Flyweight Pattern
Introduction
The Flyweight Pattern is a structural design pattern that minimizes memory usage by sharing as much data as possible between similar objects. Imagine a text editor rendering a document with thousands of characters. Each character needs a font, size, and color — but most characters share the same formatting. Instead of storing duplicate formatting data in every character object, the Flyweight Pattern extracts the shared state into reusable objects.
This pattern is critical in performance-sensitive applications where creating millions of similar objects would consume too much memory.
The Problem
You are building a text editor that represents every character in a document as an object. Each character object stores its value, font family, font size, color, and position. A 100,000-character document creates 100,000 objects, most of which share the same font, size, and color. The application consumes gigabytes of memory for data that is largely duplicated.
Simply put, the naive approach stores redundant data thousands of times over, wasting memory that could be avoided.
The Solution
Split the object’s data into two categories: intrinsic state (shared, immutable data like font and color) and extrinsic state (unique, context-specific data like position). Create flyweight objects that store only the intrinsic state and share them across all characters that have the same formatting. Pass the extrinsic state (position) as method parameters when needed.
A flyweight factory ensures that only one flyweight object exists per unique combination of intrinsic state.
Key Principle
The Flyweight Pattern applies the principle of sharing to support large numbers of fine-grained objects efficiently. It trades a small increase in code complexity for a massive reduction in memory consumption. The key distinction is between intrinsic state (shareable) and extrinsic state (unique per context).
Java Example
Here we build a character rendering system where formatting is shared across characters.
import java.util.HashMap;
import java.util.Map;
// Flyweight: stores shared intrinsic state (font properties)
public class CharacterStyle {
private final String fontFamily;
private final int fontSize;
private final String color;
public CharacterStyle(String fontFamily, int fontSize, String color) {
this.fontFamily = fontFamily;
this.fontSize = fontSize;
this.color = color;
}
public void render(char character, int row, int col) {
System.out.printf("Rendering '%c' at (%d,%d) with %s %dpx %s%n",
character, row, col, fontFamily, fontSize, color);
}
public String getKey() {
return fontFamily + "_" + fontSize + "_" + color;
}
}
// Flyweight Factory: ensures shared instances
public class StyleFactory {
private final Map<String, CharacterStyle> styles = new HashMap<>();
public CharacterStyle getStyle(String fontFamily, int fontSize, String color) {
String key = fontFamily + "_" + fontSize + "_" + color;
if (!styles.containsKey(key)) {
System.out.println("[Factory] Creating new style: " + key);
styles.put(key, new CharacterStyle(fontFamily, fontSize, color));
}
return styles.get(key);
}
public int getStyleCount() {
return styles.size();
}
}
// Context: stores extrinsic state (position) + reference to flyweight
public class Character {
private final char value;
private final int row;
private final int col;
private final CharacterStyle style; // Shared flyweight
public Character(char value, int row, int col, CharacterStyle style) {
this.value = value;
this.row = row;
this.col = col;
this.style = style;
}
public void render() {
style.render(value, row, col);
}
}
// Usage
public class Main {
public static void main(String[] args) {
StyleFactory factory = new StyleFactory();
// Simulate a document with many characters sharing few styles
List<Character> document = new ArrayList<>();
// Body text: thousands of characters, all same style
String bodyText = "The Flyweight Pattern saves memory by sharing objects.";
CharacterStyle bodyStyle = factory.getStyle("Arial", 12, "#333333");
for (int i = 0; i < bodyText.length(); i++) {
document.add(new Character(bodyText.charAt(i), 0, i, bodyStyle));
}
// Heading: different style, shared among heading characters
String heading = "Design Patterns";
CharacterStyle headingStyle = factory.getStyle("Arial", 24, "#000000");
for (int i = 0; i < heading.length(); i++) {
document.add(new Character(heading.charAt(i), 1, i, headingStyle));
}
// Code snippet: yet another shared style
String code = "Map<String, Object> cache";
CharacterStyle codeStyle = factory.getStyle("Courier", 14, "#008000");
for (int i = 0; i < code.length(); i++) {
document.add(new Character(code.charAt(i), 2, i, codeStyle));
}
// Render first few characters
for (int i = 0; i < 5; i++) {
document.get(i).render();
}
System.out.println("\nTotal characters: " + document.size());
System.out.println("Unique styles (flyweights): " + factory.getStyleCount());
System.out.println("Memory saved by sharing styles instead of duplicating them");
}
}
Python Example
The same character rendering flyweight scenario in Python.
from dataclasses import dataclass
# Flyweight: stores shared intrinsic state (font properties)
class CharacterStyle:
def __init__(self, font_family: str, font_size: int, color: str):
self.font_family = font_family
self.font_size = font_size
self.color = color
def render(self, character: str, row: int, col: int) -> None:
print(f"Rendering '{character}' at ({row},{col}) "
f"with {self.font_family} {self.font_size}px {self.color}")
@property
def key(self) -> str:
return f"{self.font_family}_{self.font_size}_{self.color}"
# Flyweight Factory: ensures shared instances
class StyleFactory:
def __init__(self):
self._styles: dict[str, CharacterStyle] = {}
def get_style(self, font_family: str, font_size: int, color: str) -> CharacterStyle:
key = f"{font_family}_{font_size}_{color}"
if key not in self._styles:
print(f"[Factory] Creating new style: {key}")
self._styles[key] = CharacterStyle(font_family, font_size, color)
return self._styles[key]
@property
def style_count(self) -> int:
return len(self._styles)
# Context: stores extrinsic state (position) + reference to flyweight
@dataclass
class Character:
value: str
row: int
col: int
style: CharacterStyle # Shared flyweight
def render(self) -> None:
self.style.render(self.value, self.row, self.col)
# Usage
if __name__ == "__main__":
factory = StyleFactory()
document: list[Character] = []
# Body text: many characters, all same style
body_text = "The Flyweight Pattern saves memory by sharing objects."
body_style = factory.get_style("Arial", 12, "#333333")
for i, ch in enumerate(body_text):
document.append(Character(ch, row=0, col=i, style=body_style))
# Heading: different style, shared among heading characters
heading = "Design Patterns"
heading_style = factory.get_style("Arial", 24, "#000000")
for i, ch in enumerate(heading):
document.append(Character(ch, row=1, col=i, style=heading_style))
# Code snippet: yet another shared style
code = "cache: dict[str, object]"
code_style = factory.get_style("Courier", 14, "#008000")
for i, ch in enumerate(code):
document.append(Character(ch, row=2, col=i, style=code_style))
# Render first few characters
for char in document[:5]:
char.render()
print(f"\nTotal characters: {len(document)}")
print(f"Unique styles (flyweights): {factory.style_count}")
print("Memory saved by sharing styles instead of duplicating them")
When to Use
- Large numbers of similar objects — When your application creates thousands or millions of objects that share most of their data
- Memory-constrained environments — When memory usage is a bottleneck and objects have significant shared state
- Immutable shared state — When the shared portion of object state can be made immutable and safely shared across threads
- Game development — Particle systems, tile maps, and bullet pools where thousands of entities share textures and behaviors
Real-World Usage
- Java’s
String.intern()— The JVM’s string pool is a flyweight implementation, sharing identical string instances - Java’s
Integer.valueOf()— Caches Integer objects for values -128 to 127, returning shared instances - Game engines — Unity and Unreal share mesh, texture, and material data across thousands of game objects
- Python’s small integer cache — CPython caches integers from -5 to 256, making
a = 100; b = 100; a is breturnTrue - Browser DOM — CSS classes act as flyweights, sharing style definitions across thousands of elements
Composite Pattern
Introduction
The Composite Pattern is a structural design pattern that lets you compose objects into tree structures and then work with those structures as if they were individual objects. Think of a file system — a directory can contain files and other directories. Whether you ask for the size of a single file or an entire directory tree, you use the same operation. The composite handles the recursion for you.
This pattern is essential whenever you deal with hierarchical or tree-like structures where individual items and groups of items should be treated uniformly.
The Problem
You are building a file system utility that calculates the total size of files and directories. A file has a fixed size, but a directory contains other files and subdirectories, each of which may contain more files and subdirectories. You need to calculate the total size at any level of the tree.
Without a unified interface, client code must constantly check whether it is dealing with a file or a directory, leading to scattered conditional logic and code that breaks every time a new type of node is added.
The Solution
Define a common interface (FileSystemComponent) with a getSize() method. Files implement it by returning their own size. Directories implement it by summing the sizes of all their children — which can be files or other directories. Client code simply calls getSize() on any component without caring about its type.
The recursive structure is handled naturally by the composite, and the client code remains clean and simple.
Key Principle
The Composite Pattern follows the Uniform Treatment Principle — clients should not need to distinguish between individual objects and compositions of objects. It also leverages recursive composition, letting you build complex structures from simple, uniform building blocks.
Java Example
Here we model a file system where files and directories share a common interface.
import java.util.ArrayList;
import java.util.List;
// Component interface
public interface FileSystemComponent {
String getName();
long getSize();
void display(String indent);
}
// Leaf: individual file
public class FileItem implements FileSystemComponent {
private final String name;
private final long size;
public FileItem(String name, long size) {
this.name = name;
this.size = size;
}
@Override
public String getName() { return name; }
@Override
public long getSize() { return size; }
@Override
public void display(String indent) {
System.out.printf("%s📄 %s (%d bytes)%n", indent, name, size);
}
}
// Composite: directory containing files and subdirectories
public class Directory implements FileSystemComponent {
private final String name;
private final List<FileSystemComponent> children = new ArrayList<>();
public Directory(String name) {
this.name = name;
}
public Directory add(FileSystemComponent component) {
children.add(component);
return this; // Fluent API
}
public void remove(FileSystemComponent component) {
children.remove(component);
}
@Override
public String getName() { return name; }
@Override
public long getSize() {
// Recursively sums sizes of all children
return children.stream()
.mapToLong(FileSystemComponent::getSize)
.sum();
}
@Override
public void display(String indent) {
System.out.printf("%s📁 %s/ (%d bytes total)%n", indent, name, getSize());
for (FileSystemComponent child : children) {
child.display(indent + " ");
}
}
}
// Usage
public class Main {
public static void main(String[] args) {
// Build a file system tree
Directory root = new Directory("project");
Directory src = new Directory("src");
src.add(new FileItem("Main.java", 2400));
src.add(new FileItem("Utils.java", 1200));
Directory config = new Directory("config");
config.add(new FileItem("application.yml", 350));
config.add(new FileItem("logback.xml", 500));
src.add(config);
Directory test = new Directory("test");
test.add(new FileItem("MainTest.java", 1800));
root.add(src);
root.add(test);
root.add(new FileItem("README.md", 600));
root.add(new FileItem("pom.xml", 3200));
// Uniform interface - works the same for files and directories
root.display("");
System.out.println("\nTotal project size: " + root.getSize() + " bytes");
// Works on any subtree too
System.out.println("Source directory size: " + src.getSize() + " bytes");
}
}
Python Example
The same file system composite scenario in Python.
from abc import ABC, abstractmethod
# Component interface
class FileSystemComponent(ABC):
@abstractmethod
def get_name(self) -> str:
pass
@abstractmethod
def get_size(self) -> int:
pass
@abstractmethod
def display(self, indent: str = "") -> None:
pass
# Leaf: individual file
class FileItem(FileSystemComponent):
def __init__(self, name: str, size: int):
self._name = name
self._size = size
def get_name(self) -> str:
return self._name
def get_size(self) -> int:
return self._size
def display(self, indent: str = "") -> None:
print(f"{indent}file: {self._name} ({self._size} bytes)")
# Composite: directory containing files and subdirectories
class Directory(FileSystemComponent):
def __init__(self, name: str):
self._name = name
self._children: list[FileSystemComponent] = []
def add(self, component: FileSystemComponent) -> "Directory":
self._children.append(component)
return self # Fluent API
def remove(self, component: FileSystemComponent) -> None:
self._children.remove(component)
def get_name(self) -> str:
return self._name
def get_size(self) -> int:
# Recursively sums sizes of all children
return sum(child.get_size() for child in self._children)
def display(self, indent: str = "") -> None:
print(f"{indent}dir: {self._name}/ ({self.get_size()} bytes total)")
for child in self._children:
child.display(indent + " ")
# Usage
if __name__ == "__main__":
# Build a file system tree
root = Directory("project")
src = Directory("src")
src.add(FileItem("Main.java", 2400))
src.add(FileItem("Utils.java", 1200))
config = Directory("config")
config.add(FileItem("application.yml", 350))
config.add(FileItem("logback.xml", 500))
src.add(config)
test = Directory("test")
test.add(FileItem("MainTest.java", 1800))
root.add(src)
root.add(test)
root.add(FileItem("README.md", 600))
root.add(FileItem("pom.xml", 3200))
# Uniform interface - works the same for files and directories
root.display()
print(f"\nTotal project size: {root.get_size()} bytes")
# Works on any subtree too
print(f"Source directory size: {src.get_size()} bytes")
When to Use
- Tree structures — When your data naturally forms a tree (file systems, org charts, UI component trees, menu systems)
- Uniform operations — When you need to perform the same operation on individual items and groups of items
- Recursive aggregation — When you need to calculate aggregate values (size, cost, count) across a hierarchy
- Dynamic composition — When items and groups need to be assembled and modified at runtime
Real-World Usage
- Java Swing/AWT —
ComponentandContainerform a composite tree where containers hold other components - React/DOM — The Virtual DOM is a composite tree where elements can contain other elements
- Java’s
java.io.File— Represents both files and directories with shared operations likelength()andlistFiles() - Python’s
astmodule — Abstract Syntax Trees where nodes contain other nodes uniformly - Spring Security —
GrantedAuthorityhierarchies where roles can contain other roles
HashTable
The Hash table data structure stores elements in key-value pairs where
- Key– unique integer that is used for indexing the values
- Value – data that are associated with keys.
The key is sent to a hash function that performs arithmetic operations on it. The result (commonly called the hash value or hash) is the index of the key-value pair in the hash table.
1. Hash function
As we’ve already seen, the hash function determines the index of our key-value pair. Choosing an efficient hash function is a crucial part of creating a good hash table. You should always ensure that it’s a one-way function, i.e., the key cannot be retrieved from the hash. Another property of a good hash function is that it avoids producing the same hash for different keys.
2. Array
The array holds all the key-value entries in the table. The size of the array should be set according to the amount of data expected.
Collisions in hash tables & resolutions
A collision occurs when two keys get mapped to the same index. There are several ways of handling collisions.
1. Linear probing
If a pair is hashed to a slot which is already occupied, it searches linearly for the next free slot in the table.
2. Chaining
The hash table will be an array of linked lists. All keys mapping to the same index will be stored as linked list nodes at that index.
3. Resizing the hash table
The size of the hash table can be increased in order to spread the hash entries further apart. A threshold value signifies the percentage of the hash table that needs to be occupied before resizing. A hash table with a threshold of 0.6 would resize when 60% of the space is occupied. As a convention, the size of the hashtable is doubled. This can be memory intensive.
Time Complexity
| Operation | Average | Worst |
|---|---|---|
| Search | O(1) | O(n) |
| Insertion | O(1) | O(n) |
| Deletion | O(1) | O(n) |
| Space | O(n) | O(n) |
Strengths:
- Fast lookups. Lookups take time on average.
- Flexible keys. Most data types can be used for keys, as long as they’re hashable .
Weaknesses:
- Slow worst-case lookups. Lookups take time in the worst case .
- Unordered. Keys aren’t stored in a special order. If you’re looking for the smallest key, the largest key, or all the keys in a range, you’ll need to look through every key to find it.
- Single-directional lookups. While you can look up the value for a given key in time, looking up the keys for a given value requires looping through the whole dataset— time.
- Not cache-friendly. Many hash table implementations use linked lists , which don’t put data next to each other in memory.
public class MyHashMap<K, V> {
private int size = 10;
private MapNode<K, V>[] array = new MapNode[size];
public void put(K key, V value) {
int arrayIndex = hash(key);
putVal(key, value, arrayIndex);
}
private int hash(K key) {
int a = 20;
int b = 30;
int primeNumber = 101;
int m = size;
int h = key.hashCode();
return ((a * h * b) % primeNumber) % m;
}
public V get(K key) {
int arrayIndex = hash(key);
MapNode<K, V> head = array[arrayIndex];
if (head == null) {
return null;
}
MapNode<K, V> currentNode = head;
while (null != currentNode && !currentNode.getKey().equals(key)) {
currentNode = currentNode.getNext();
}
if (currentNode == null) {
return null;
} else {
return currentNode.getValue();
}
}
public void putVal(K key, V val, int arrayIndex) {
MapNode<K, V> head = array[arrayIndex];
if (head == null) {
array[arrayIndex] = head = new MapNode<>(key, val);
} else {
MapNode<K, V> currentNode = head;
MapNode<K, V> prevNode = head;
while (null != currentNode && !currentNode.getKey().equals(key)) {
prevNode = currentNode;
currentNode = currentNode.getNext();
}
if (currentNode == null) {
currentNode = new MapNode<>(key, val);
prevNode.setNext(currentNode);
} else {
currentNode.setValue(val);
}
}
}
}
@AllArgsConstructor
@ToString
@Data
public class MapNode<K, V> {
private K key;
private V value;
private MapNode<K, V> next;
public MapNode(K key, V value) {
this(key, value, null);
}
}
Graph
A graph data structure is a collection of nodes that have data and are connected to other nodes.
Let’s try to understand this through an example. On facebook, everything is a node. That includes User, Photo, Album, Event, Group, Page, Comment, Story, Video, Link, Note…anything that has data is a node.
Every relationship is an edge from one node to another. Whether you post a photo, join a group, like a page, etc., a new edge is created for that relationship.
A graph is a pair (V, E), where V is a set of nodes, called vertices, and E is a collection of pairs of vertices, called edges.
Applications of Graphs
- Representing relationships between components in electronic circuits
- Transportation networks: Highway network, Flight network
- Computer networks: Local area network, Internet, Web
- Databases: For representing ER (Entity Relationship) diagrams in databases, for
representing dependency of tables in databases
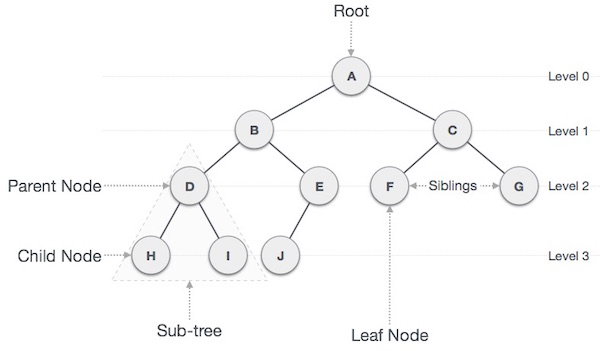
Trees
Tree is a data structure similar to a linked list but instead of each node pointing simply to the next node in a linear fashion, each node points to a number of nodes. Tree is an example of non- linear data structures. A tree structure is a way of representing the hierarchical nature of a structure in a graphical form.
A tree is a collection of entities called nodes. Nodes are connected by edges. Each node contains a value or data, and it may or may not have a child node
The first node of the tree is called the root. If this root node is connected by another node, the root is then a parent node and the connected node is a child.
Tree Properties:
- Root is the topmost
nodeof thetree - Edge is the link between two
nodes - Child is a
nodethat has aparent node - Parent is a
nodethat has anedgeto achild node - Leaf is a
nodethat does not have achild nodein thetree - Height is the length of the longest path to a
leaf - Depth is the length of the path to its
root
General Tree
A general tree is a tree data structure where there are no constraints on the hierarchical structure.
Properties
- Follow properties of a tree.
- A node can have any number of children.
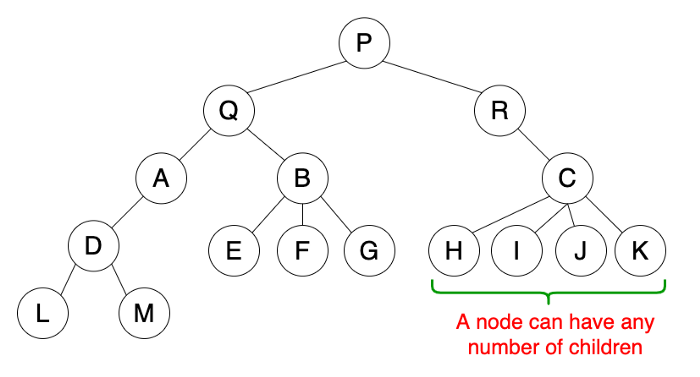
Usage
- Used to store hierarchical data such as folder structures.
Types of Tree
- Binary Tree
- Binary Search Tree
- AVL Tree
- B-Tree
Binary Tree
A tree is called binary tree if each node has zero child, one child or two children. Empty tree is also a valid binary tree. We can visualize a binary tree as consisting of a root and two disjoint binary trees, called the left and right subtrees of the root.
Properties
- Follow properties of a tree.
- A node can have at most two child nodes (children).
- These two child nodes are known as the left child and right child.
-
A left child precedes a right child in the order of children of a node. Or in other others, left side of tree is small than right side of tree
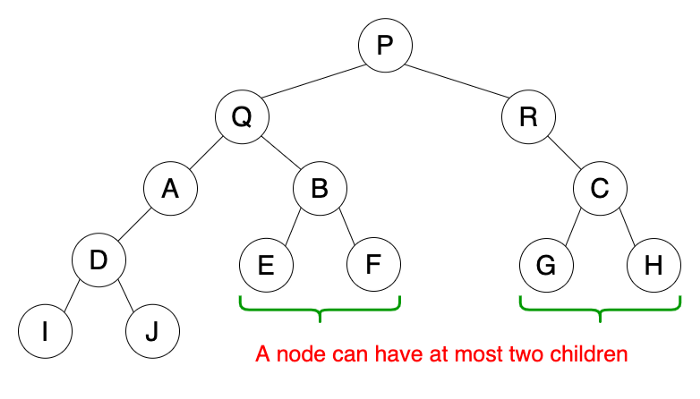
Usage
- Used by compilers to build syntax trees.
- Used to implement expression parsers and expression solvers.
- Used to store router-tables in routers.
Note that Strict Binary Tree is a binary tree with each node has exactly two children or no children.
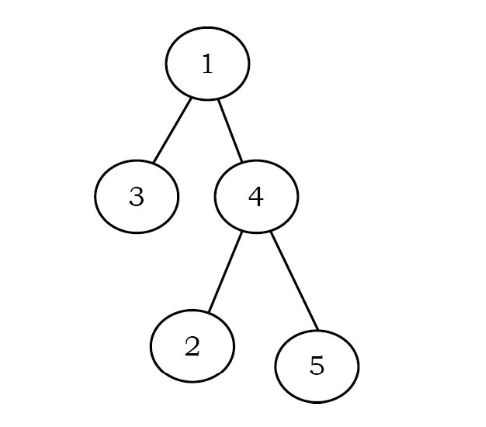
Full Binary Tree
A binary tree is called full binary tree if each node has exactly two children and all leaf nodes are at the same level.
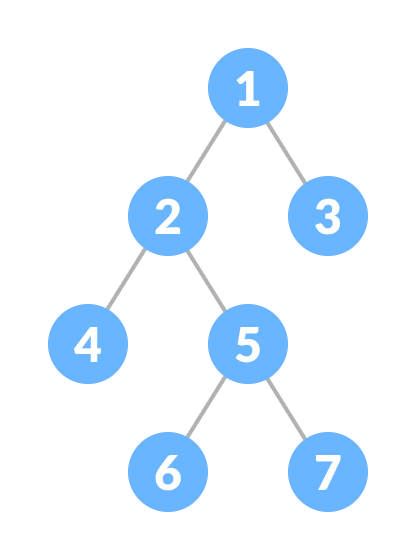
Complete Binary Tree
A complete binary tree is a binary tree in which every level, except possibly the last, is completely filled, and all nodes are as far left as possible.
Properties
1. Every level is filled, except the last level.
2. All nodes are filled starting from left
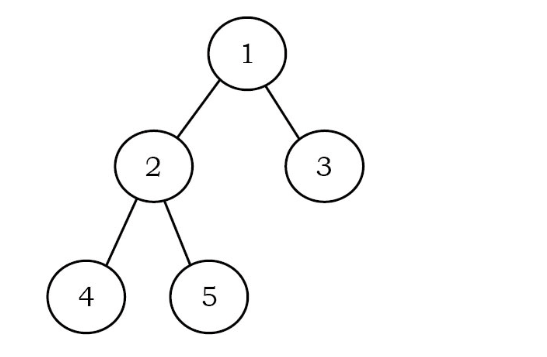
Applications of Binary Trees
Following are the some of the applications where binary trees play an important role:
-
- Expression trees are used in compilers.
- Huffman coding trees that are used in data compression algorithms.
- Binary Search Tree (BST), which supports search, insertion and deletion on a collection of items in O(logn) (average).
- Priority Queue (PQ), which supports search and deletion of minimum (or maximum)on a collection of items in logarithmic time (in worst case).
- Binary Search Trees(BSTs) are used to quickly check whether an element is present in a set or not.
- Heap is a kind of tree that is used for heap sort.
- A modified version of a tree called Tries is used in modern routers to store routing information.
- Most popular databases use B-Trees and T-Trees, which are variants of the tree structure we learned above to store their data
- Compilers use a syntax tree to validate the syntax of every program you write.
- In HTML, the Document Object Model (DOM) works as a tree.
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
public class TreeNode {
private User data;
private TreeNode left;
private TreeNode right;
public TreeNode(User data) {
this.data = data;
}
}
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Data
class User implements Serializable, Comparable<User> {
/**
*
*/
private static final long serialVersionUID = 1L;
private String name;
private Integer rating;
@Override
public int compareTo(User other) {
// TODO Auto-generated method stub
return this.rating.compareTo(other.getRating());
}
}
Insert data into Binary Tree
public TreeNode insert(TreeNode parent, User data) {
/**
* if node is null, put the data there
*/
if (parent == null) {
return new TreeNode(data);
}
User parentData = parent.getData();
/**
* if parent is greater than new node, go left<br>
* if parent is less than new node, go right<br>
*/
if (parentData.getRating() > data.getRating()) {
parent.setLeft(insert(parent.getLeft(), data));
} else {
parent.setRight(insert(parent.getRight(), data));
}
return parent;
}
public TreeNode insert(User data) {
if(root==null) {
root = new TreeNode(data);
return root;
}
return insert(root,data);
}
public class BinaryTreeMain {
public static void main(String[] args) {
// TODO Auto-generated method stub
TreeNode root = new TreeNode();
root.setData(new User("Folau", 20));
BinaryTree binaryTree = new BinaryTree(root);
binaryTree.insert(new User("Lisa", 30));
binaryTree.insert(new User("Laulau", 15));
binaryTree.insert(new User("Kinga", 12));
binaryTree.insert(new User("Fusi", 35));
binaryTree.insert(new User("Nesi", 34));
binaryTree.insert(new User("Melenesi", 32));
System.out.println("PreOrder Traversal");
binaryTree.preOrder(root, "root");
System.out.println("InOrder Traversal");
binaryTree.inOrder(root);
System.out.println("PostOrder Traversal");
binaryTree.postOrder(root);
}
}
PreOrder Traversal root - User(name=Folau, rating=20) left - User(name=Laulau, rating=15) left - User(name=Kinga, rating=12) right - User(name=Lisa, rating=30) right - User(name=Fusi, rating=35) left - User(name=Nesi, rating=34) left - User(name=Melenesi, rating=32) InOrder Traversal User(name=Kinga, rating=12) User(name=Laulau, rating=15) User(name=Folau, rating=20) User(name=Lisa, rating=30) User(name=Melenesi, rating=32) User(name=Nesi, rating=34) User(name=Fusi, rating=35) PostOrder Traversal User(name=Kinga, rating=12) User(name=Laulau, rating=15) User(name=Melenesi, rating=32) User(name=Nesi, rating=34) User(name=Fusi, rating=35) User(name=Lisa, rating=30) User(name=Folau, rating=20)
Now that inserting elements into binary tree is done. We have ways to navigate through or traverse a tree data structure.
We have two options. Breadth-First Search(BFS) and Depth-First Search(DFS)
Depth-First Search
DFS is an algorithm for traversing or searching tree data structure. One starts at the root and explores as far as possible along each branch before backtracking.
DFS explores a path all the way to a leaf before backtracking and exploring another path. There 3 types of DFS: pre-order, in-order, and post-order
Inorder traversal
- First, visit all the nodes in the left subtree
- Then the root node
- Visit all the nodes in the right subtree
Time Complexity: O(n). Space Complexity: O(n)
/**
* 1. Traverse the left subtree in Inorder.<br>
* 2. Visit the root.<br>
* 3. Traverse the right subtree in Inorder.<br>
* Time Complexity: O(n). Space Complexity: O(n).<br>
*/
public void inOrder(TreeNode node) {
if (node != null) {
inOrder(node.getLeft());
System.out.println(node.getData().toString());
inOrder(node.getRight());
}
}
Preorder traversal
- Visit root node
- Visit all the nodes in the left subtree
- Visit all the nodes in the right subtree
Time Complexity: O(n). Space Complexity: O(n)
/**
* 1. Visit the root.<br>
* 2. Traverse the left subtree in Preorder.<br>
* 3. Traverse the right subtree in Preorder.<br>
* Time Complexity: O(n). Space Complexity: O(n).
*/
public void preOrder(TreeNode node) {
if (node != null) {
System.out.println(node.getData().toString());
preOrder(node.getLeft());
preOrder(node.getRight());
}
}
Postorder traversal
- Visit all the nodes in the left subtree
- Visit all the nodes in the right subtree
- Visit the root node
Time Complexity: O(n). Space Complexity: O(n).
/**
* 1. Traverse the left subtree in Postorder.<br>
* 2. Traverse the right subtree in Postorder.<br>
* 3. Visit the root.<br>
* Time Complexity: O(n). Space Complexity: O(n).<br>
*/
public void postOrder(TreeNode node) {
if (node != null) {
postOrder(node.getLeft());
postOrder(node.getRight());
System.out.println(node.getData().toString());
}
}
Breadth-First Search
BFS is an algorithm for traversing or searching tree data structure. It starts at the tree root and explores the neighbor nodes first, before moving to the next level neighbors.
BFS algorithm traverses the tree level by level and depth by depth.
public void bfs() {
int level = 1;
queue.add(new LevelNode(root, level));
while (queue.isEmpty() != true) {
LevelNode levelNode = queue.poll();
TreeNode node = levelNode.getNode();
level++;
// 1. process node
System.out.println("level: "+levelNode.getLevel()+", data: "+ node.getData().toString());
// 2. push left and right child nodes onto queue
if(node.getLeft()!=null) {
queue.add(new LevelNode(node.getLeft(), level));
}
if(node.getRight()!=null) {
queue.add(new LevelNode(node.getRight(), level));
}
}
}