System Design Table of Content
System Design – Interview Questions
- What is the purpose of software system design?
Software system design aims to transform user requirements into a well-organized and structured solution by defining system architecture, modules, interfaces, and other components. - Explain the difference between monolithic and microservices architectures.
Monolithic architecture is a single, tightly integrated application, while microservices use small, independent services communicating through APIs. Example: Monolithic – A traditional web application; Microservices – Netflix architecture. - How do you decide between a relational database and a NoSQL database for a specific application?
Use a relational database when data consistency and strong ACID properties are crucial. Use NoSQL databases when scalability and flexible schema are required. Example: Relational – Banking application; NoSQL – Real-time analytics platform. - What is the role of load balancing in a distributed system?
Load balancing distributes incoming network traffic across multiple servers to ensure optimal resource utilization and prevent overload on any single server. Example: Nginx for distributing web traffic across application servers. - How can you ensure data security in a distributed system?
Implement encryption, authentication, and authorization mechanisms, use secure communication protocols (e.g., HTTPS), and regularly update security patches. Example: Using SSL/TLS for securing data transmission in a distributed e-commerce system. - Explain the concept of caching and its significance in software system design.
Caching stores frequently accessed data in a temporary storage, reducing the need to fetch the same data repeatedly from the original source, which improves system performance. Example: Caching frequently accessed database query results in a web application. - Describe the “Database Sharding” technique and when it’s useful.
Database sharding involves horizontally partitioning data across multiple databases to handle large datasets and improve scalability. It’s useful when a single database becomes a performance bottleneck. Example: Sharding user data based on geographical regions in a global social media platform. - What are design patterns, and how do they benefit software system design?
Design patterns are reusable solutions to common software design problems. They enhance system maintainability, scalability, and code quality. Example: Singleton pattern to ensure only one instance of a class exists. - Explain the role of an API gateway in a microservices architecture.
An API gateway acts as a single entry point for client requests, routing them to appropriate microservices. It handles tasks like authentication, rate limiting, and request/response transformations. Example: Netflix Zuul as an API gateway for their microservices. - What is event-driven architecture, and why is it popular in modern systems?
Event-driven architecture enables communication between components through events, facilitating loose coupling and scalability. It is popular because it enables real-time processing, responsiveness, and adaptability. Example: Using Apache Kafka for real-time data streaming and processing in a financial trading platform. - How can you ensure high availability in a distributed system?
Ensure redundancy through replication, utilize load balancing, implement failover mechanisms, and design for fault tolerance. Example: Using a distributed database with replication across multiple data centers for high availability. - Discuss the pros and cons of a RESTful API compared to a GraphQL API.
RESTful API pros: Simplicity, standardized, statelessness. Cons: Over-fetching, under-fetching. GraphQL pros: Flexibility, efficient data retrieval. Cons: Complexity. Example: RESTful API for a basic CRUD application; GraphQL API for a data-intensive application with complex data needs. - What are the key considerations when designing a scalable system?
Vertical and horizontal scaling, load balancing, caching, statelessness, and sharding. Example: Designing a scalable e-commerce platform that can handle an increasing number of users and transactions. - Explain the role of Docker in software system design and deployment.
Docker facilitates containerization, allowing applications to run consistently across different environments and simplifying deployment and scaling processes. Example: Dockerizing a web application to ensure it runs the same way in development, testing, and production environments. - How can you optimize the performance of a database query?
Optimize database indexes, minimize database joins, use database caching, and denormalize data when necessary. Example: Adding indexes to frequently queried columns in a relational database. - Describe the principles of the SOLID design principles.
SOLID stands for Single Responsibility Principle, Open/Closed Principle, Liskov Substitution Principle, Interface Segregation Principle, and Dependency Inversion Principle. These principles enhance code maintainability, extensibility, and readability. Example: Following the Single Responsibility Principle by separating UI logic from business logic in an application. - How can you ensure data consistency in a distributed system?
Use distributed transactions or implement eventual consistency through mechanisms like CRDTs (Conflict-Free Replicated Data Types). Example: Implementing distributed transactions for multi-region writes in a banking application. - Explain the role of an Application Load Balancer (ALB) in cloud-based systems
An ALB distributes incoming application traffic across multiple targets (e.g., EC2 instances) within an Auto Scaling group, ensuring high availability and fault tolerance. Example: Using AWS Application Load Balancer to distribute incoming HTTP traffic across EC2 instances hosting a web application. - How do you handle long-running tasks in a web application?
Use background processing or task queues to handle long-running tasks asynchronously, freeing up resources for other requests. Example: Using Celery with RabbitMQ as a task queue to process image uploads in a social media application. - Discuss the differences between synchronous and asynchronous communication in distributed systems.
Synchronous communication waits for a response before proceeding, while asynchronous communication continues without waiting for an immediate response. Asynchronous communication is often preferred for scalability and responsiveness. Example: Synchronous – Traditional HTTP request-response; Asynchronous – Messaging systems like RabbitMQ or Apache Kafka.
Url Shortener
Here we are going to design a url shortener system.
Questions for clear scope
Can you give an example of how a URL shortener work? – https://www.systeminterview.com/q=chatsystem&c=loggedin&v=v3&l=long
What is the traffic volume? – 100 million URLs are generated per day.
How long is the shortened URL? – as short as possible
What characters are allowed in the shortened URL? – Shortened URL can be a combination of numbers (0-9) and characters (a-z, A- Z).
Can shortened URLs be deleted or updated? – For simplicity, let us assume shortened URLs cannot be deleted or updated.
Here are the basic use cases:
- URL shortening: given a long URL => return a much shorter URL
- URL redirecting: given a shorter URL => redirect to the original URL
- High availability, scalability, and fault tolerance considerations
Solution with Base 62 conversion
Base conversion is an approach commonly used for URL shorteners. Base conversion helps to convert the same number between its different number representation systems. Base 62 conversion is used as there are 62 possible characters for hashValue.
Conversion of 11157 to base 62
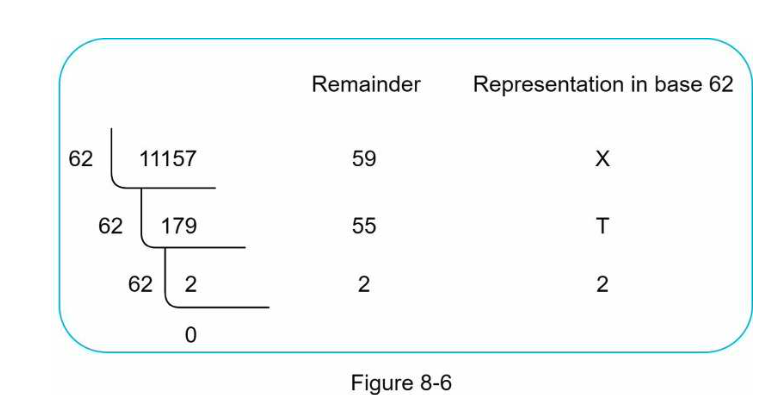
The short url is https://tinyurl.com/2TX
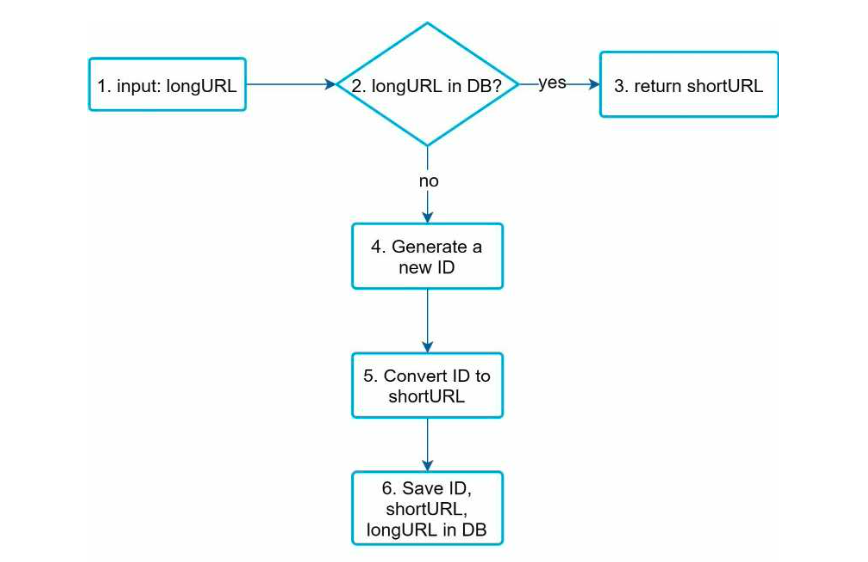
- longURL is the input.
- The system checks if the longURL is in the database.
- If it is, it means the longURL was converted to shortURL before. In this case, fetch the shortURL from the database and return it to the client.
- If not, the longURL is new. A new unique ID (primary key) Is generated by the unique ID generator.
- Convert the ID to shortURL with base 62 conversion.
- Create a new database row with the ID, shortURL, and longURL.
To make the flow easier to understand, let us look at a concrete example.
- Assuming the input longURL is: https://en.wikipedia.org/wiki/Systems_design • Unique ID generator returns ID: 2009215674938.
- Convert the ID to shortURL using the base 62 conversion. ID (2009215674938) is converted to “zn9edcu”.
- Save ID, shortURL, and longURL to the database

Comparison of Hash solution vs Base 62 conversion
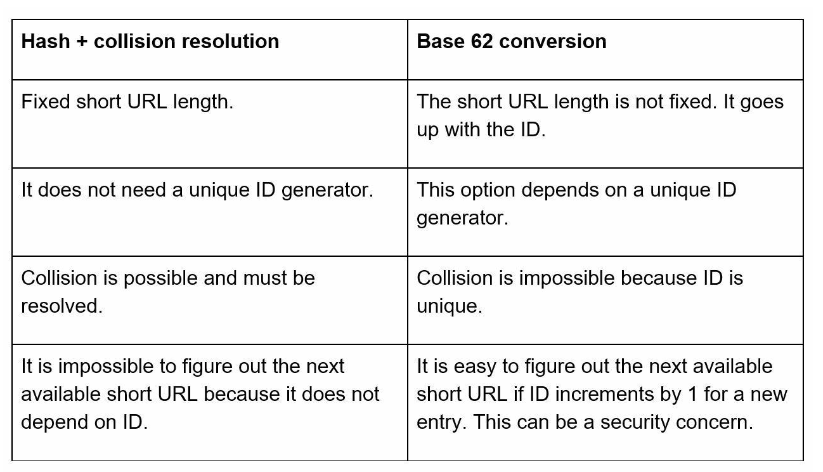
As you can see Base 62 conversion is the clear winner.
Chat System
A chat app performs different functions for different people. It is extremely important to nail down the exact requirements. For example, you do not want to design a system that focuses on group chat when the interviewer has one-on-one chat in mind. It is important to explore the feature requirements.
It is vital to agree on the type of chat app to design. In the marketplace, there are one-on-one chat apps like Facebook Messenger, WeChat, and WhatsApp, office chat apps that focus on group chat like Slack, or game chat apps, like Discord, that focus on large group interaction and low voice chat latency.
The first set of clarification questions should nail down what the interviewer has in mind exactly when she asks you to design a chat system. At the very least, figure out if you should focus on a one-on-one chat or group chat app.
Questions to ask for exact scope
What kind of chat app shall we design? 1 on 1 or group based? – It should support both 1 on 1 and group chat.
Is this a mobile app? Or a web app? Or both? – both
What is the scale of this app? A startup app or massive scale? – It should support 50 million daily active users (DAU).
For group chat, what is the group member limit? – A maximum of 100 people
What features are important for the chat app? Can it support attachment? – 1 on 1 chat, group chat, online indicator. The system only supports text messages.
Is there a message size limit? – Yes, text length should be less than 100,000 characters long.
Is end-to-end encryption required? – Not required for now but we will discuss that if time allows.
How long shall we store the chat history? – forever
These are the requirements based on the questions above:
- A one-on-one chat with low delivery latency
- Small group chat (max of 100 people)
- Online presence
- Multiple device support. The same account can be logged in to multiple accounts at the same time.
- Push notifications
Clients do not communicate directly with each other. Instead, each client connects to a chat service, which supports all the features mentioned above. Let us focus on fundamental operations. The chat service must support the following functions:
- Receive messages from other clients.
- Find the right recipients for each message and relay the message to the recipients.
- If a recipient is not online, hold the messages for that recipient on the server until she is online.

When a client intends to start a chat, it connects the chats service using one or more network protocols. For a chat service, the choice of network protocols is important.
Requests are initiated by the client for most client/server applications. This is also true for the sender side of a chat application. When the sender sends a message to the receiver via the chat service, it uses the time-tested HTTP protocol, which is the most common web protocol. In this scenario, the client opens a HTTP connection with the chat service and sends the message, informing the service to send the message to the receiver. However, the receiver side is a bit more complicated. Since HTTP is client-initiated, it is not trivial to send messages from the server. Over the years, many techniques are used to simulate a server-initiated connection: polling, long polling, and WebSocket.
Polling – polling is a technique that the client periodically asks the server if there are messages available. Depending on polling frequency, polling could be costly. It could consume precious server resources to answer a question that offers no as an answer most of the time.
Long Polling – in long polling, a client holds the connection open until there are actually new messages available or a timeout threshold has been reached. Once the client receives new messages, it immediately sends another request to the server, restarting the process. Long polling has a few drawbacks:
- Sender and receiver may not connect to the same chat server. HTTP based servers are usually stateless. If you use round robin for load balancing, the server that receives the message might not have a long-polling connection with the client who receives the message.
- A server has no good way to tell if a client is disconnected.
- It is inefficient. If a user does not chat much, long polling still makes periodic connections after timeouts.
Websocket – webSocket is the most common solution for sending asynchronous updates from server to client. WebSocket connection is initiated by the client. It is bi-directional and persistent. It starts its life as a HTTP connection and could be “upgraded” via some well-defined handshake to a WebSocket connection. Through this persistent connection, a server could send updates to a client.
- WebSocket connections generally work even if a firewall is in place. This is because they use port 80 or 443 which are also used by HTTP/HTTPS connections.
- Earlier we said that on the sender side HTTP is a fine protocol to use, but since WebSocket is bidirectional, there is no strong technical reason not to use it also for sending.
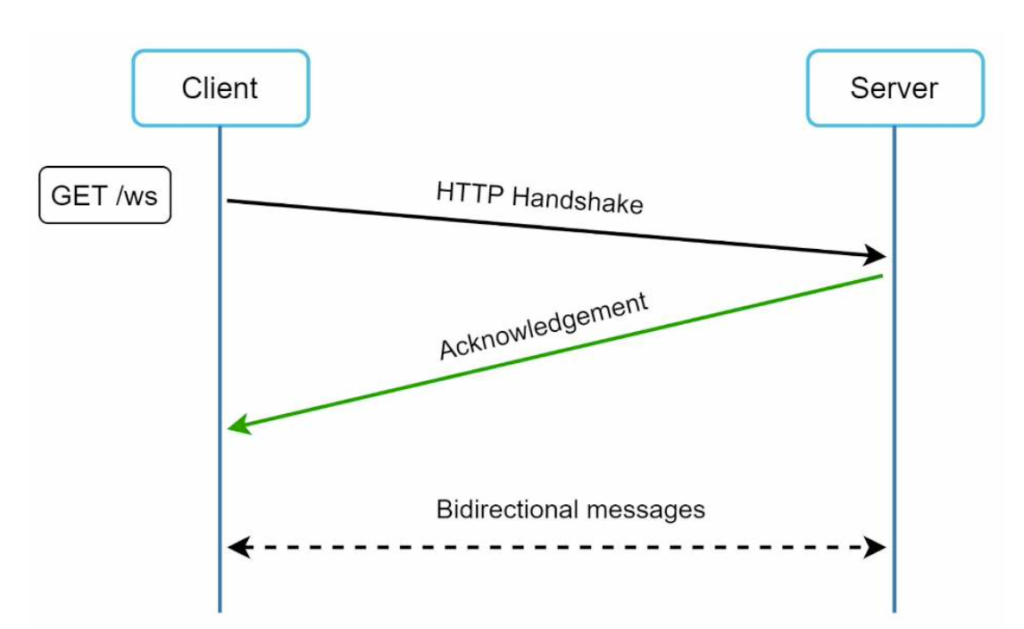
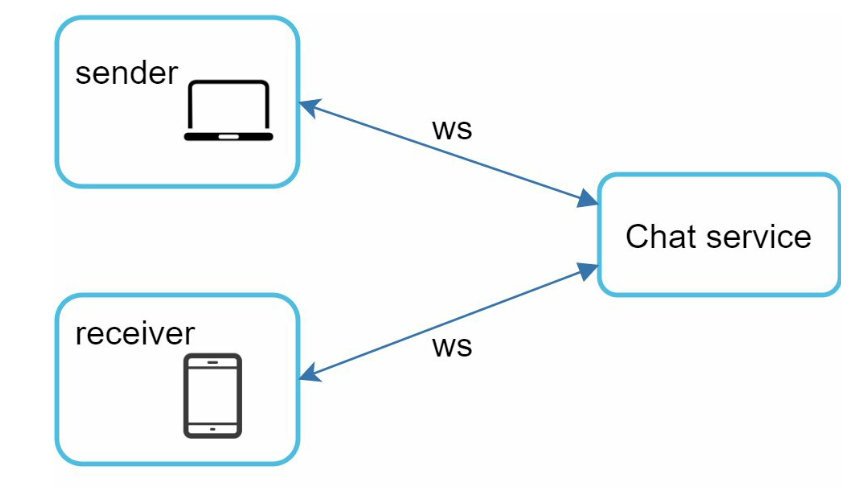
Scalability
No technologist would design such a scale in a single server. Single server design is a deal breaker due to many factors. The single point of failure is the biggest among them. We suggest having a presence server.
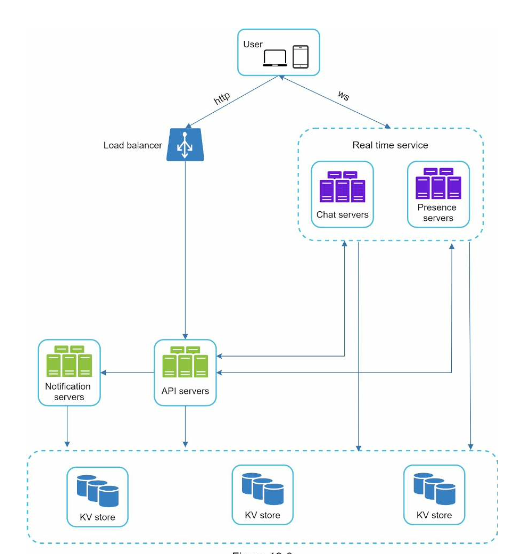
Here the client maintains a persistent WebSocket connection to a chat server for real-time messaging.
- Chat servers facilitate message sending/receiving.
- Presence servers manage online/offline status.
- API servers handle everything including user login, signup, change profile, etc.
- Notification servers send push notifications.
- Finally, the key-value store is used to store chat history. When an offline user comes online, she will see all her previous chat history.
Storage
Selecting the correct storage system that supports all of our use cases is crucial. We recommend key-value stores for the following reasons:
- Key-value stores allow easy horizontal scaling.
- Key-value stores provide very low latency to access data.
- Relational databases do not handle long tail of data well. When the indexes grow large, random access is expensive.
- Key-value stores are adopted by other proven reliable chat applications. For example, both Facebook messenger and Discord use key-value stores. Facebook messenger uses HBase, and Discord uses Cassandra.
One on One chat flow
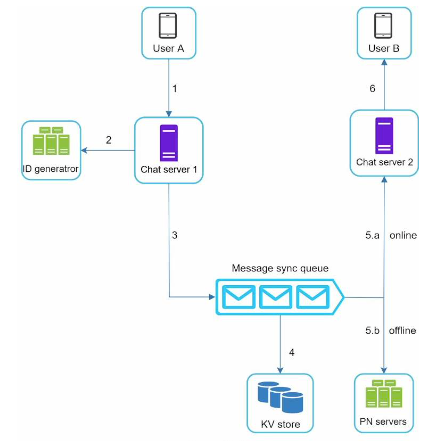
- User A sends a chat message to Chat server 1.
- Chat server 1 obtains a message ID from the ID generator.
- Chat server 1 sends the message to the message sync queue.
- The message is stored in a key-value store.
- If User B is online, the message is forwarded to Chat server 2 where User B is connected
- If User B is offline, a push notification is sent from push notification (PN) servers.
- Chat server 2 forwards the message to User B. There is a persistent WebSocket connection between User B and Chat server 2.
Message synchronization across multiple devices
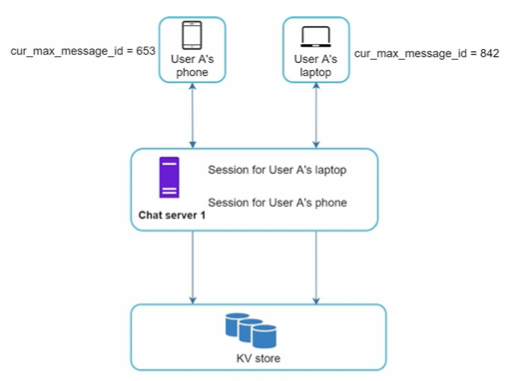
Each device maintains a variable called cur_max_message_id, which keeps track of the latest message ID on the device. Messages that satisfy the following two conditions are considered as news messages:
- The recipient ID is equal to the currently logged-in user ID.
- Message ID in the key-value store is larger than cur_max_message_id .
With distinct cur_max_message_id on each device, message synchronization is easy as each device can get new messages from the KV store.
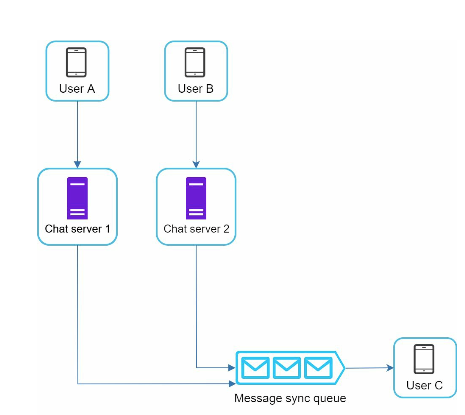
Group chat
Unique ID Generator
In this chapter, you are asked to design a unique ID generator for a distributed system. Your first thought might be to use a primary key with the auto_increment attribute in a traditional database. However, auto_increment does not work in a distributed environment because a single database server is not large enough and generating unique IDs across multiple databases with minimal delay is challenging.
Here is an example.

Questions to ask for clear scope
What are the characteristics of unique IDs? – IDs must be unique and sortable.
For each new record, does ID increment by 1? – The ID increments by time but not necessarily only increments by 1. IDs created in the evening are larger than those created in the morning on the same day.
Do IDs only contain numerical values? – Yes, that is correct.
What is the ID length requirement? – IDs should fit into 64-bit.
What is the scale of the system? – The system should be able to generate 10,000 IDs per second.
Now here are the requirements gathered from questions above:
- IDs must be unique.
- IDs are numerical values only.
- IDs fit into 64-bit.
- IDs are ordered by date.
- Ability to generate over 10,000 unique IDs per second.
Solution

Datacenter IDs and machine IDs are chosen at the startup time, generally fixed once the system is up running. Any changes in datacenter IDs and machine IDs require careful review since an accidental change in those values can lead to ID conflicts. Timestamp and sequence numbers are generated when the ID generator is running.
Timestamp
The most important 41 bits make up the timestamp section. As timestamps grow with time, IDs are sortable by time. Figure below shows an example of how binary representation is converted to UTC. You can also convert UTC back to binary representation using a similar method.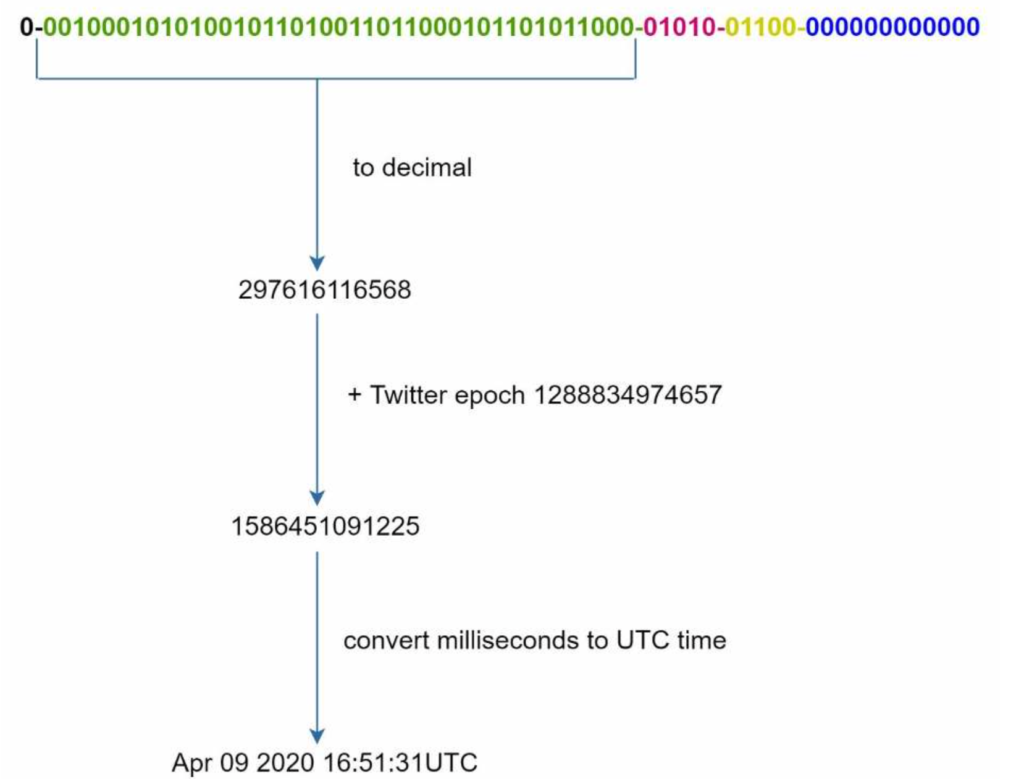
Sequence number
12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
There are other alternatives but they don’t work as well as the soluton above according to our requirements.
UUID is worth mentioning here as an alternative. If our requirements include that IDs are 128 bits long instead of 64 bits long or can be non-numeric then UUID will work.
Notification System
A notification system has already become a very popular feature for many applications in recent years. A notification alerts a user with important information like breaking news, product updates, events, offerings, etc. It has become an indispensable part of our daily life. In this chapter, you are asked to design a notification system.
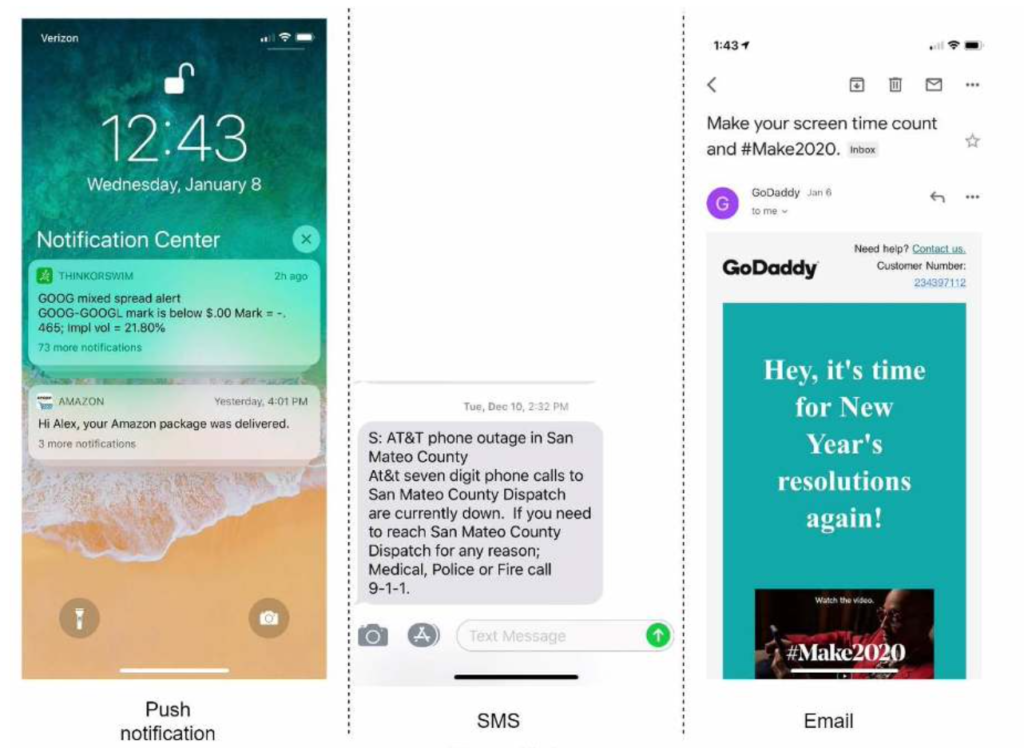
A notification is more than just mobile push notification. Three types of notification formats are: mobile push notification, SMS message, and Email. Figure 10-1 shows an example of each of these notifications.
Solution
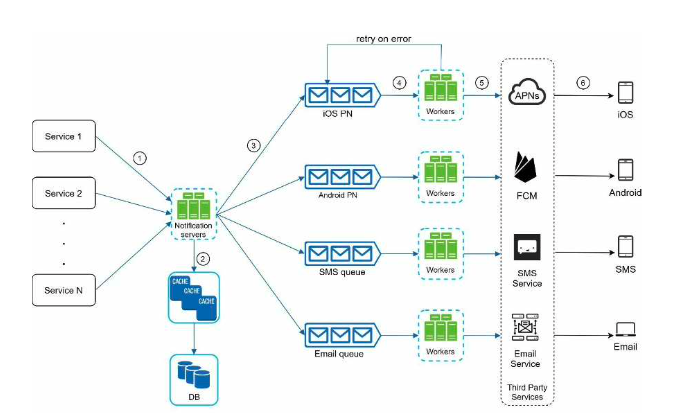
Service 1 to N: They represent different services that send notifications via APIs provided by notification servers.
Notification servers: They provide the following functionalities:
- Provide APIs for services to send notifications. Those APIs are only accessible internally or by verified clients to prevent spams.
- Carry out basic validations to verify emails, phone numbers, etc.
- Query the database or cache to fetch data needed to render a notification. • Put notification data to message queues for parallel processing.
Cache: User info, device info, notification templates are cached.
DB: It stores data about user, notification, settings, etc.
Message queues: They remove dependencies between components. Message queues serve as buffers when high volumes of notifications are to be sent out. Each notification type is assigned with a distinct message queue so an outage in one third-party service will not affect other notification types.
Workers: Workers are a list of servers that pull notification events from message queues and send them to the corresponding third-party services.
Third-party services: Already explained in the initial design.
iOS, Android, SMS, Email: Already explained in the initial design.
Now, let us examine how every component works together to send a notification:
- A service calls APIs provided by notification servers to send notifications.
- Notification servers fetch metadata such as user info, device token, and notification setting from the cache or database.
- A notification event is sent to the corresponding queue for processing. For instance, an iOS push notification event is sent to the iOS PN queue.
- Workers pull notification events from message queues. 5. Workers send notifications to third party services.
- Third-party services send notifications to user devices.
How to prevent data loss?
One of the most important requirements in a notification system is that it cannot lose data. Notifications can usually be delayed or re-ordered, but never lost. To satisfy this requirement, the notification system persists notification data in a database and implements a retry mechanism.
Will recipients receive a notification exactly once?
The short answer is no. Although notification is delivered exactly once most of the time, the distributed nature could result in duplicate notifications. To reduce the duplication occurrence, we introduce a dedupe mechanism and handle each failure case carefully. Here is a simple dedupe logic:
When a notification event first arrives, we check if it is seen before by checking the event ID. If it is seen before, it is discarded. Otherwise, we will send out the notification.
Notification template
A large notification system sends out millions of notifications per day, and many of these notifications follow a similar format. Notification templates are introduced to avoid building every notification from scratch. A notification template is a preformatted notification to create your unique notification by customizing parameters, styling, tracking links, etc. Here is an example template of push notifications.
BODY: You dreamed of it. We dared it. [ITEM NAME] is back — only until [DATE]. CTA: Order Now. Or, Save My [ITEM NAME] The benefits of using notification templates include maintaining a consistent format, reducing the margin error, and saving time.
Notification setting
Users generally receive way too many notifications daily and they can easily feel overwhelmed. Thus, many websites and apps give users fine-grained control over notification settings. This information is stored in the notification setting table, with the following fields:
user_id bigInt channel varchar # push notification, email or SMS opt_in boolean # opt-in to receive notification
Before any notification is sent to a user, we first check if a user is opted-in to receive this type of notification.
Rate limiting
To avoid overwhelming users with too many notifications, we can limit the number of notifications a user can receive. This is important because receivers could turn off notifications completely if we send too often.
Retry mechanism
When a third-party service fails to send a notification, the notification will be added to the message queue for retrying. If the problem persists, an alert will be sent out to developers.
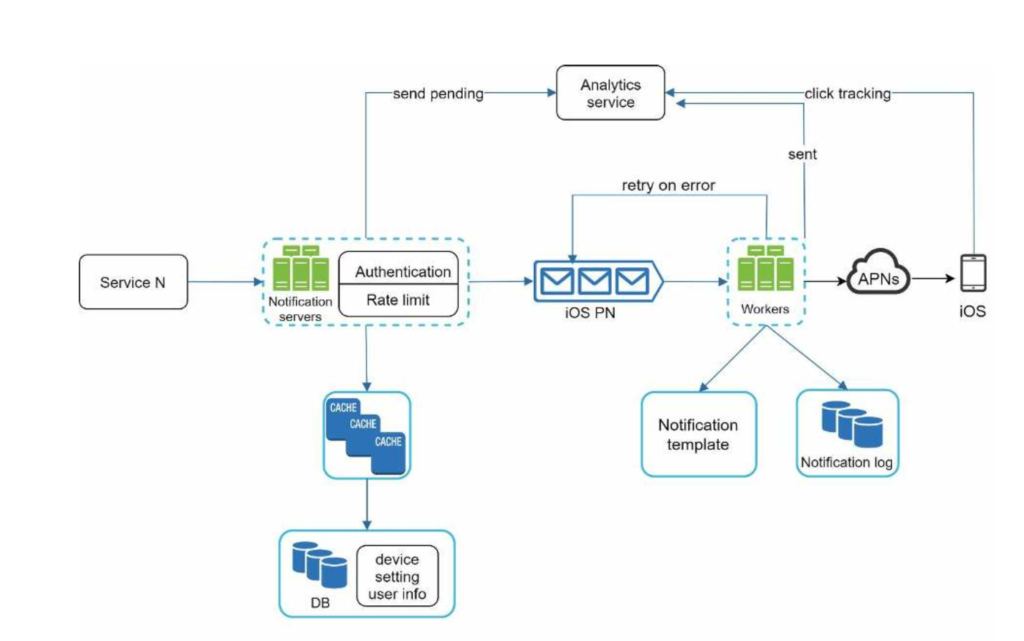
Here is the final design, many new components are added in comparison with the previous design.
- The notification servers are equipped with two more critical features: authentication and rate-limiting.
- We also add a retry mechanism to handle notification failures. If the system fails to send notifications, they are put back in the messaging queue and the workers will retry for a predefined number of times.
- Furthermore, notification templates provide a consistent and efficient notification creation process.
- Finally, monitoring and tracking systems are added for system health checks and future improvements.