Unique ID Generator
In this chapter, you are asked to design a unique ID generator for a distributed system. Your first thought might be to use a primary key with the auto_increment attribute in a traditional database. However, auto_increment does not work in a distributed environment because a single database server is not large enough and generating unique IDs across multiple databases with minimal delay is challenging.
Here is an example.

Questions to ask for clear scope
What are the characteristics of unique IDs? – IDs must be unique and sortable.
For each new record, does ID increment by 1? – The ID increments by time but not necessarily only increments by 1. IDs created in the evening are larger than those created in the morning on the same day.
Do IDs only contain numerical values? – Yes, that is correct.
What is the ID length requirement? – IDs should fit into 64-bit.
What is the scale of the system? – The system should be able to generate 10,000 IDs per second.
Now here are the requirements gathered from questions above:
- IDs must be unique.
- IDs are numerical values only.
- IDs fit into 64-bit.
- IDs are ordered by date.
- Ability to generate over 10,000 unique IDs per second.
Solution

Datacenter IDs and machine IDs are chosen at the startup time, generally fixed once the system is up running. Any changes in datacenter IDs and machine IDs require careful review since an accidental change in those values can lead to ID conflicts. Timestamp and sequence numbers are generated when the ID generator is running.
Timestamp
The most important 41 bits make up the timestamp section. As timestamps grow with time, IDs are sortable by time. Figure below shows an example of how binary representation is converted to UTC. You can also convert UTC back to binary representation using a similar method.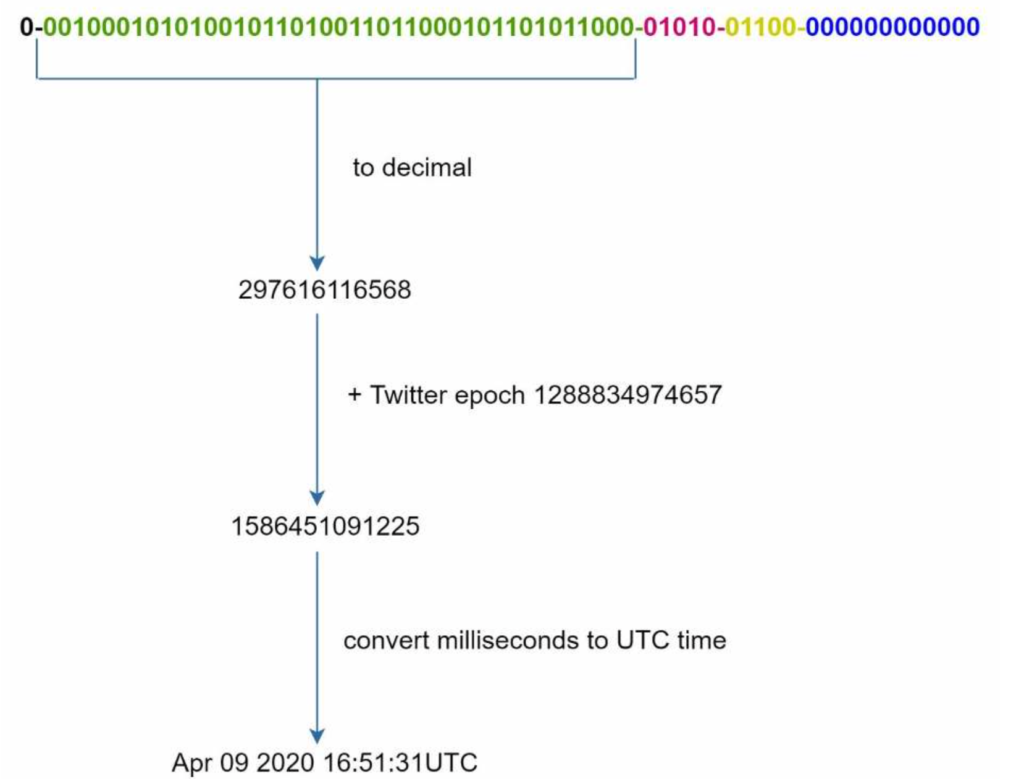
Sequence number
12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
There are other alternatives but they don’t work as well as the soluton above according to our requirements.
UUID is worth mentioning here as an alternative. If our requirements include that IDs are 128 bits long instead of 64 bits long or can be non-numeric then UUID will work.