AWS – IAMAWS – EC2AWS – Load BalancerAWS – Route 53AWS – RDSAWS – AuroraAWS – ElasticacheAWS – S3AWS – CloudFrontAWS – LambdaAWS – API GatewayAWS – DynamoDBAWS – KMS and EcryptionAWS – SQSAWS – SNSAWS – SESAWS – ElasticBeanstalkAWS – Elastic Container Service(ECS)AWS – KinesisAWS – CodecommitAWS – CodeBuildAWS – CloudFormationAWS – CodeDeployAWS – CLIAWS – CodePipelineAWS – CloudWatchAWS – AlexaAWS – Secrets ManagerAWS – Kubernetes on AWS
AWS Table of Content
- AWS – IAM
- AWS – EC2
- AWS – Load Balancer
- AWS – Route 53
- AWS – RDS
- AWS – Aurora
- AWS – Elasticache
- AWS – S3
- AWS – CloudFront
- AWS – Lambda
- AWS – API Gateway
- AWS – DynamoDB
- AWS – KMS and Encryption
- AWS – SQS
- AWS – SNS
- AWS – SES
- AWS – ElasticBeanstalk
- AWS – Kinesis
- AWS – CodeCommit
- AWS – CodeDeploy
- AWS – CodePipeline
- AWS – Elastic Container Service(ECS)
- AWS – CodeBuild
- AWS – CloudFormation
- AWS – CLI
- AWS – CloudWatch
- AWS – Alex
- AWS – Secrets Manager
- AWS – Kubernetes on AWS
AWS – Kubernetes on AWS
September 6, 2019AWS – Aurora
Aurora is a fully managed relational database engine that’s compatible with MySQL and PostgreSQL. It can deliver up to five times the throughput of MySQL and up to three times the throughput of PostgreSQL without requiring changes to most of your existing applications.
When connecting to Aurora instance, it is recommended that you use a custom endpoint(endpoint that does not change) instead of the instance endpoint in such cases. Doing so simplifies connection management and high availability as you add more DB instances to your cluster.
For clusters where high availability is important, where practical use the cluster endpoint for read-write connections and the reader endpoint for read-only connections. These kinds of connections manage DB instance failover better than instance endpoints do.
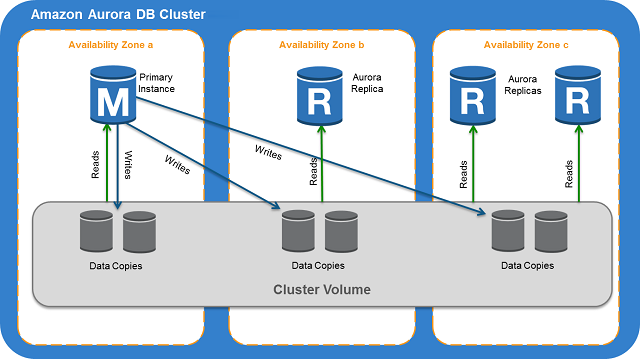
DB instance types: Aurora supports two types of instance classes: Memory-Optimized and Burstable Performance.
With Aurora Serverless, you can create a database endpoint without specifying the DB instance class size. You set the minimum and maximum capacity. With Aurora Serverless, the database endpoint connects to a proxy fleet that routes the workload to a fleet of resources that are automatically scaled. Because of the proxy fleet, connections are continuous as Aurora Serverless scales the resources automatically based on the minimum and maximum capacity specifications. Database client applications don’t need to change to use the proxy fleet. Aurora Serverless manages the connections automatically. Scaling is rapid because it uses a pool of “warm” resources that are always ready to service requests. Storage and processing are separate, so you can scale down to zero processing and pay only for storage.
You can specify the minimum and maximum ACU. The minimum Aurora capacity unit is the lowest ACU to which the DB cluster can scale down. The maximum Aurora capacity unit is the highest ACU to which the DB cluster can scale up. Based on your settings, Aurora Serverless automatically creates scaling rules for thresholds for CPU utilization, connections, and available memory.
Aurora Serverless manages the warm pool of resources in an AWS Region to minimize scaling time. When Aurora Serverless adds new resources to the Aurora DB cluster, it uses the proxy fleet to switch active client connections to the new resources. At any specific time, you are only charged for the ACUs that are being actively used in your Aurora DB cluster.
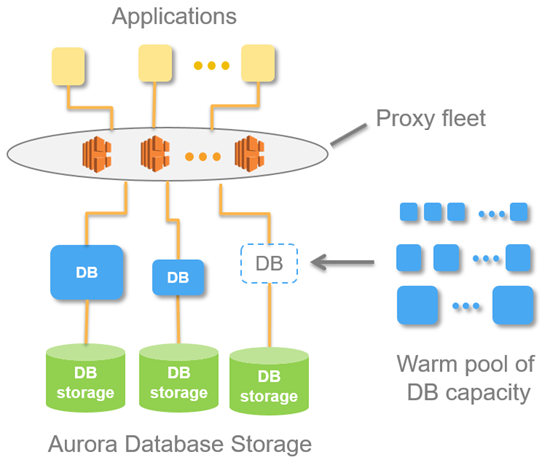
- Aurora DB clusters must be created in an Amazon Virtual Private Cloud (VPC). To control which devices and Amazon EC2 instances can open connections to the endpoint and port of the DB instance for Aurora DB clusters in a VPC, you use a VPC security group. You can make these endpoint and port connections using Transport Layer Security (TLS) / Secure Sockets Layer (SSL). In addition, firewall rules at your company can control whether devices running at your company can open connections to a DB instance.
- To authenticate logins and permissions for an Amazon Aurora DB cluster, you can use the same method as MySQL.
- Configure AWS Secrets Manager to automatically rotate the secrets for Amazon Aurora.
- Rotate your IAM credentials regularly.
- Grant each user the minimum set of permissions required to perform his or her duties.
Aurora clusters across regions
- You can create an Amazon Aurora MySQL DB cluster as a Read Replica in a different AWS Region than the source DB cluster. Taking this approach can improve your disaster recovery capabilities, let you scale read operations into an AWS Region that is closer to your users, and make it easier to migrate from one AWS Region to another.
- In a cross-region scenario, there is more lag time between the source DB cluster and the Read Replica due to the longer network channels between regions.
- You can run multiple concurrent create or delete actions for Read-Replicas that reference the same source DB cluster. However, you must stay within the limit of five Read Replicas for each source DB cluster.
- For replication to operate effectively, each Read Replica should have the same amount of computing and storage resources as the source DB cluster. If you scale the source DB cluster, you should also scale the Read Replicas.
- Both your source DB cluster and your cross-region Read Replica DB cluster can have up to 15 Aurora Replicas, along with the primary instance for the DB cluster. By using this functionality, you can scale read operations for both your source AWS Region and your replication target AWS Region.
AWS – Secrets Manager
This service has been a blessing for me in terms of hiding credentials from being exposed to hackers. This is what Secrets Manager does from the official site.
“AWS Secrets Manager helps you protect secrets needed to access your applications, services, and IT resources. The service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Users and applications retrieve secrets with a call to Secrets Manager APIs, eliminating the need to hardcode sensitive information in plain text. Secrets Manager offers secret rotation with built-in integration for Amazon RDS, Amazon Redshift, and Amazon DocumentDB. Also, the service is extensible to other types of secrets, including API keys and OAuth tokens. In addition, Secrets Manager enables you to control access to secrets using fine-grained permissions and audit secret rotation centrally for resources in the AWS Cloud, third-party services, and on-premises.”
How to implement:
Include this dependency in your pom file.
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-secretsmanager</artifactId> </dependency>
Configure an AWSSecretsManager bean or object.
@Configuration
public class DevConfig {
private Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
private AWSSecretsManagerUtils awsSecretsManagerUtils;
@Bean
public AWSCredentialsProvider amazonAWSCredentialsProvider() {
return DefaultAWSCredentialsProviderChain.getInstance();
}
@Bean
public AWSSecretsManager awsSecretsManager() {
AWSSecretsManager awsSecretsManager = AWSSecretsManagerClientBuilder
.standard()
.withCredentials(amazonAWSCredentialsProvider())
.withRegion(Regions.US_WEST_2)
.build();
return awsSecretsManager;
}
@Bean
public HikariDataSource dataSource() {
//log.debug("DB SECRET: {}", dbSecret.toJson());
DbSecret dbSecret = awsSecretsManagerUtils.getDbSecret();
log.info("Configuring dev datasource...");
Integer port = 3306;
String host = dbSecret.getHost();
String username = dbSecret.getUsername();
String password = dbSecret.getPassword();
String dbName = "springboot-course-tshirt";
String url = "jdbc:mysql://" + host + ":" + port + "/" + dbName + "?useUnicode=true&characterEncoding=utf8&useSSL=false";
HikariConfig config = new HikariConfig();
config.setJdbcUrl(url);
config.setUsername(username);
config.setPassword(password);
HikariDataSource hds = new HikariDataSource(config);
hds.setMaximumPoolSize(30);
hds.setMinimumIdle(20);
hds.setMaxLifetime(1800000);
hds.setConnectionTimeout(30000);
hds.setIdleTimeout(600000);
return hds;
}
}
Use the service by retrieving a mysql server database.
@Component
public class AWSSecretsManagerUtils {
private Logger log = LoggerFactory.getLogger(AWSSecretsManagerUtils.class);
@Value("${datasource.secret.name}")
private String dataSourceSecretName;
@Autowired
private AWSSecretsManager awsSecretsManager;
public DbSecret getDbSecret() {
return DbSecret.fromJson(getCredentials(dataSourceSecretName));
}
private String getCredentials(String secretId) {
GetSecretValueRequest getSecretValueRequest = new GetSecretValueRequest();
getSecretValueRequest.setSecretId(secretId);
GetSecretValueResult getSecretValueResponse = null;
try {
getSecretValueResponse = awsSecretsManager.getSecretValue(getSecretValueRequest);
} catch (Exception e) {
log.error("Exception, msg: ", e.getMessage());
}
if (getSecretValueResponse == null) {
return null;
}
ByteBuffer binarySecretData;
String secret;
// Decrypted secret using the associated KMS CMK
// Depending on whether the secret was a string or binary, one of these fields
// will be populated
if (getSecretValueResponse.getSecretString() != null) {
log.info("secret string");
secret = getSecretValueResponse.getSecretString();
} else {
log.info("secret binary secret data");
binarySecretData = getSecretValueResponse.getSecretBinary();
secret = binarySecretData.toString();
}
return secret;
}
}
public class DbSecret {
private String username;
private String password;
private String engine;
private String host;
private String dbInstanceIdentifier;
public DbSecret() {
this(null,null,null,null,null);
}
public DbSecret(String username, String password, String engine, String host,
String dbInstanceIdentifier) {
super();
this.username = username;
this.password = password;
this.engine = engine;
this.host = host;
this.dbInstanceIdentifier = dbInstanceIdentifier;
}
// setters and getters
public String toJson() {
try {
return ObjectUtils.getObjectMapper().writeValueAsString(this);
} catch (JsonProcessingException e) {
System.out.println("JsonProcessingException, msg: " + e.getLocalizedMessage());
return "{}";
}
}
public static DbSecret fromJson(String json) {
try {
return ObjectUtils.getObjectMapper().readValue(json, DbSecret.class);
} catch (IOException e) {
System.out.println("From Json Exception: "+e.getLocalizedMessage());
return null;
}
}
}
aws secretsmanager list-secrets --profile {profile-name}
aws secretsmanager get-secret-value --secret-id {secretName or ARN} --profile {profile-name}
AWS – CloudWatch
Amazon CloudWatch is a monitoring service for engineers.. CloudWatch provides you with data and actionable insights to monitor your applications, respond to system-wide performance changes, optimize resource utilization, and get a unified view of operational health. CloudWatch collects monitoring and operational data in the form of logs, metrics, and events, providing you with a unified view of AWS resources, applications, and services that run on AWS and on-premises servers. You can use CloudWatch to detect abnormal behavior in your environments, set alarms, visualize logs and metrics side by side, take automated actions, troubleshoot issues, and discover insights to keep your applications running smoothly.


CloudWatch performs 4 actions normally, first it collects log and metric data, then monitors the applications, then Acts according to the instructions, finally analyzes the collected log and metric data for further usage.
Events
AWS CloudWatch indicates a change in your environment. You can set up rules to respond to a change like a text message sent to you when your server is down.
Alarms
CloudWatch Alarms are used to monitor only metric data. You can set alarms in order to take actions by providing a condition in the metric data of a resource. Consider the CPU Utilization of the EC2 instance can be upto 75% and an Alarm should be evoked once it crosses the range.
There are 3 alarm states:
- OK – Within Threshold.
- ALARM – Crossed Threshold.
- INSUFFICIENT_DATA – Metric not available/ Missing data (Good, Bad, Ignore, Missing).
One of these states will be considered at each millisecond of using CloudWatch metric data
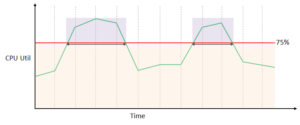
- When the CPU Utilization is 75% or lesser than 75% the Alarm state is at OK
- If it exceeds it is at ALARM you will notified
- Whenever there is no CPU Utilization data or incorrect data is produced, it will be called INSUFFIECIENT_DATA
Tail a log group from your computer. At the time of this writing, I am using aws cli v2.
- Open command line
- Get group name. Log groups are found under Cloudwatch service under Logs or run this command on the AWS CLI
-
aws logs describe-log-groups --log-group-name-prefix /ecs
The command above get all the log groups in the /ecs aws service. Here it will get all of the server log groups on ecs.
- Use the aws logs tail command
aws logs tail {log-group-name} --followExample – log api server on ecs
aws logs tail /ecs/backend-api --follow --format short