MySQL Date TypesMySQL LAST_INSERT_IDMySQL InsertMySQL SelectMySQL WhereMySQL Group ByMySQL Order ByMySQL LimitMySQL LikeMySQL ISNULLMySQL BetweenMySQL JoinMySQL Left JoinMySQL Right JoinMySQL Cross JoinMySQL Self JoinMySQL Sub QueryMySQL UpdateMySQL DeleteMySQL ExplainMySQL IfMySQL Full-Text SearchMySQL INFORMATION_SCHEMAMySQL ConnectionMySQL Server Helpful FunctionsMySQL ViewMySQL Stored ProcedureMySQL FunctionsMySQL TransactionMySQL TriggerMySQL EventMySQL DeadlockMySQL DumpMySQL Reset Root PasswordMySQL interview – Advanced QueriesMySQL JsonMySQL BinlogMySQL Closure Table
SQL Table of Content
MySQL Fundamentals
MySQL Data Types
MySQL Insert/Create
MySQL LAST_INSERT_ID
MySQL Select
MySQL Where
MySQL Group By and Having
MySQL Order By
MySQL Limit
MySQL Like
MySQL ISNULL
MySQL Between
MySQL Join/Inner Join
MySQL Left JOIN
MySQL Right JOIN
MySQL Cross JOIN
MySQL Self Join
MySQL Sub Query
MySQL Update
MySQL Delete
MySQL Explain
MySQL If
MySQL Full-Text Search
MySQL Information Schema
MySQL Connection
MySQL Server Useful Functions
MySQL View
MySQL Stored Procedure
MySQL Functions
MySQL Transaction
MySQL Trigger
MySQL Event
MySQL Index
MySQL Deadlock
MySQL Dump
MySQL Reset Root Password
MySQL JSON
Run Query in Production
MySQL Binlog
Interview Questions
Fundamentals
Advanced Queries
Advanced Techniques
MySQL Run Query in Production
When running queries in your production environment, you have to be careful so you don’t bring it down or make a mistake that will cause your environment to act abnormally.
Here are some things you need to be careful about:
Run query with READ UNCOMMITTED option
The MySQL READ UNCOMMITTED, also known as “dirty read” because it is the lowest level of isolation. If we specify a table hint then it will override the current default isolation level. MySQL default isolation level is REPEATABLE READ which means locks will be placed for each operation, but multiple connections can read data concurrently.
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; SELECT * FROM TABLE_NAME ; SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ ;
Run query against a backup table first
Do everything you can to run query againts dev, qa, or backup database before running your query against a production database. And when you do run your query against your production database, make sure to do it first against backup tables and then the actual tables. A lot of times you will find that as a safety net in case you make a mistake on first try, you will be safe as that would be against the backup and not the actual live data. Once everything looks good in the backup tables then you can run your query against the actual live data.
Make sure dev database server is the same(version) as the production server
Make sure that when running queries that your dev database server has the same version as your production database server. If they have to be in different versions the production server must be in higher version than the dev server. In most cases where the version is not the same the dev server is in higher version so be careful about that. The reason for this check is that you may have a query that works in dev and won’t work in production because the query uses functions that the production server does not support. For example. JSON_ARRAYAGG is not in mysql version 5.7. My dev server was in mysql 8 and production server was in 5.7. Not until release day that I realized my database migration was not going to work in production and had to pull it back.
Avoid running migration insert/update scripts during operational hours.
If possible, run insert/update migration scripts during slow or off hours. There is a good chance you will run into issues especially with updating data based on existing data in the database. You might not be reading live data to perform updates as users are using and updating your data.
Always have someone else take a second look at your query
You can never go wrong with having help and verifying your query is doing what is intended to do. In most cases, you work in a team, you should have a team member or your team lead look at your query to make sure it’s doing what is intended to do. You can’t take a risk of running a query that may change thousands of records without having someone else review it.
MySQL Json
MySQL supports the native JSON data type since version 5.7.8. The native JSON data type allows you to store JSON documents more efficiently than the JSON text format in the previous versions.
MySQL stores JSON documents in an internal format that allows quick read access to document elements. The JSON binary format is structured in the way that permits the server to search for values within the JSON document directly by key or array index, which is very fast.
The storage of a JSON document is approximately the same as the storage of LONGBLOB or LONGTEXT data.
CREATE TABLE events (
...
browser_info JSON,
...
);
Insert into json column
INSERT INTO events(browser_info)
VALUES (
'{ "name": "Safari", "os": "Mac", "resolution": { "x": 1920, "y": 1080 } }'
)
Automatic validation of JSON documents stored in JSON columns. Invalid documents produce an error.
Evaluates a (possibly empty) list of key-value pairs and returns a JSON object containing those pairs. An error occurs if any key name is NULL or the number of arguments is odd.
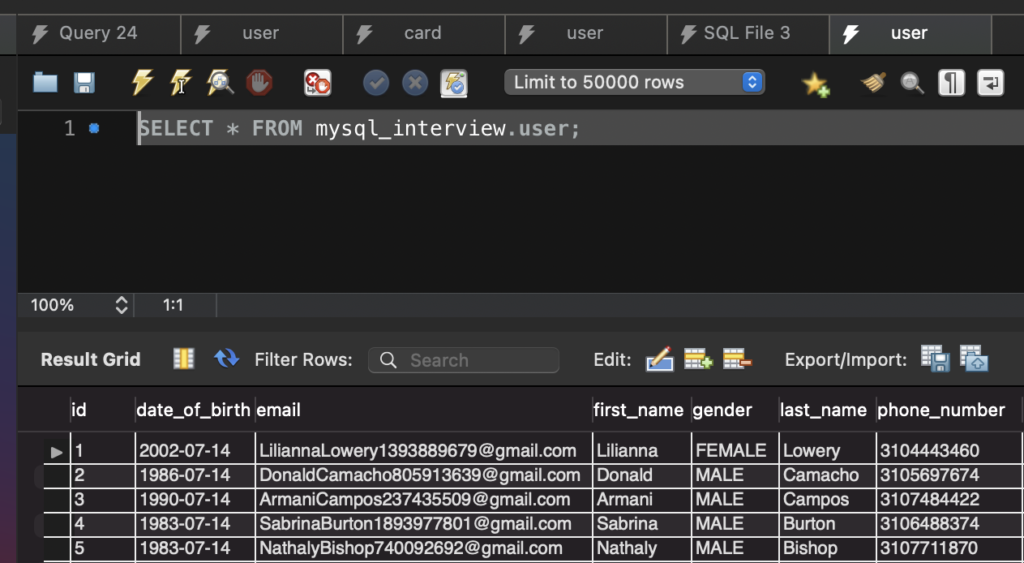
SELECT JSON_OBJECT('id',u.id,
'firstName',u.first_name,
'lastName',u.first_name) as jsonUser
FROM user as u;
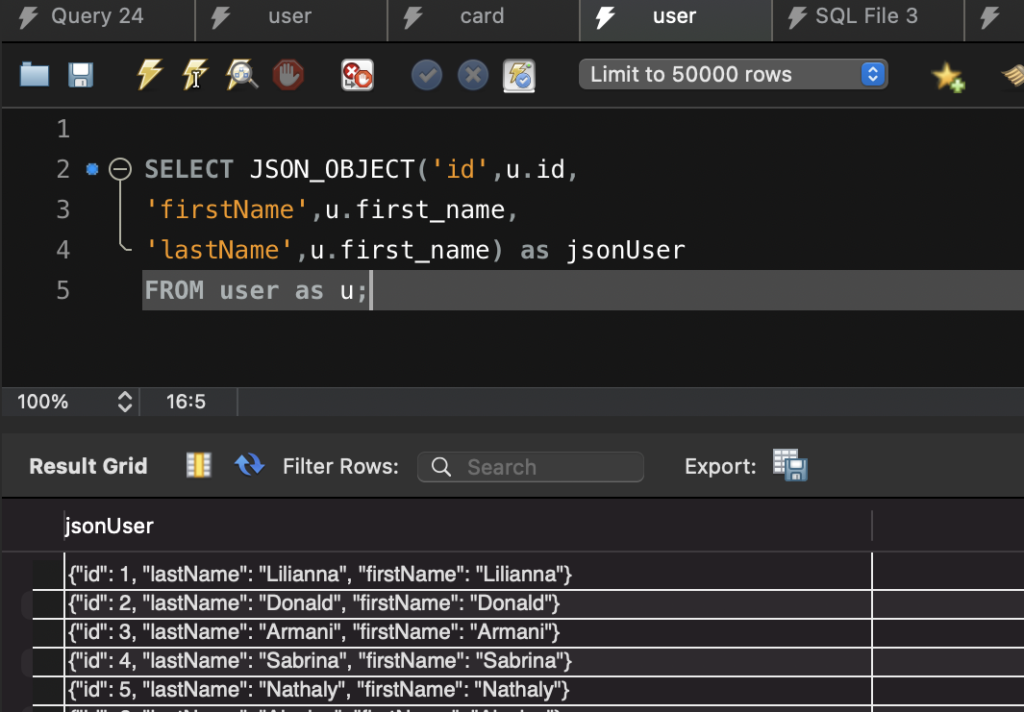
Evaluates a (possibly empty) list of values and returns a JSON array containing those values.
SELECT JSON_ARRAY(u.id, u.first_name, u.first_name) as jsonUser FROM user as u;
Json Object Agg
Return result set as a single JSON object
Takes two column names or expressions as arguments, the first of these being used as a key and the second as a value, and returns a JSON object containing key-value pairs. Returns NULL if the result contains no rows, or in the event of an error. An error occurs if any key name is NULL or the number of arguments is not equal to 2.
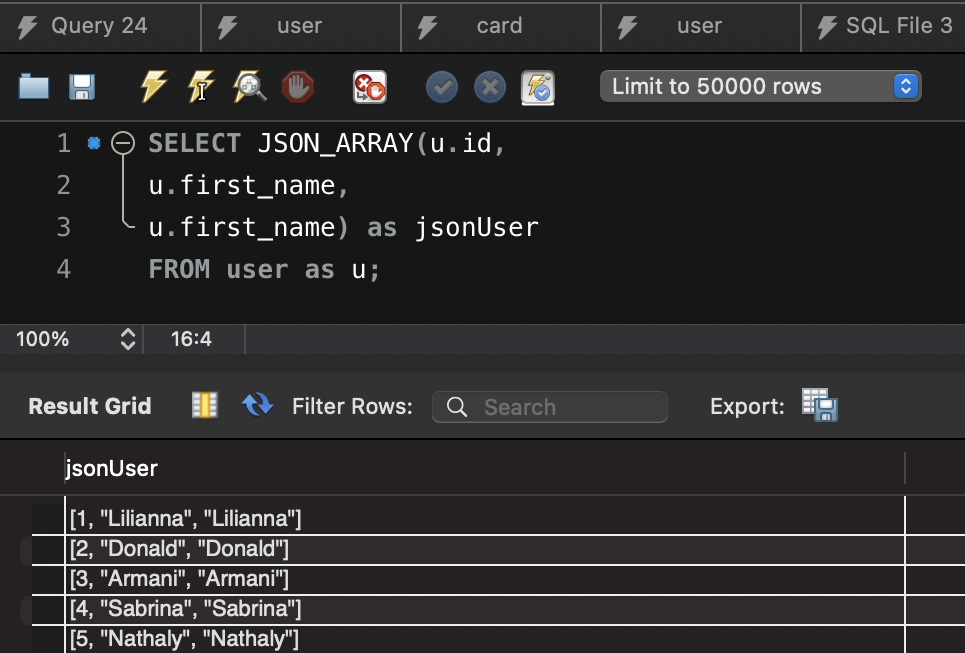
SELECT JSON_OBJECTAGG(u.id, u.firstName, u.lastName) as jsonData
FROM user as u;
// output
{
"id": 1,
"firstName": "John",
"lastName": "Peter"
}
Return result set as a single JSON array
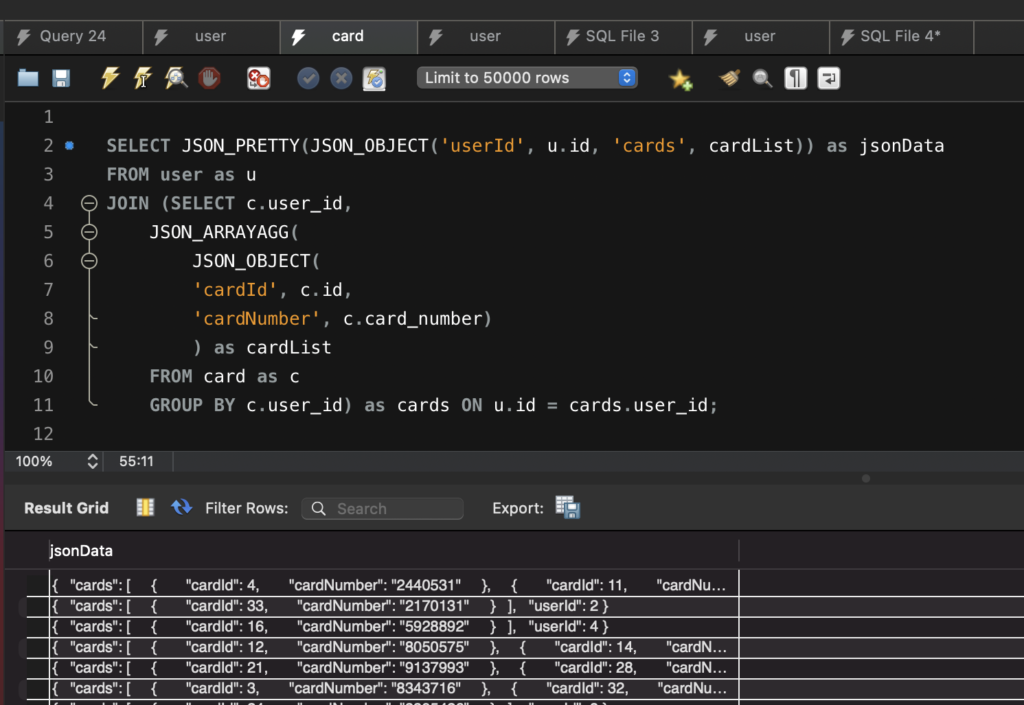
Aggregates a result set as a single JSON array whose elements consist of the rows. The order of elements in this array is undefined. The function acts on a column or an expression that evaluates to a single value. Returns NULL if the result contains no rows, or in the event of an error.
SELECT JSON_PRETTY(JSON_OBJECT('userId', u.id, 'cards', cardList)) as jsonData
FROM user as u
LEFT JOIN (SELECT c.user_id,
JSON_ARRAYAGG(
JSON_OBJECT(
'cardId', c.id,
'cardNumber', c.card_number)
) as cardList
FROM card as c
GROUP BY c.user_id) as cards ON u.id = cards.user_id;
{
"cards": [
{
"cardId": 4,
"cardNumber": "2440531"
},
{
"cardId": 11,
"cardNumber": "4061190"
}
],
"userId": 1
}
How to accomplish JSON_ARRAYAGG before version 5.7.8
SELECT JSON_PRETTY(JSON_OBJECT('userId', u.id, 'cards', cardList)) as jsonData
FROM user as u
LEFT JOIN (SELECT c.user_id,
CONCAT('[', GROUP_CONCAT(
JSON_OBJECT(
'cardId', c.id,
'cardNumber', c.card_number)
), ']') as cardList
FROM card as c
GROUP BY c.user_id) as cards ON u.id = cards.user_id;
Provides pretty-printing of JSON values similar to that implemented in PHP and by other languages and database systems. The value supplied must be a JSON value or a valid string representation of a JSON value.
SELECT JSON_PRETTY(JSON_OBJECT('id',u.id,
'firstName',u.first_name,
'lastName',u.first_name)) as jsonUser
FROM user as u;
json_extract(json_doc, path[, path] ...)
Returns data from a JSON document, selected from the parts of the document matched by the path arguments. Returns NULL if any argument is NULL or no paths locate a value in the document. An error occurs if the json_doc argument is not a valid JSON document or any path argument is not a valid path expression.
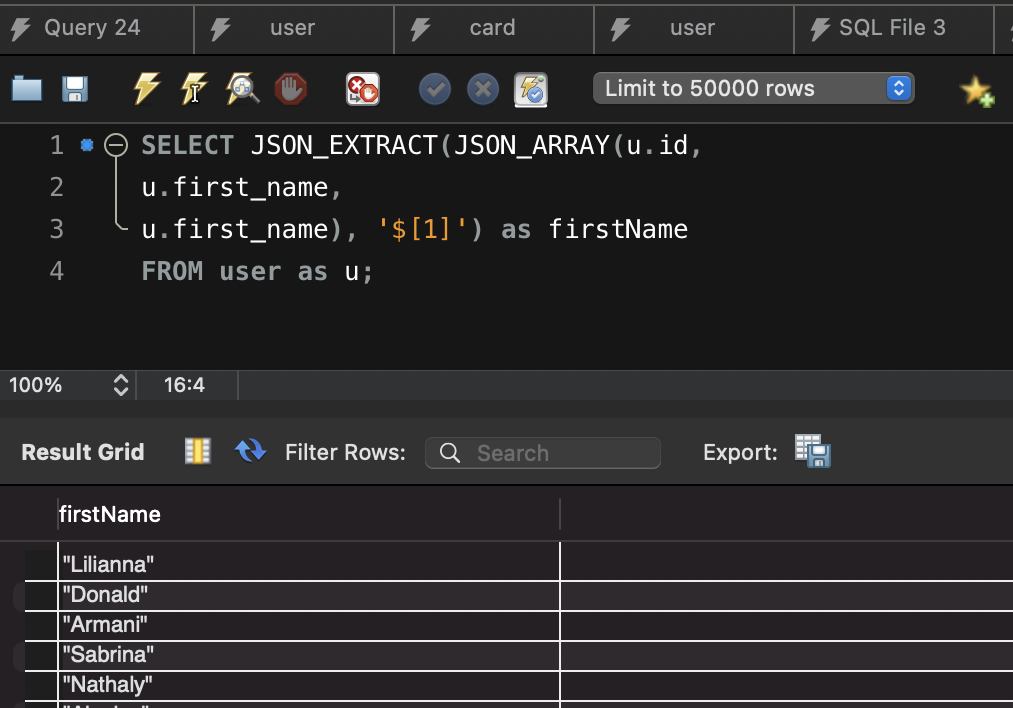
MySQL Trigger
A MySQL trigger is a stored program that is invoked automatically in response to an event such as INSERT, UPDATE, or DELETE to a particualar table.
There are two types of triggers
- Row-level trigger: a row-level trigger is activated for each row that is inserted, updated, or deleted.
- Statement-level trigger: a statement-level trigger is executed once for each transaction regardless of how many rows are inserted, updated, or deleted. MySQL supports only row-level triggers. It doesn’t support statement-level triggers.
Advantages of triggers
- Triggers provide another way to check the integrity of data
- Triggers handle errors from the database layer
- Triggers are another way to run cron jobs.
- Triggers can be useful for auditing the data changes in tables.
Disadvantages of triggers
- Triggers can only use extended validations but not all validations. You can use NOT NULL, UNIQUE, CHECK, and FOREIGN KEY contraints.
- Triggers can be difficult to troubleshoot because they execute automatically in the database which may not be visible to clients.
- Triggers may increase the overhead of the MySQL server.
Create a Trigger
- Specify the name of the trigger – CREATE TRIGGER trigger_name
- Specify trigger type – AFTER INSERT
- Specify the name of the table for which you want to create the trigger for – ON table_name
- Specify the trigger body that will run every the trigger is invoked.
DELIMITER $$
CREATE TRIGGER trigger_name
AFTER INSERT
ON table_name FOR EACH ROW
BEGIN
-- statements
-- variable declarations
-- trigger code
END$$
DELIMITER ;
Example
DELIMITER $$
CREATE TRIGGER after_members_insert
AFTER INSERT
ON members FOR EACH ROW
BEGIN
IF NEW.birthDate IS NULL THEN
INSERT INTO reminders(memberId, message)
VALUES(new.id,CONCAT('Hi ', NEW.name, ', please update your date of birth.'));
END IF;
END$$
DELIMITER ;
Triggers only run for the new, updated, or deleted rows. They don’t touch those rows that didn’t get updated.
Show triggers
SHOW TRIGGERS;
SHOW TRIGGERS
[{FROM | IN} database_name]
[LIKE 'pattern' | WHERE search_condition];
SHOW TRIGGERS; -- return all triggers in all databases
SHOW TRIGGERS FROM database_name; -- show triggers from database_name
The only way to edit a trigger is by dropping and recreating it.
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name;
December 9, 2020
MySQL Dump
Most of the times, you want to backup your databases to have backups to prevent loosing data. If you don’t backup your databases, a code bug or a server/disk failure could be a disaster. To help save you lots of time and frustration, it is strongly recommended that you take the precaution of regularly backing up your MySQL databases. You use mysqldump to back up your databases.
shell> mysqldump [options] > backup.sql
options – mysqldump options
backup.sql – the back up file
If the database size is very large it is a good idea to compress the output. To do that simply pipe the output to the gzip utility, and redirect it to a file as shown below:
mysqldump -u - root -p database_name | gzip > database_name.sql.gz
Authentication with username, password, and host
To get into the server, you must have the username and password for authentication. You use the -u for username and -p for password. By default –host is localhost so you can omit it when working with your localhost. Make sure you specify your host uri when you are not pointing to your localhost.
mysqldump -u username -p --host localhost database_name > backup.sql
You can even specify the username and password like this
mysqldump -uusername -ppassword -hlocalhost database_name > backup.sql
Dump all databases
To dump entire databases, do not name any tables following db_name, or use the --databases or --all-databases option.
mysqldump -u root -p --all-databases > all_databases.sql
Dump a single database
To backup a single MySQL database with one command you need to use the --databases option followed by the name of the database. You can also omit the –database option which is a more common way of doing this. Note that by using the --databases option, you will have the CREATE DATABASE command which is useful on restoring.
mysqldump -u root -p database_name > backup.sql mysqldump -u root -p --databases database_name > backup.sql
Dump a single database with a timestamp
If you want to keep more than one backup in the same location, then you can add the current date to the backup filename:
mysqldump database_name > database_name-$(date +%Y%m%d).sql
Dump multiple databases
To backup multiple MySQL databases with one command you need to use the --database option followed by the list of databases you want to backup. Each database name must be separated by space. mysqldump treats the first name argument on the command line as a database name and following names as table names. With this option, it treats all name arguments as database names.
mysqldump -u root -p --databases database_name_a database_name_b > backup_a_b.sql
Dump only some tables within a database
If you use the –databases then you have to use the –tables option to specify the tables.
mysqldump -u username -p database_name table_name1 table_name2 > backup.sql // if --databases option is specified mysqldump -u username -p --databases database_name --tables table_name1 table_name2 > backup.sql
Dump only some table rows within a database table
The –where option is applied to all tables not just one. There is only one –where option. You might be thinking to use the –where option for each table but that does not work. In case you configure this command with multiple –where options, only the last –where option will be evaluated.
mysqldump -u username -p database_name table_name --where="id<=100" > few_rows_backup.sql
Dump with store procedures
mysqldump will backup by default all the triggers but NOT the stored procedures/functions. There are 2 mysqldump parameters that control this behavior:
--routines– FALSE by default--triggers– TRUE by default
so in mysqldump command , add --routines. Include triggers for each dumped table in the output. This option is enabled by default; disable it with --skip-triggers. --routines includes stored routines (procedures and functions) for the dumped databases in the output. This option requires the global SELECT privilege.
mysqldump -u root -p --triggers --routines --databases database_name > backup.sql
Create a cron job to backup a database on your mac
- Type crontab -e on your terminal to open your cron jobs
- Add a crontab command
-
* * * * * command to execute │ │ │ │ │ │ │ │ │ └─── day of week (0 - 6) (0 to 6 are Sunday to Saturday, or use names; 7 is Sunday, the same as 0) │ │ │ └──────── month (1 - 12) │ │ └───────────── day of month (1 - 31) │ └────────────────── hour (0 - 23) └─────────────────────── min (0 - 59)
-
0 * * * * /usr/local/mysql/bin/mysqldump -u root database_name > {location}/database_name-$(date +"%Y%m%d").sqlCommand to execute is the dump command which, in this case, is run every hour.
- Delete file over 30 days old
0 * * * * /Users/folaukaveinga/db_backups -type f -name "*.sql" -mtime +30 -delete
Restore MySQL Dump
You can restore a MySQL dump using the mysql command.
mysql -u username -p database_name < backup.sql
In some cases, you need to create a database to import into because you did not use the –databases option when creating the dumb.
mysql -u root -p -e "create database database_name"; mysql -u root -p database_name < backup.sql
Restore a single database
If you backed up all your databases using the -all-databases option and you want to restore a single database from a backup file which contains multiple databases use the --one-database option.
mysql -u username -p --one-database database_name < backup.sql
Export and Import a MySQL database in one command
Instead of creating a dump file from one database and then import the backup into another MySQL database you can use the following one-liner.
mysqldump -uLocalUsername -pLocalPassword --databases local_database_name | mysql -hRemoteHost -uRemoteUsername -pRemotePassword remote_database_name
MySQL Deadlock
A deadlock is a situation where different transactions are unable to proceed because each holds a lock that the other needs. Because both transactions are waiting for a resource to become available, neither ever release the locks it holds. A deadlock can occur when transactions lock rows in multiple tables (through statements such as UPDATE or SELECT ... FOR ), but in the opposite order. A deadlock can also occur when such statements lock ranges of index records and gaps, with each transaction acquiring some locks but not others due to a timing issue.
UPDATE
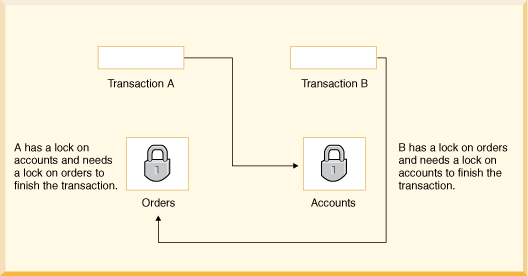
To avoid deadlock
To reduce the possibility of deadlocks, use transactions rather than LOCK TABLES statements; keep transactions that insert or update data small enough that they do not stay open for long periods of time; when different transactions update multiple tables or large ranges of rows, use the same order of operations (such as SELECT ... FOR ) in each transaction. Using both row-level locking and the TRANSACTION_READ_COMMITTED isolation level makes it likely that you will avoid deadlocks (both settings are Derby defaults). However, deadlocks are still possible.
UPDATE
Minimize and handle deadlocks
Deadlocks are a classic problem in transactional databases, but they are not dangerous unless they are so frequent that you cannot run certain transactions at all. Normally, you must write your applications so that they are always prepared to re-issue a transaction if it gets rolled back because of a deadlock.
InnoDB uses automatic row-level locking. You can get deadlocks even in the case of transactions that just insert or delete a single row. That is because these operations are not really “atomic”; they automatically set locks on the (possibly several) index records of the row inserted or deleted.
Keep transactions small and short in duration to make them less prone to collision.
Commit transactions immediately after making a set of related changes to make them less prone to collision. In particular, do not leave an interactive mysql session open for a long time with an uncommitted transaction.
When modifying multiple tables within a transaction, or different sets of rows in the same table, do those operations in a consistent order each time. Then transactions form well-defined queues and do not deadlock. For example, organize database operations into functions within your application, or call stored routines, rather than coding multiple similar sequences of INSERT, UPDATE, and DELETE statements in different places.
Deadlock detection
When a transaction waits more than a specific amount of time to obtain a lock (called the deadlock timeout), Derby can detect whether the transaction is involved in a deadlock.
When you configure your system for deadlock and lockwait timeouts and an application could be chosen as a victim when the transaction times out, you should program your application to handle them.
Run this command to show the latest deadlock
SHOW ENGINE INNODB STATUS ;