/**
* Query
*/
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
/**
* Filter<br>
* term query looks for exact match. Use keyword
*/
boolQuery.must(QueryBuilders.matchQuery("firstName", "Leland"));
boolQuery.mustNot(QueryBuilders.matchQuery("firstName", "Leilani"));
boolQuery.should(QueryBuilders.matchQuery("firstName", "Lelanddd"));
boolQuery.filter(QueryBuilders.matchQuery("firstName", "Leland"));
searchSourceBuilder.query(boolQuery);
searchRequest.source(searchSourceBuilder);
searchRequest.preference("firstName");
if (searchSourceBuilder.sorts() != null && searchSourceBuilder.sorts().size() > 0) {
log.info("\n{\n\"query\":{}, \"sort\":{}\n}", searchSourceBuilder.query().toString(), searchSourceBuilder.sorts().toString());
} else {
log.info("\n{\n\"query\":{}\n}", searchSourceBuilder.query().toString());
}
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("isTimedOut={}, totalShards={}, totalHits={}", searchResponse.isTimedOut(), searchResponse.getTotalShards(), searchResponse.getHits().getTotalHits().value);
List<User> users = getResponseResult(searchResponse.getHits());
log.info("results={}", ObjectUtils.toJson(users));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Note that if there are no must clauses, at least one should clause has to match. However, if there is at least one must clause, no should clauses are required to match.
Combine Queries with Filters
Use bool query to combine query and filter.
How a query works under the hood
Let’s assume you have 3 nodes.
#Query Phase
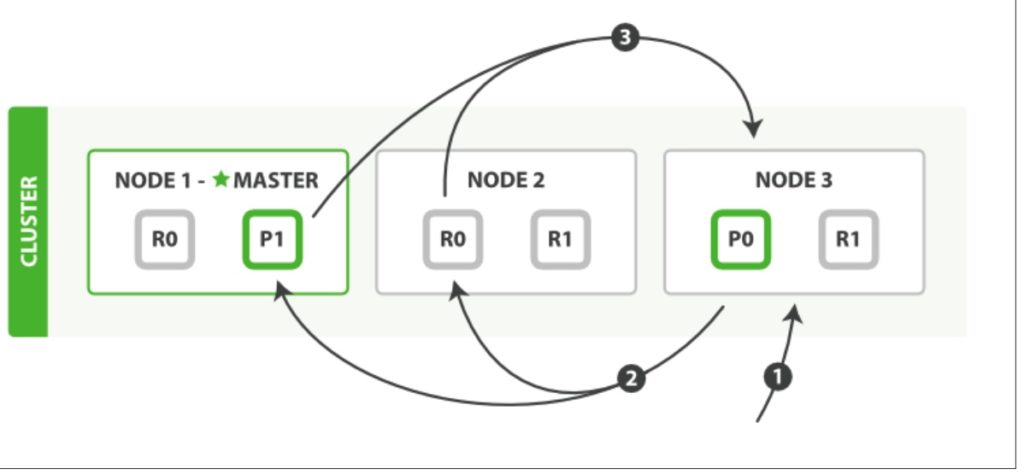
- The client sends a search request to Node 3, which creates an empty priority queue of size from + size.
- Node 3 forwards the search request to a primary or replica copy of every shard in the index. Each shard executes the query locally and adds the results into a local sorted priority queue of size from + size.
- Each shard returns the doc IDs and sort values of all the docs in its priority queue to the coordinating node, Node 3, which merges these values into its own priority queue to produce a globally sorted list of results.
When a search request is sent to a node, that node becomes the coordinating node. It is the job of this node to broadcast the search request to all involved shards, and to gather their responses into a globally sorted result set that it can return to the client.
The first step is to broadcast the request to a shard copy of every node in the index. Just like document GET requests, search requests can be handled by a primary shard or by any of its replicas. This is how more replicas (when combined with more hard‐ ware) can increase search throughput. A coordinating node will round-robin through all shard copies on subsequent requests in order to spread the load.
Each shard executes the query locally and builds a sorted priority queue of length from + size—in other words, enough results to satisfy the global search request all by itself. It returns a lightweight list of results to the coordinating node, which con‐ tains just the doc IDs and any values required for sorting, such as the _score.
The coordinating node merges these shard-level results into its own sorted priority queue, which represents the globally sorted result set. Here the query phase ends.
An index can consist of one or more primary shards, so a search request against a single index needs to be able to combine the results from multiple shards. A search against multiple or all indi‐ ces works in exactly the same way—there are just more shards involved.
#Fetch Phase
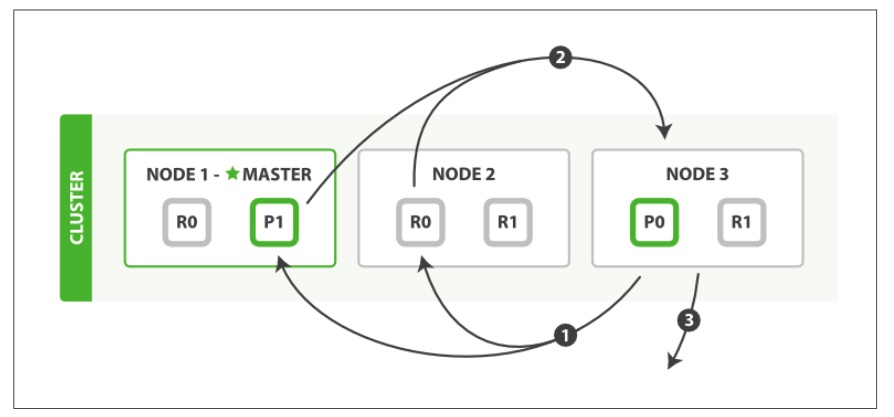
- The coordinating node identifies which documents need to be fetched and issues a multi GET request to the relevant shards.
- Each shard loads the documents and enriches them, if required, and then returns the documents to the coordinating node.
- Once all documents have been fetched, the coordinating node returns the results to the client.
The coordinating node first decides which documents actually need to be fetched. For instance, if our query specified { “from”: 90, “size”: 10 }, the first 90 results would be discarded and only the next 10 results would need to be retrieved. These documents may come from one, some, or all of the shards involved in the original search request.
The coordinating node builds a multi-get request for each shard that holds a perti‐ nent document and sends the request to the same shard copy that handled the query phase.
The shard loads the document bodies—the _source field—and, if requested, enriches the results with metadata and search snippet highlighting. Once the coordinating node receives all results, it assembles them into a single response that it returns to the client.
Bouncing Result
Imagine that you are sorting your results by a timestamp field, and two documents have the same timestamp. Because search requests are round-robined between all available shard copies, these two documents may be returned in one order when the request is served by the primary, and in another order when served by the replica. This is known as the bouncing results problem: every time the user refreshes the page, the results appear in a different order. The problem can be avoided by always using the same shards for the same user, which can be done by setting the preference parameter to an arbitrary string like the user’s session ID.
Elasticsearch CAT API
Usually the results from various Elasticsearch APIs are displayed in JSON format. But JSON is not easy to read always. So CAT APIs feature is available in Elasticsearch helps in taking care of giving an easier to read and comprehend printing format of the results. There are various parameters used in cat API which serve different purpose, for example – the term V makes the output verbose.
Show indices
Show each index and their details
GET /_cat/indices?v
Show nodes
The nodes command shows the cluster topology
GET /_cat/nodes?h=ip,port,heapPercent,name
Show health
Show health status of each index
GET /_cat/health?v
Show plugins
The plugins command provides a view per node of running plugins.
GET /_cat/plugins?v&s=component&h=name,component,version,description
Th count provides quick access to the document count of the entire cluster, or individual indices.
GET /_cat/count/<target> //v, the response includes column headings. Defaults to false. GET /_cat/count/users?v