Elasticsearch CAT API
Usually the results from various Elasticsearch APIs are displayed in JSON format. But JSON is not easy to read always. So CAT APIs feature is available in Elasticsearch helps in taking care of giving an easier to read and comprehend printing format of the results. There are various parameters used in cat API which serve different purpose, for example – the term V makes the output verbose.
Show indices
Show each index and their details
GET /_cat/indices?v
Show nodes
The nodes command shows the cluster topology
GET /_cat/nodes?h=ip,port,heapPercent,name
Show health
Show health status of each index
GET /_cat/health?v
Show plugins
The plugins command provides a view per node of running plugins.
GET /_cat/plugins?v&s=component&h=name,component,version,description
Th count provides quick access to the document count of the entire cluster, or individual indices.
GET /_cat/count/<target> //v, the response includes column headings. Defaults to false. GET /_cat/count/users?v
Elasticsearch Mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed.
Mappings are used to define:
- which string fields should be treated as full text fields.
- which fields contain numbers, dates, or geolocations.
- the format of date values.
- custom rules to control the mapping for dynamically added fields.
- a simple type like text, keyword, date, long, double, boolean or ip.
- a type which supports the hierarchical nature of JSON such as object or nested.
- or a specialised type like geo_point, geo_shape, or completion.
It is often useful to index the same field in different ways for different purposes. For instance, a string field could be indexed as a text field for full-text search, and as a keyword field for sorting or aggregations. Alternatively, you could index a string field with the standard analyzer , the english analyzer, and the french analyzer .
This is the purpose of multi-fields. Most datatypes support multi-fields via the fields parameter.
The following settings allow you to limit the number of field mappings that can be created manually or dynamically, in order to prevent bad documents from causing a mapping explosion:index.mapping.total_fields.limit
index.mapping.total_fields.limit – The maximum number of fields in an index. Field and object mappings, as well as field aliases count towards this limit. The default value is 1000.
index.mapping.depth.limit – The maximum depth for a field, which is measured as the number of inner objects. For instance, if all fields are defined at the root object level, then the depth is 1. If there is one object mapping, then the depth is 2, etc. The default is 20.
index.mapping.nested_fields.limit – The maximum number of distinct nested mappings in an index, defaults to 50.
index.mapping.nested_objects.limit – The maximum number of nested JSON objects within a single document across all nested types, defaults to 10000.
Dynamic Mapping
Fields and mapping types do not need to be defined before being used. Thanks to dynamic mapping, new field names will be added automatically, just by indexing a document. New fields can be added both to the top-level mapping type, and to inner object and nested fields.
Mapping Example
PUT user
{
"mappings": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
Java Mapping Example
String indexName = "doctors";
CreateIndexRequest request = new CreateIndexRequest(indexName);
request.settings(Settings.builder().put("index.number_of_shards", 1).put("index.number_of_replicas", 2));
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.startObject("properties");
{
builder.startObject("locations");
{
builder.field("type", "geo_point");
}
builder.endObject();
builder.startObject("addresses");
{
builder.field("type", "nested");
}
builder.endObject();
builder.startObject("specialities");
{
builder.field("type", "nested");
}
builder.endObject();
}
builder.endObject();
}
builder.endObject();
request.mapping(builder);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request,RequestOptions.DEFAULT);
Inverted Index
An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears.
An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data. By default, Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure.
Elasticsearch Document API
Elasticsearch provides single document APIs and multi-document APIs, where the API call is targeting a single document and multiple documents respectively.
All CRUD APIs are single-index APIs.
Adds a JSON document to the specified data stream or index and makes it searchable. If the target is an index and the document already exists, the request updates the document and increments its version. You cannot use the index API to send update requests for existing documents to a data stream.
You use one of these options to index a document:
PUT /<target>/_doc/<_id> POST /<target>/_doc/ PUT /<target>/_create/<_id> POST /<target>/_create/<_id> target - name of index. If the target doesn’t exist and doesn’t match a data stream template, this request creates the index. _id - id of the document Use POST /<target>/_doc/ when you want Elasticsearch to generate an ID for the document
You can index a new JSON document with the _doc or _create resource. Using _create guarantees that the document is only indexed if it does not already exist. To update an existing document, you must use the _doc resource.
Example of Index
PUT doctor_ut/_doc/1013143536
{
"npi" : "1013143536",
"firstName" : "SHAWN",
"lastName" : "WRIGHT",
"fullName" : "SHAWN WRIGHT",
"credential" : "LICSW",
"otherLastName" : "WRIGHT",
"otherFirstName" : "SHAWN",
"type" : "Individual",
"gender" : "FEMALE"
}
IndexRequest request = new IndexRequest(utIndex); request.id(doctorIndex.getNpi()); request.source(searchHit.getSourceAsString(), XContentType.JSON); IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
Retrieves the specified JSON document from an index.
GET <index>/_doc/<_id> HEAD <index>/_doc/<_id>
You use GET to retrieve a document and its source or stored fields from a particular index. Use HEAD to verify that a document exists. You can use the _source resource retrieve just the document source or verify that it exists.
Example of Get API
GET doctor_ut/_doc/1013143536
You can also specify the fields you want in your result from that particular document.
GET doctors/_doc/1013143536?_source_includes=name,rating
public void getDoctorByNPI() {
String indexName = Index.DOCTOR_UT.name().toLowerCase();
String npi = "1013143536";
GetRequest getRequest = new GetRequest(indexName, npi);
try {
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
log.info(getResponse.getSourceAsString());
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
}
Retrieves multiple JSON documents by ID. You use mget to retrieve multiple documents from one or more indices. If you specify an index in the request URI, you only need to specify the document IDs in the request body.
GET doctor_ut/_mget
{
"docs": [
{
"_id": "1689633083"
},
{
"_id": "1073924098"
}
]
}
Get multiple documents from different indices
GET _mget
{
"docs": [
{
"_index": "doctor_ut",
"_id": "1689633083"
},
{
"_index": "doctors",
"_id": "1073883070"
}
]
}
public void getMultipleDoctorsByNPIs() {
String utahDoctorIndex = Index.DOCTOR_UT.name().toLowerCase();
String doctorsIndex = Index.DOCTORS.name().toLowerCase();
String npi1 = "1013143536";
String npi2 = "1073883070";
GetRequest getRequest = new GetRequest(utahDoctorIndex, npi1);
MultiGetRequest request = new MultiGetRequest();
request.add(new MultiGetRequest.Item(utahDoctorIndex, npi1));
request.add(new MultiGetRequest.Item(doctorsIndex, npi2));
try {
MultiGetResponse response = restHighLevelClient.mget(request, RequestOptions.DEFAULT);
// utah doctor
MultiGetItemResponse utahDoctor = response.getResponses()[0];
log.info(utahDoctor.getResponse().getSourceAsString());
MultiGetItemResponse doctor = response.getResponses()[1];
log.info(doctor.getResponse().getSourceAsString());
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
}
Updates a document using the specified script.
POST /<index>/_update/<_id>
{
...
}
The update API also supports passing a partial document, which is merged into the existing document. To fully replace an existing document, use the index API .
The document must still be reindexed, but using update removes some network roundtrips and reduces chances of version conflicts between the GET and the index operation.
The _source field must be enabled to use update. In addition to _source, you can access the following variables through the ctx map: index, _type, _id, _version, _routing, and _now(the current timestamp).
POST doctor_ut/_update/1013143536
{
"doc": {
"firstName": "Folau"
},
"doc_as_upsert": true
}
public void updateDoctor() {
String indexName = Index.DOCTOR_UT.name().toLowerCase();
String npi = "1013143536";
UpdateRequest request = new UpdateRequest(indexName, npi);
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("firstName", "Folau");
request.doc(jsonMap, XContentType.JSON);
try {
UpdateResponse updateResponse = restHighLevelClient.update(request, RequestOptions.DEFAULT);
log.info(updateResponse.getGetResult().sourceAsString());
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
}
While processing an update by query request, Elasticsearch performs multiple search requests sequentially to find all of the matching documents. A bulk update request is performed for each batch of matching documents. Any query or update failures cause the update by query request to fail and the failures are shown in the response. Any update requests that completed successfully still stick, they are not rolled back
POST /<index>/_update_by_query
Updates documents that match the specified query. If no query is specified, performs an update on every document in the data stream or index without modifying the source, which is useful for picking up mapping changes.
POST doctor_ut/_update_by_query
{
"script": {
"source": "if (ctx._source.firstName == 'Kinga') {ctx._source.firstName='Tonga';}",
"lang": "painless"
},
"query": {
"term": {
"firstName": "Kinga"
}
}
}
Java example of Update by query
public void batchUpdateDoctors() {
String indexName = Index.DOCTOR_UT.name().toLowerCase();
UpdateByQueryRequest request = new UpdateByQueryRequest(indexName);
request.setQuery(new TermQueryBuilder("firstName", "new_name1"));
request.setScript(new Script(ScriptType.INLINE, "painless", "if (ctx._source.firstName == 'new_name1') {ctx._source.firstName='Kinga';}", Collections.emptyMap()));
try {
BulkByScrollResponse bulkResponse = restHighLevelClient.updateByQuery(request, RequestOptions.DEFAULT);
log.info("updated={}", bulkResponse.getStatus().getUpdated());
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
}
Removes a JSON document from the specified index. You use DELETE to remove a document from an index. You must specify the index name and document ID.
DELETE /<index>/_doc/<_id>
DELETE doctor_ut/_doc/1013143536
public void deleteDoctor() {
String indexName = Index.DOCTOR_UT.name().toLowerCase();
String npi = "1013143536";
DeleteRequest request = new DeleteRequest(indexName, npi);
try {
DeleteResponse deleteResponse = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
log.info(deleteResponse.getIndex());
} catch (Exception e) {
log.warn(e.getLocalizedMessage());
}
}
Copies documents from a source to a destination.
The source and destination can be any pre-existing index, index alias, or data stream . However, the source and destination must be different. For example, you cannot reindex a data stream into itself.
Reindex requires _source to be enabled for all documents in the source.
The destination should be configured as wanted before calling _reindex. Reindex does not copy the settings from the source or its associated template.
Mappings, shard counts, replicas, and so on must be configured ahead of time.
POST _reindex
{
"source": {
"index": "doctors"
},
"dest": {
"index": "doctor-ut"
}
}
What is Elasticsearch?
Elasticsearch is the distributed search and analytics engine. Elasticsearch provides near real-time search and analytics for all types of data. Whether you have structured or unstructured text, numerical data, or geospatial data, Elasticsearch can efficiently store and index it in a way that supports fast searches. It is accessible from RESTful web service interface and uses schema less JSON (JavaScript Object Notation) documents to store data. It is built on Java programming language and hence Elasticsearch can run on different platforms. It enables users to explore very large amount of data at very high speed.
General Features
- Elasticsearch is scalable up to petabytes of structured and unstructured data.
- Elasticsearch can be used as a replacement of document stores like MongoDB and RavenDB.
- Elasticsearch uses denormalization to improve the search performance.
- Elasticsearch is an open source and available under the Apache license version 2.0.
- Elasticsearch is one of the popular enterprise search engines, and is currently being used by many big organizations like Wikipedia, The Guardian, StackOverflow, GitHub etc.
- Store and analyze logs, metrics, and security event data
- Use machine learning to automatically model the behavior of your data in real time
- Automate business workflows using Elasticsearch as a storage engine
- Manage, integrate, and analyze spatial information using Elasticsearch as a geographic information system (GIS)
Data stored as Document
Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents. When you have multiple Elasticsearch nodes in a cluster, stored documents are distributed across the cluster and can be accessed immediately from any node.
When a document is stored, it is indexed and fully searchable in near real-time –within 1 second. Elasticsearch uses a data structure called an inverted index that supports very fast full-text searches. An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in.
An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data. By default, Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees. The ability to use the per-field data structures to assemble and return search results is what makes Elasticsearch so fast.
Elasticsearch also has the ability to be schema-less, which means that documents can be indexed without explicitly specifying how to handle each of the different fields that might occur in a document. When dynamic mapping is enabled, Elasticsearch automatically detects and adds new fields to the index. This default behavior makes it easy to index and explore your data—just start indexing documents and Elasticsearch will detect and map booleans, floating point and integer values, dates, and strings to the appropriate Elasticsearch data types.
Node
A node is a single running instance(server) of a cluster
Cluster
A cluster is a collection of nodes. Cluster provides collective indexing and search capabilities across all the nodes for entire data.
Index
It is a collection of different type of documents and their properties. Index also uses the concept of shards to improve the performance. For example, a set of document contains data of a social networking application.
Document
It is a collection of fields in a specific manner defined in JSON format. Every document belongs to a type and resides inside an index. Every document is associated with a unique identifier called the UID.
Shard
Indexes are horizontally subdivided into shards. This means each shard contains all the properties of document but contains less number of JSON objects than index. The horizontal separation makes shard an independent node, which can be store in any node. Primary shard is the original horizontal part of an index and then these primary shards are replicated into replica shards.
Replicas
Elasticsearch allows a user to create replicas of their indexes and shards. Replication not only helps in increasing the availability of data in case of failure, but also improves the performance of searching by carrying out a parallel search operation in these replicas
RDBMS and Elasticsearch
| Elasticsearch | RDBMS |
|---|---|
| Cluster | Database |
| Shard | Shard |
| Index | Table |
| Field | Column |
| Document | Row |
Advantages
- Elasticsearch is developed on Java, which makes it compatible on almost every platform.
- Elasticsearch is real time, in other words after one second the added document is searchable in this engine
- Elasticsearch is distributed, which makes it easy to scale and integrate in any big organization.
- Creating full backups are easy by using the concept of gateway, which is present in Elasticsearch.
- Handling multi-tenancy is very easy in Elasticsearch when compared to Apache Solr.
- Elasticsearch uses JSON objects as responses, which makes it possible to invoke the Elasticsearch server with a large number of different programming languages.
- Elasticsearch supports almost every document type except those that do not support text rendering.
Disadvantages
- Elasticsearch has a problem of Split brain situations at times.
Springboot Lombok
Project Lombok is a java library that automatically plugs into your editor and build tools, spicing up your java.
Never write another getter or equals method again, with one annotation your class has a fully featured builder, Automate your logging variables, and much more.
Java can get too verbose for things you have to do such as generating getter and setter methods. These things often bring no real value to the business side of your applications. This is what lombok is for. Lombok is here to help you generate boilerplate code and you focus on business logic. The way it works is by plugging into your build process and autogenerating Java bytecode into your .class files as per a number of project annotations you introduce in your code.
Install Lombok on your computer
- Add dependency
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> - Find lombok.jar in your project maven directory -> Right click -> Run As -> Java Application
- Click on Specify Location button to choose the path where STS is installed
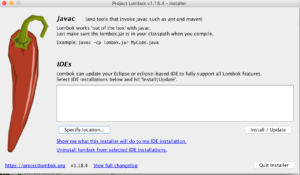
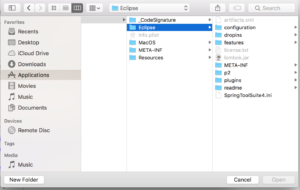
- Go to Application/Contents/Eclipse/SpringToolSuit4.ini Then click on Install -> Quick Installer
- Restart STS you are good to go
Use Lombok in your project
import java.io.Serializable;
import java.util.Date;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.UUID;
import java.util.stream.Collectors;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.EnumType;
import javax.persistence.Enumerated;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Index;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.Lob;
import javax.persistence.ManyToMany;
import javax.persistence.OneToOne;
import javax.persistence.PrePersist;
import javax.persistence.PreUpdate;
import javax.persistence.Table;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import javax.validation.constraints.NotEmpty;
import org.hibernate.annotations.CreationTimestamp;
import org.hibernate.annotations.ResultCheckStyle;
import org.hibernate.annotations.SQLDelete;
import org.hibernate.annotations.Type;
import org.hibernate.annotations.UpdateTimestamp;
import org.hibernate.annotations.Where;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.social.api.address.Address;
import com.social.api.user.role.Role;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Setter
@Getter
@ToString
@AllArgsConstructor
@NoArgsConstructor
@JsonInclude(value = Include.NON_NULL)
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String firstName;
private String lastName;
private String email;
private String password;
private String phoneNumber;
private Date dateOfBirth;
private String aboutMe;
private String profileImageUrl;
private String coverImageUrl;
private Date passwordExpirationDate;
private Integer invalidPasswordCounter = 0;
}