Memory(Stack vs Heap)
What is RAM?
Computer random access memory (RAM) is one of the most important components in determining your system’s performance. RAM gives applications a place to store and access data on a short-term basis. It stores the information your computer is actively using so that it can be accessed quickly.
The more programs your system is running, the more you’ll need RAM. The speed and performance of your system directly correlate to the amount of RAM you have installed. If your system has too little RAM, it can be slow and sluggish.
In this article, we are discussing Stack vs Heap which is that Stack is used for static memory allocation and Heap for dynamic memory allocation, both stored in the RAM.
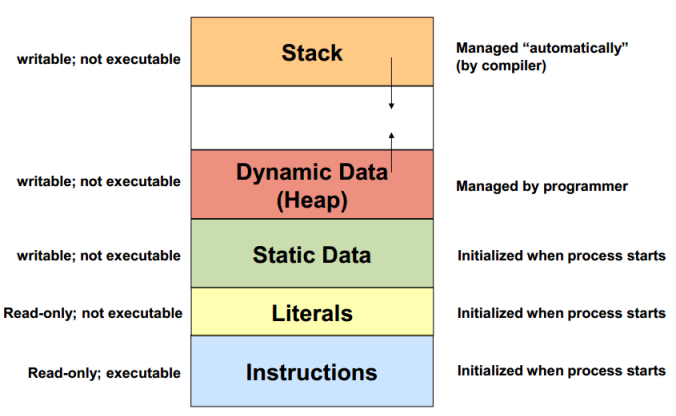
What is Memory?
Memory in a computer is just a sequential set of “buckets” that can contain numbers, characters, or boolean values. By using several buckets in a row, we get arrays. By giving names to a set of contiguous buckets, we get a “structure”. But at its core, a computer memory is a very simple list of numbers. Everything else must be built up upon this.
Memory Layout
- Memory is laid out in sequential order basically from 0 on up (one byte at a time). Each position in memory has a number (called its address!).
- The compiler (or interpreter) associates your variable names with memory addresses.
- In some languages like C, you can actually ask the computer for the address of a variable in memory. In C this is done using the ampersand &In many languages, the actual address is hidden from you and is of little use to you, as all the access methods “abstract” the details of the computer hardware away, allowing the programmer to concentrate on the algorithm, and not the details.
- Arrays variables simply contain the address of the first element of the array. Arrays are zero based so the address simply becomes the base address plus the index.
- Structure variables simply contain the address of the first element of the structure, and each “named” field of the structure forms an offset from the first bucket. The computer keeps track of this offset so that the programmer can use symbolic names instead of numbers.
- Memory buckets are 8 bits long (or one byte). A character (char) is one byte. An integer is (usually) four bytes. A float is four bytes. A double is 8 bytes.
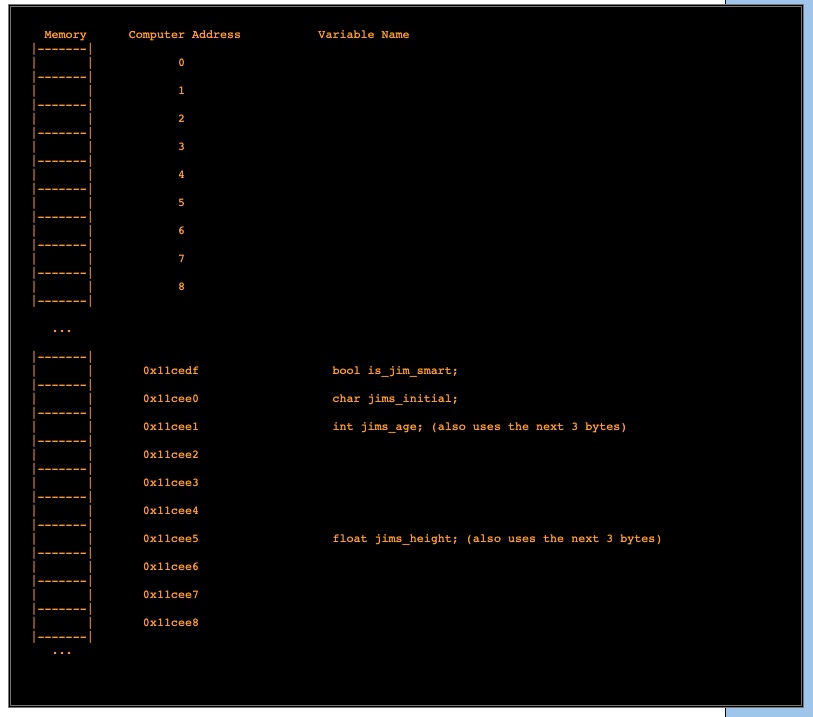
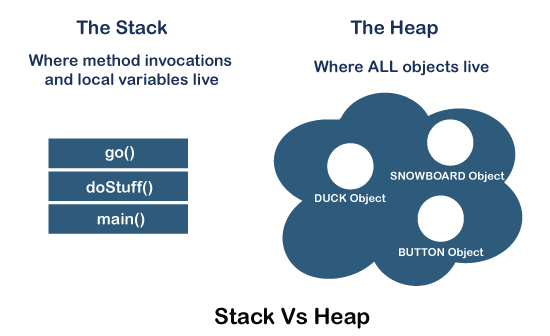
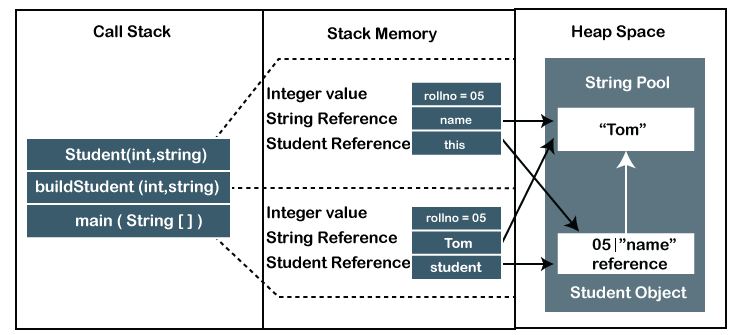
What is a Stack?
A stack is a special area of computer’s memory which stores temporary variables created by a function. In stack, variables are declared, stored and initialized during runtime.
It is a temporary storage memory. When the computing task is complete, the memory of the variable will be automatically erased. The stack section mostly contains methods, local variable, and reference variables.
The stack is a LIFO (Last-In-First-Out) data structure. You can view it as a box of perfectly fitted books — the last book you place is the first one you take out. By using this structure, the program can easily manage all its operations and scopes by using two simple operations: push and pop.
These two do exactly the opposite of each other. Push inserts the value to the top of the stack. Pop takes the top value from it.
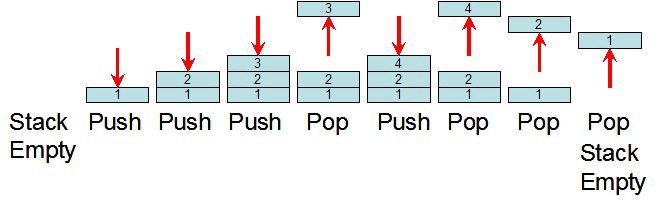
To keep track of the current memory place, there is a special processor register called Stack Pointer. Every time you need to save something — like a variable or the return address from a function — it pushes and moves the stack pointer up. Every time you exit from a function, it pops everything from the stack pointer until the saved return address from the function. It’s simple!
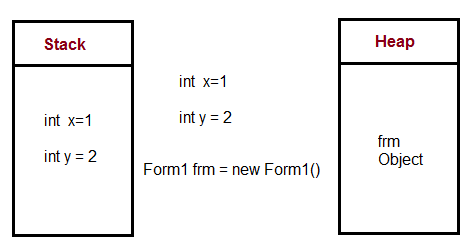
What is a Heap?
The heap is a memory used by programming languages to store global variables. By default, all global variable are stored in heap memory space. It supports Dynamic memory allocation.
Heap is created when the JVM starts up and used by the application as long as the application runs. It stores objects and JRE classes. Whenever we create objects it occupies space in the heap memory while the reference of that object creates in the stack. It does not follow any order like the stack. It dynamically handles the memory blocks. It means, we need not to handle the memory manually.
For managing the memory automatically, Java provides the garbage collector that deletes the objects which are no longer being used. Memory allocated to heap lives until any one event, either program terminated or memory free does not occur. The elements are globally accessible in the application. It is a common memory space shared with all the threads. If the heap space is full, it throws the java.lang.OutOfMemoryError.
Differences between Stack and Heap
| Parameter | Stack Memory | Heap Space |
|---|---|---|
| Application | It stores items that have a very short life such as methods, variables, and reference variables of the objects. | It stores objects and Java Runtime Environment (JRE) classes. |
| Ordering | It follows the LIFO order. | It does not follow any order because it is a dynamic memory allocation and does not have any fixed pattern for allocation and deallocation of memory blocks. |
| Flexibility | It is not flexible because we cannot alter the allocated memory. | It is flexible because we can alter the allocated memory. |
| Efficiency | It has faster access, allocation, and deallocation. | It has slower access, allocation, and deallocation. |
| Memory Size | It is smaller in size. | It is larger in size. |
| Java Options Used | We can increase the stack size by using the JVM option -Xss. | We can increase or decrease the heap memory size by using the –Xmx and -Xms JVM options. |
| Visibility or Scope | The variables are visible only to the owner thread. | It is visible to all threads. |
| Generation of Space | When a thread is created, the operating system automatically allocates the stack. | To create the heap space for the application, the language first calls the operating system at run time. |
| Distribution | Separate stack is created for each object. | It is shared among all the threads. |
| Exception Throws | JVM throws the java.lang.StackOverFlowError if the stack size is greater than the limit. To avoid this error, increase the stack size. | JVM throws the java.lang.OutOfMemoryError if the JVM is unable to create a new native method. |
| Allocation/ Deallocation | It is done automatically by the compiler. | It is done manually by the programmer. |
| Cost | Its cost is less. | Its cost is more in comparison to stack. |
| Implementation | Its implementation is hard. | Its implementation is easy. |
| Order of allocation | Memory allocation is continuous. | Memory allocated in random order. |
| Thread-Safety | It is thread-safe because each thread has its own stack. | It is not thread-safe, so properly synchronization of code is required. |
Array
Array is a data structure that holds a fixed number of values (data points) of the same data type. Each item, or value, is called an element. When we initialize an array, we get to choose what type of data(data type) it can hold and how many elements(length) it can hold.
Each position in the array has an index, starting at 0.
The items in an array are allocated at adjacent(next to each other) memory locations.
By default, an array are filled with default value of its data type once it’s initialized. For example an array of int will have 0 as the default value.
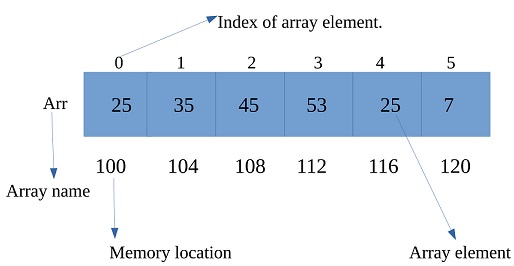
From the above image:
- data type – integer
- length – 6
- array name – Arr
- first index – 25
- last index – 7
int[] arr = new int[6];
arr[0] = 25;
arr[1] = 35;
arr[2] = 45;
arr[3] = 53;
arr[4] = 25;
arr[5] = 7;
System.out.println("length: " + arr.length);
System.out.println(Arrays.toString(arr));
arr = new int[]{25, 35, 45, 53, 25, 7};
System.out.println("length: " + arr.length);
System.out.println(Arrays.toString(arr));
length: 6 [25, 35, 45, 53, 25, 7] length: 6 [25, 35, 45, 53, 25, 7]
Worst Case(Big O)
| space | |
|---|---|
| lookup | |
| append(last element) | |
| insert | |
| delete |
Advantages
- Fast lookups – retrieving an element at a given index takes time, regardless of the length of the array.
- Fast appends – adding a new element at the end of the array takes time, if the array has space.
- An array can store multiple values in a single variable.
- Arrays are fast as compared to primitive data types.
- We can store objects in an array.
- Members of the array are stored in consecutive memory locations.
Disadvantages
- Fixed size. You need to specify how many elements you’re going to store in your array ahead of time. (Unless you’re using a fancy dynamic array.)
- Costly inserts and deletes. You have to “scoot over” the other elements to fill in or close gaps , which takes worst-case time.
- We cannot increase or decrease the size of the array at runtime.
- In array, memory wastage can be more.
- We can only store similar data type items.
Inserting elements into an Array
If we want to insert something into an array, first we have to make space by “scooting over” everything starting at the index we’re inserting into.
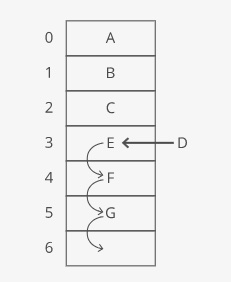
In the worst case we’re inserting into the 0th index in the array (prepending), so we have to “scoot over” everything in the array. That’s time.
In java
If we want to insert something into an array, first we must have the index or position where the element is going to. Once we have the position, we just set it.
In the worst case the time complexity is time.
Deleting elements from an Array
Array elements are stored adjacent to each other. So when we remove an element, we have to fill in the gap—”scooting over” all the elements that were after it.
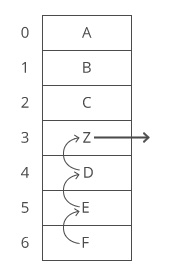
In the worst case we’re deleting the 0th item in the array, so we have to “scoot over” everything else in the array. That’s O(n) time.
Why not just leave the gap? Because the quick lookup power of arrays depends on everything being sequential and uninterrupted. This lets us predict exactly how far from the start of the array the 138th or 9,203rd item is. If there are gaps, we can no longer predict exactly where each array item will be.
In java
If we want to delete an element from an array, first we must have the index or position where the element is in. Once we have the position, we just set it to its data type default value, 0 or null. FYI, there is no Delete operation available on Arrays. We can symbolically delete an element by setting it to some specific value, e.g. -1, 0, etc. depending on our requirements
In the worst case the time complexity is time.
Git Pull Request
A pull request is a request asking your upstream project to pull changes into their tree. The request, printed to the standard output, begins with the branch description, summarizes the changes and indicates from where they can be pulled.
The upstream project is expected to have the commit named by <start> and the output asks it to integrate the changes you made since that commit, up to the commit named by <end>, by visiting the repository named by <url>.
git request-pull [-p] <start> <url> [<end>]
Greedy Algorithms
A greedy algorithm always makes the best choice at the moment. This means that it makes a locally-optimal choice in the hope that this choice will lead to a globally-optimal solution. Greedy algorithms work in stages. In each stage, a decision is made that is good at that point, without bothering about the future.
For example, you can greedily approach your life. You can always take the path that maximizes your happiness today. But that doesn’t mean you’ll be happier tomorrow.
In general, they are computationally cheaper than other families of algorithms like dynamic programming, or brute force. This is because they don’t explore the solution space too much. And, for the same reason, they don’t find the best solution to a lot of problems.
To solve a problem based on the greedy approach, there are two stages
- Scanning the list of items
- Optimization
How do you decide which choice is optimal?
Assume that you have a function that needs to be optimized (either maximized or minimized) at a given point. A Greedy algorithm makes greedy choices at each step to ensure that the objective function is optimized. The Greedy algorithm has only one shot to compute the optimal solution so that it never goes back and reverses the decision.
Advantages of Greedy Algorithm
- The main advantage of the Greedy method is that it is straightforward, easy to understand and easy to code. In Greedy algorithms, once we make a decision, we do not have to spend time re- examining the already computed values.
- Analyzing the run time for greedy algorithms will generally be much easier than for other techniques (like Divide and conquer).
Disadvantages of Greedy Algorithm
- The main disadvantage of Greedy Algorithm is that there is no guarantee that making locally optimal improvements in a locally optimal solution gives the optimal global solution.
- It is not suitable for problems where a solution is required for every subproblem like sorting. In such problems, the greedy strategy can be wrong, in the worst case even lead to a non-optimal solution.
- Even with the correct algorithm, it is hard to prove why it is correct.
Problems best solved by Greedy Algorithm
- Travelling Salesman Problem
- Kruskal’s Minimal Spanning Tree Algorithm
- Dijkstra’s Minimal Spanning Tree Algorithm
- Knapsack Problem
- Job Scheduling Problem
Database
1. What is JDBC?
JDBC (Java Database Connectivity) is Java’s standard API for connecting to and interacting with relational databases. Think of it as the bridge between your Java application and a database — it provides a uniform way to send SQL statements, retrieve results, and manage database connections regardless of which database vendor you use (MySQL, PostgreSQL, Oracle, SQLite, H2, etc.).
Before JDBC, every database vendor had its own proprietary API. If you wrote code for Oracle, you could not reuse it for MySQL without a complete rewrite. JDBC solved this by defining a standard set of interfaces in the java.sql package that every database vendor implements through a driver.
JDBC Architecture
The architecture has four layers:
+---------------------+
| Java Application | <-- Your code
+---------------------+
|
+---------------------+
| JDBC API | <-- java.sql.* interfaces
| (DriverManager, | (Connection, Statement,
| DataSource) | ResultSet, etc.)
+---------------------+
|
+---------------------+
| JDBC Driver | <-- Vendor-specific implementation
| (MySQL Connector/J, | (mysql-connector-j, postgresql, etc.)
| PostgreSQL Driver) |
+---------------------+
|
+---------------------+
| Database | <-- MySQL, PostgreSQL, Oracle, H2, etc.
+---------------------+
Your application only talks to the JDBC API. The driver translates your calls into database-specific protocol. This means you can switch databases by changing the driver and connection URL -- your SQL code stays the same (assuming standard SQL).
Key JDBC Interfaces
| Interface / Class | Package | Purpose |
|---|---|---|
DriverManager |
java.sql |
Manages JDBC drivers, creates connections |
Connection |
java.sql |
Represents a session with the database |
Statement |
java.sql |
Executes static SQL statements |
PreparedStatement |
java.sql |
Executes parameterized (precompiled) SQL |
CallableStatement |
java.sql |
Calls stored procedures |
ResultSet |
java.sql |
Holds query results, row-by-row iteration |
DataSource |
javax.sql |
Factory for connections (preferred over DriverManager in production) |
JDBC Driver Types
There are four types of JDBC drivers, but in modern development you will almost exclusively use Type 4 (Thin Driver):
| Type | Name | Description | Used Today? |
|---|---|---|---|
| Type 1 | JDBC-ODBC Bridge | Translates JDBC calls to ODBC calls | Removed in Java 8 |
| Type 2 | Native-API | Uses native database client libraries | Rare |
| Type 3 | Network Protocol | Middleware translates to database protocol | Rare |
| Type 4 | Thin Driver (Pure Java) | Directly converts JDBC calls to database protocol | Yes -- standard |
Type 4 drivers are pure Java, require no native libraries, and are the easiest to deploy. MySQL Connector/J, PostgreSQL JDBC, and the H2 driver are all Type 4.
2. Setting Up
To use JDBC, you need two things: the java.sql package (included in the JDK) and a JDBC driver for your specific database.
Adding the JDBC Driver Dependency
The driver is a JAR file that you add to your project. Here are the most common ones:
Maven (pom.xml):
com.mysql mysql-connector-j 8.3.0 org.postgresql postgresql 42.7.3 com.h2database h2 2.2.224
Gradle (build.gradle):
// MySQL implementation 'com.mysql:mysql-connector-j:8.3.0' // PostgreSQL implementation 'org.postgresql:postgresql:42.7.3' // H2 implementation 'com.h2database:h2:2.2.224'
Loading the Driver
In older Java code (pre-JDBC 4.0 / pre-Java 6), you had to explicitly load the driver class:
// Legacy approach -- no longer needed since Java 6 / JDBC 4.0
Class.forName("com.mysql.cj.jdbc.Driver");
Class.forName("org.postgresql.Driver");
Since JDBC 4.0, drivers use the Service Provider mechanism (META-INF/services/java.sql.Driver) and are auto-loaded when present on the classpath. You do not need Class.forName() anymore -- just add the dependency and call DriverManager.getConnection().
If you see Class.forName() in production code today, it is legacy code that can be safely removed.
3. Establishing a Connection
A Connection object represents an active session with the database. You create one using DriverManager.getConnection() with a JDBC URL, username, and password.
JDBC URL Format
The URL follows this pattern: jdbc:<subprotocol>://<host>:<port>/<database>?<parameters>
| Database | JDBC URL Example | Default Port |
|---|---|---|
| MySQL | jdbc:mysql://localhost:3306/mydb |
3306 |
| PostgreSQL | jdbc:postgresql://localhost:5432/mydb |
5432 |
| H2 (in-memory) | jdbc:h2:mem:testdb |
N/A |
| H2 (file-based) | jdbc:h2:file:./data/mydb |
N/A |
| Oracle | jdbc:oracle:thin:@localhost:1521:orcl |
1521 |
| SQL Server | jdbc:sqlserver://localhost:1433;databaseName=mydb |
1433 |
Basic Connection (Don't Do This in Production)
The simplest way to connect -- useful for learning, but it has problems we will fix shortly:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class BasicConnection {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydb";
String user = "root";
String password = "secret";
Connection connection = null;
try {
connection = DriverManager.getConnection(url, user, password);
System.out.println("Connected to database!");
System.out.println("Database: " + connection.getCatalog());
System.out.println("Auto-commit: " + connection.getAutoCommit());
// ... use connection ...
} catch (SQLException e) {
System.err.println("Connection failed: " + e.getMessage());
System.err.println("SQL State: " + e.getSQLState());
System.err.println("Error Code: " + e.getErrorCode());
} finally {
// Must close manually -- easy to forget!
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
// Output:
// Connected to database!
// Database: mydb
// Auto-commit: true
Proper Connection with try-with-resources (Always Use This)
Connection, Statement, PreparedStatement, and ResultSet all implement AutoCloseable. This means you should always use try-with-resources to ensure they are closed properly, even when exceptions occur.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ProperConnection {
// Store these in environment variables or a config file, never hardcoded
private static final String URL = "jdbc:mysql://localhost:3306/mydb";
private static final String USER = "root";
private static final String PASSWORD = "secret";
public static void main(String[] args) {
// try-with-resources -- connection auto-closes when block ends
try (Connection conn = DriverManager.getConnection(URL, USER, PASSWORD)) {
System.out.println("Connected!");
System.out.println("Valid: " + conn.isValid(5)); // 5-second timeout
// ... do work ...
} catch (SQLException e) {
// Connection automatically closed, even on exception
System.err.println("Error: " + e.getMessage());
}
// No finally block needed -- connection is guaranteed closed
}
}
Connection with Properties
For more configuration options, pass connection parameters as a Properties object:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Properties;
public class ConnectionWithProperties {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/mydb";
Properties props = new Properties();
props.setProperty("user", "root");
props.setProperty("password", "secret");
props.setProperty("useSSL", "true");
props.setProperty("serverTimezone", "UTC");
props.setProperty("characterEncoding", "UTF-8");
props.setProperty("connectTimeout", "5000"); // 5 seconds
try (Connection conn = DriverManager.getConnection(url, props)) {
System.out.println("Connected with properties!");
} catch (SQLException e) {
System.err.println("Connection failed: " + e.getMessage());
}
}
}
4. Statement vs PreparedStatement
JDBC provides two main ways to execute SQL: Statement and PreparedStatement. Understanding the difference is critical -- using the wrong one is the #1 security mistake in database programming.
Statement -- Simple, Static SQL
Statement executes a raw SQL string. It is fine for static queries with no user input:
import java.sql.*;
public class StatementExample {
public static void main(String[] args) throws SQLException {
try (Connection conn = DriverManager.getConnection(
"jdbc:h2:mem:testdb", "sa", "")) {
Statement stmt = conn.createStatement();
// DDL -- creating a table (no user input, Statement is fine)
stmt.executeUpdate("CREATE TABLE countries (id INT PRIMARY KEY, name VARCHAR(50))");
// Static insert (no user input)
stmt.executeUpdate("INSERT INTO countries VALUES (1, 'United States')");
stmt.executeUpdate("INSERT INTO countries VALUES (2, 'Japan')");
// Static query
ResultSet rs = stmt.executeQuery("SELECT * FROM countries");
while (rs.next()) {
System.out.println(rs.getInt("id") + ": " + rs.getString("name"));
}
}
}
}
// Output:
// 1: United States
// 2: Japan
The SQL Injection Problem
If you ever build SQL by concatenating user input into a Statement, you create a SQL injection vulnerability -- one of the most dangerous and common security flaws in software:
// DANGEROUS -- NEVER DO THIS
public User findUser(String username) throws SQLException {
Statement stmt = conn.createStatement();
// User input is concatenated directly into SQL
String sql = "SELECT * FROM users WHERE username = '" + username + "'";
ResultSet rs = stmt.executeQuery(sql);
// ...
}
// Normal input: username = "john"
// SQL becomes: SELECT * FROM users WHERE username = 'john' <-- works fine
// Malicious input: username = "' OR '1'='1"
// SQL becomes: SELECT * FROM users WHERE username = '' OR '1'='1'
// This returns ALL users!
// Even worse: username = "'; DROP TABLE users; --"
// SQL becomes: SELECT * FROM users WHERE username = ''; DROP TABLE users; --'
// This DELETES your entire users table!
PreparedStatement -- Parameterized, Safe SQL
PreparedStatement solves SQL injection by separating the SQL structure from the data. You write the SQL with ? placeholders, and the driver safely binds the values:
// SAFE -- Always use PreparedStatement for any query involving user input
public User findUser(String username) throws SQLException {
String sql = "SELECT * FROM users WHERE username = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, username); // Parameter index starts at 1
ResultSet rs = pstmt.executeQuery();
// ...
}
}
// Input: username = "' OR '1'='1"
// The driver treats the ENTIRE string as a literal value, not SQL.
// It effectively becomes: WHERE username = '\' OR \'1\'=\'1'
// No injection possible!
Statement vs PreparedStatement Comparison
| Feature | Statement | PreparedStatement |
|---|---|---|
| SQL Injection | Vulnerable when concatenating user input | Immune -- parameters are escaped automatically |
| Performance | Parsed and compiled every execution | Precompiled -- the database caches the execution plan |
| Readability | Messy string concatenation | Clean ? placeholders |
| Type Safety | Everything is string concatenation | Typed setters: setInt(), setDate(), setString() |
| Batch Operations | Supported but slower | Significantly faster with reuse |
| Use Case | DDL (CREATE TABLE, ALTER TABLE), static admin queries | All DML (INSERT, UPDATE, DELETE, SELECT with parameters) |
Rule of thumb: Always use PreparedStatement. The only exception is DDL statements (CREATE TABLE, DROP TABLE) where there are no parameters to bind.
PreparedStatement Setter Methods
| Method | Java Type | SQL Type |
|---|---|---|
setInt(index, value) |
int |
INTEGER |
setLong(index, value) |
long |
BIGINT |
setDouble(index, value) |
double |
DOUBLE |
setString(index, value) |
String |
VARCHAR / TEXT |
setBoolean(index, value) |
boolean |
BOOLEAN / BIT |
setDate(index, value) |
java.sql.Date |
DATE |
setTimestamp(index, value) |
java.sql.Timestamp |
TIMESTAMP / DATETIME |
setBigDecimal(index, value) |
BigDecimal |
DECIMAL / NUMERIC |
setNull(index, sqlType) |
null |
Any (specify with Types.VARCHAR, etc.) |
setObject(index, value) |
Object |
Auto-detected |
5. CRUD Operations
CRUD stands for Create, Read, Update, Delete -- the four fundamental database operations. Let us walk through each one using a users table.
5.1 CREATE Table
Creating a table is a DDL (Data Definition Language) operation. Use executeUpdate() since it does not return a result set:
import java.sql.*;
public class CreateTableExample {
public static void main(String[] args) {
String url = "jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1";
try (Connection conn = DriverManager.getConnection(url, "sa", "")) {
String sql = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL,
age INT,
salary DECIMAL(10,2),
active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""";
try (Statement stmt = conn.createStatement()) {
stmt.executeUpdate(sql);
System.out.println("Table 'users' created successfully.");
}
} catch (SQLException e) {
System.err.println("Error: " + e.getMessage());
}
}
}
// Output:
// Table 'users' created successfully.
5.2 INSERT -- Adding Records
Use PreparedStatement with executeUpdate(). To retrieve the auto-generated ID, pass Statement.RETURN_GENERATED_KEYS:
public class InsertExample {
// Insert a single user and return the generated ID
public static long insertUser(Connection conn, String username, String email,
int age, double salary) throws SQLException {
String sql = "INSERT INTO users (username, email, age, salary) VALUES (?, ?, ?, ?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql,
Statement.RETURN_GENERATED_KEYS)) {
pstmt.setString(1, username);
pstmt.setString(2, email);
pstmt.setInt(3, age);
pstmt.setDouble(4, salary);
int rowsAffected = pstmt.executeUpdate();
System.out.println(rowsAffected + " row(s) inserted.");
// Retrieve the auto-generated key
try (ResultSet generatedKeys = pstmt.getGeneratedKeys()) {
if (generatedKeys.next()) {
long id = generatedKeys.getLong(1);
System.out.println("Generated ID: " + id);
return id;
}
}
}
return -1;
}
public static void main(String[] args) throws SQLException {
try (Connection conn = DriverManager.getConnection(
"jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1", "sa", "")) {
// Create table first (from previous example)
// ...
insertUser(conn, "john_doe", "john@example.com", 28, 75000.00);
insertUser(conn, "jane_smith", "jane@example.com", 32, 92000.00);
insertUser(conn, "bob_wilson", "bob@example.com", 45, 68000.00);
}
}
}
// Output:
// 1 row(s) inserted.
// Generated ID: 1
// 1 row(s) inserted.
// Generated ID: 2
// 1 row(s) inserted.
// Generated ID: 3
5.3 SELECT -- Reading Records
Use executeQuery() which returns a ResultSet. Iterate over it with next():
public class SelectExample {
// Select all users
public static void selectAllUsers(Connection conn) throws SQLException {
String sql = "SELECT id, username, email, age, salary, active, created_at FROM users";
try (PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
System.out.println("--- All Users ---");
while (rs.next()) {
int id = rs.getInt("id");
String username = rs.getString("username");
String email = rs.getString("email");
int age = rs.getInt("age");
double salary = rs.getDouble("salary");
boolean active = rs.getBoolean("active");
Timestamp createdAt = rs.getTimestamp("created_at");
System.out.printf("ID: %d | %s | %s | Age: %d | $%.2f | Active: %b | %s%n",
id, username, email, age, salary, active, createdAt);
}
}
}
// Select with a WHERE clause
public static void selectUserByUsername(Connection conn, String username) throws SQLException {
String sql = "SELECT * FROM users WHERE username = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, username);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
System.out.println("Found: " + rs.getString("username")
+ " (" + rs.getString("email") + ")");
} else {
System.out.println("User not found: " + username);
}
}
}
}
// Select with multiple conditions
public static void selectUsersAboveSalary(Connection conn, double minSalary)
throws SQLException {
String sql = "SELECT username, salary FROM users WHERE salary > ? AND active = ? ORDER BY salary DESC";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, minSalary);
pstmt.setBoolean(2, true);
try (ResultSet rs = pstmt.executeQuery()) {
System.out.println("Users earning above $" + minSalary + ":");
while (rs.next()) {
System.out.printf(" %s: $%.2f%n",
rs.getString("username"), rs.getDouble("salary"));
}
}
}
}
}
// Output:
// --- All Users ---
// ID: 1 | john_doe | john@example.com | Age: 28 | $75000.00 | Active: true | 2024-01-15 10:30:00.0
// ID: 2 | jane_smith | jane@example.com | Age: 32 | $92000.00 | Active: true | 2024-01-15 10:30:00.0
// ID: 3 | bob_wilson | bob@example.com | Age: 45 | $68000.00 | Active: true | 2024-01-15 10:30:00.0
//
// Found: john_doe (john@example.com)
//
// Users earning above $70000.0:
// jane_smith: $92000.00
// john_doe: $75000.00
5.4 UPDATE -- Modifying Records
Use executeUpdate() which returns the number of affected rows. Always check this value to confirm the operation succeeded:
public class UpdateExample {
public static int updateUserEmail(Connection conn, int userId, String newEmail)
throws SQLException {
String sql = "UPDATE users SET email = ? WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, newEmail);
pstmt.setInt(2, userId);
int rowsAffected = pstmt.executeUpdate();
if (rowsAffected > 0) {
System.out.println("Updated email for user ID " + userId);
} else {
System.out.println("No user found with ID " + userId);
}
return rowsAffected;
}
}
public static int giveRaise(Connection conn, double percentage, double minCurrentSalary)
throws SQLException {
String sql = "UPDATE users SET salary = salary * (1 + ? / 100) WHERE salary >= ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, percentage);
pstmt.setDouble(2, minCurrentSalary);
int rowsAffected = pstmt.executeUpdate();
System.out.println(rowsAffected + " user(s) received a " + percentage + "% raise.");
return rowsAffected;
}
}
}
// Output:
// Updated email for user ID 1
// 2 user(s) received a 10.0% raise.
5.5 DELETE -- Removing Records
Delete operations also use executeUpdate(). Be very careful -- always use a WHERE clause unless you intentionally want to delete all rows:
public class DeleteExample {
public static int deleteUser(Connection conn, int userId) throws SQLException {
String sql = "DELETE FROM users WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, userId);
int rowsAffected = pstmt.executeUpdate();
if (rowsAffected > 0) {
System.out.println("Deleted user with ID " + userId);
} else {
System.out.println("No user found with ID " + userId);
}
return rowsAffected;
}
}
// Soft delete -- better practice than hard delete
public static int deactivateUser(Connection conn, int userId) throws SQLException {
String sql = "UPDATE users SET active = false WHERE id = ? AND active = true";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, userId);
int rowsAffected = pstmt.executeUpdate();
System.out.println(rowsAffected > 0 ? "User deactivated." : "User not found or already inactive.");
return rowsAffected;
}
}
}
// Output:
// Deleted user with ID 3
// User deactivated.
Execute Method Summary
| Method | Returns | Use For |
|---|---|---|
executeQuery(sql) |
ResultSet |
SELECT statements |
executeUpdate(sql) |
int (rows affected) |
INSERT, UPDATE, DELETE, DDL |
execute(sql) |
boolean (true if ResultSet) |
When you do not know the SQL type at compile time |
6. ResultSet in Detail
A ResultSet is a table of data returned by a query. It maintains an internal cursor pointing to the current row. The cursor starts before the first row, so you must call next() to move to the first row.
Navigating a ResultSet
public class ResultSetNavigation {
public static void main(String[] args) throws SQLException {
try (Connection conn = DriverManager.getConnection("jdbc:h2:mem:testdb", "sa", "")) {
// Setup
Statement setup = conn.createStatement();
setup.executeUpdate("CREATE TABLE products (id INT, name VARCHAR(50), price DECIMAL(10,2))");
setup.executeUpdate("INSERT INTO products VALUES (1, 'Laptop', 999.99)");
setup.executeUpdate("INSERT INTO products VALUES (2, 'Mouse', 29.99)");
setup.executeUpdate("INSERT INTO products VALUES (3, 'Keyboard', 79.99)");
// Basic forward-only iteration
try (PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM products");
ResultSet rs = pstmt.executeQuery()) {
// Access by column name (preferred -- more readable)
while (rs.next()) {
String name = rs.getString("name");
double price = rs.getDouble("price");
System.out.println(name + ": $" + price);
}
}
// Access by column index (1-based, faster but fragile)
try (PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM products");
ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
int id = rs.getInt(1); // column 1
String name = rs.getString(2); // column 2
double price = rs.getDouble(3); // column 3
System.out.println(id + ". " + name + ": $" + price);
}
}
}
}
}
// Output:
// Laptop: $999.99
// Mouse: $29.99
// Keyboard: $79.99
// 1. Laptop: $999.99
// 2. Mouse: $29.99
// 3. Keyboard: $79.99
Handling NULL Values
When a database column is NULL, JDBC getter methods return a default value for primitives (0 for numbers, false for boolean). Use wasNull() to check:
// If age column is NULL in the database:
int age = rs.getInt("age"); // Returns 0 (not null, because int is a primitive)
boolean wasNull = rs.wasNull(); // Returns true -- the actual value was NULL
// Better approach: use wrapper types with getObject()
Integer age = rs.getObject("age", Integer.class); // Returns null if column is NULL
if (age == null) {
System.out.println("Age not provided");
} else {
System.out.println("Age: " + age);
}
// For String, getString() already returns null for NULL columns
String email = rs.getString("email"); // Returns null if column is NULL
ResultSet Types
By default, a ResultSet is forward-only. You can request a scrollable ResultSet when creating the statement:
| ResultSet Type | Scroll? | See Updates? | Description |
|---|---|---|---|
TYPE_FORWARD_ONLY |
No | No | Default. Cursor moves forward only. Most efficient. |
TYPE_SCROLL_INSENSITIVE |
Yes | No | Can scroll in any direction. Snapshot at query time. |
TYPE_SCROLL_SENSITIVE |
Yes | Yes | Reflects changes made by others. Rarely supported well. |
// Create a scrollable ResultSet
try (PreparedStatement pstmt = conn.prepareStatement(
"SELECT * FROM products",
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY)) {
ResultSet rs = pstmt.executeQuery();
// Move to last row
rs.last();
System.out.println("Last product: " + rs.getString("name"));
System.out.println("Total rows: " + rs.getRow());
// Move to first row
rs.first();
System.out.println("First product: " + rs.getString("name"));
// Move to a specific row
rs.absolute(2);
System.out.println("Second product: " + rs.getString("name"));
// Move relative to current position
rs.relative(-1); // one row back
System.out.println("Back to first: " + rs.getString("name"));
}
// Output:
// Last product: Keyboard
// Total rows: 3
// First product: Laptop
// Second product: Mouse
// Back to first: Laptop
ResultSetMetaData
When you need to inspect the structure of a result set dynamically (column names, types, count):
try (PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM users");
ResultSet rs = pstmt.executeQuery()) {
ResultSetMetaData meta = rs.getMetaData();
int columnCount = meta.getColumnCount();
// Print column info
System.out.println("Columns in result set:");
for (int i = 1; i <= columnCount; i++) {
System.out.printf(" %s (%s) - Nullable: %s%n",
meta.getColumnName(i),
meta.getColumnTypeName(i),
meta.isNullable(i) == ResultSetMetaData.columnNullable ? "Yes" : "No");
}
// Print all data dynamically
while (rs.next()) {
for (int i = 1; i <= columnCount; i++) {
System.out.print(meta.getColumnName(i) + "=" + rs.getObject(i) + " | ");
}
System.out.println();
}
}
// Output:
// Columns in result set:
// ID (INTEGER) - Nullable: No
// USERNAME (VARCHAR) - Nullable: No
// EMAIL (VARCHAR) - Nullable: No
// AGE (INTEGER) - Nullable: Yes
// SALARY (DECIMAL) - Nullable: Yes
// ACTIVE (BOOLEAN) - Nullable: Yes
// CREATED_AT (TIMESTAMP) - Nullable: Yes
7. Transactions
A transaction groups multiple SQL operations into a single unit of work that either all succeed or all fail. Think of transferring money between bank accounts -- you cannot debit one account without crediting the other.
ACID Properties
| Property | Meaning | Example |
|---|---|---|
| Atomicity | All operations succeed or all are rolled back | Transfer: debit AND credit both happen, or neither does |
| Consistency | Database moves from one valid state to another | Total money across accounts stays the same |
| Isolation | Concurrent transactions do not interfere | Two transfers at the same time produce correct results |
| Durability | Committed data survives system crashes | Once "transfer complete" is shown, it is saved permanently |
Auto-Commit Mode
By default, JDBC runs in auto-commit mode -- every SQL statement is automatically committed as soon as it executes. This means each statement is its own transaction. For multi-statement transactions, you must disable auto-commit:
import java.sql.*;
public class TransactionExample {
public static void transferMoney(Connection conn, int fromAccountId,
int toAccountId, double amount) throws SQLException {
// Save auto-commit state to restore later
boolean originalAutoCommit = conn.getAutoCommit();
try {
// Step 1: Disable auto-commit -- starts a transaction
conn.setAutoCommit(false);
// Step 2: Debit from source account
String debitSql = "UPDATE accounts SET balance = balance - ? WHERE id = ? AND balance >= ?";
try (PreparedStatement debit = conn.prepareStatement(debitSql)) {
debit.setDouble(1, amount);
debit.setInt(2, fromAccountId);
debit.setDouble(3, amount);
int rows = debit.executeUpdate();
if (rows == 0) {
throw new SQLException("Insufficient funds or account not found: " + fromAccountId);
}
}
// Step 3: Credit to destination account
String creditSql = "UPDATE accounts SET balance = balance + ? WHERE id = ?";
try (PreparedStatement credit = conn.prepareStatement(creditSql)) {
credit.setDouble(1, amount);
credit.setInt(2, toAccountId);
int rows = credit.executeUpdate();
if (rows == 0) {
throw new SQLException("Destination account not found: " + toAccountId);
}
}
// Step 4: Both operations succeeded -- commit
conn.commit();
System.out.printf("Transferred $%.2f from account %d to account %d%n",
amount, fromAccountId, toAccountId);
} catch (SQLException e) {
// Step 5: Something went wrong -- rollback ALL changes
conn.rollback();
System.err.println("Transfer failed, rolled back: " + e.getMessage());
throw e;
} finally {
// Restore original auto-commit state
conn.setAutoCommit(originalAutoCommit);
}
}
}
// Output (success):
// Transferred $500.00 from account 1 to account 2
//
// Output (failure):
// Transfer failed, rolled back: Insufficient funds or account not found: 1
Savepoints
Savepoints let you roll back part of a transaction without undoing everything. They act as checkpoints within a transaction:
public static void processOrderWithSavepoint(Connection conn) throws SQLException {
conn.setAutoCommit(false);
Savepoint orderSavepoint = null;
try {
// Insert the order
try (PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO orders (customer_id, total) VALUES (?, ?)")) {
pstmt.setInt(1, 42);
pstmt.setDouble(2, 299.99);
pstmt.executeUpdate();
}
// Mark a savepoint after the order is created
orderSavepoint = conn.setSavepoint("afterOrder");
// Try to insert shipping info (might fail)
try {
try (PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO shipping (order_id, address) VALUES (?, ?)")) {
pstmt.setInt(1, 1);
pstmt.setString(2, "123 Main St");
pstmt.executeUpdate();
}
} catch (SQLException e) {
// Shipping failed -- roll back to savepoint (order is still intact)
conn.rollback(orderSavepoint);
System.out.println("Shipping failed, but order preserved. Will ship later.");
}
conn.commit();
System.out.println("Order processed successfully.");
} catch (SQLException e) {
conn.rollback(); // Roll back everything
throw e;
} finally {
conn.setAutoCommit(true);
}
}
// Output:
// Order processed successfully.
8. Batch Operations
When you need to execute the same SQL statement many times with different parameters (e.g., inserting 1,000 rows), sending each statement individually is extremely slow due to network round-trips. Batch operations bundle multiple statements into a single round-trip.
Performance Comparison
| Approach | 10,000 Inserts | Network Round-Trips |
|---|---|---|
| Individual inserts | ~30 seconds | 10,000 |
| Batch inserts | ~0.5 seconds | 1 |
| Batch + transaction | ~0.3 seconds | 1 |
import java.sql.*;
public class BatchExample {
public static void batchInsertUsers(Connection conn, List users) throws SQLException {
String sql = "INSERT INTO users (username, email, age) VALUES (?, ?, ?)";
conn.setAutoCommit(false); // Wrap batch in a transaction for performance
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
int batchSize = 500; // Flush every 500 rows to avoid memory issues
int count = 0;
for (String[] user : users) {
pstmt.setString(1, user[0]); // username
pstmt.setString(2, user[1]); // email
pstmt.setInt(3, Integer.parseInt(user[2])); // age
pstmt.addBatch(); // Add to batch
count++;
if (count % batchSize == 0) {
pstmt.executeBatch(); // Send batch to database
pstmt.clearBatch(); // Clear for next batch
System.out.println("Flushed " + count + " rows...");
}
}
// Execute remaining records
pstmt.executeBatch();
conn.commit();
System.out.println("Batch insert complete: " + count + " total rows.");
} catch (SQLException e) {
conn.rollback();
System.err.println("Batch failed, rolled back: " + e.getMessage());
throw e;
} finally {
conn.setAutoCommit(true);
}
}
public static void main(String[] args) throws SQLException {
try (Connection conn = DriverManager.getConnection("jdbc:h2:mem:testdb", "sa", "")) {
// Create table...
List users = List.of(
new String[]{"user1", "user1@mail.com", "25"},
new String[]{"user2", "user2@mail.com", "30"},
new String[]{"user3", "user3@mail.com", "35"},
new String[]{"user4", "user4@mail.com", "28"},
new String[]{"user5", "user5@mail.com", "42"}
);
batchInsertUsers(conn, users);
}
}
}
// Output:
// Batch insert complete: 5 total rows.
Batch with Statement (Multiple Different SQL)
You can also batch different SQL statements together using Statement:
try (Statement stmt = conn.createStatement()) {
conn.setAutoCommit(false);
stmt.addBatch("INSERT INTO audit_log (action) VALUES ('User created')");
stmt.addBatch("UPDATE users SET active = true WHERE id = 1");
stmt.addBatch("DELETE FROM temp_tokens WHERE expired = true");
int[] results = stmt.executeBatch();
// results[0] = rows affected by first statement
// results[1] = rows affected by second statement
// results[2] = rows affected by third statement
for (int i = 0; i < results.length; i++) {
System.out.println("Statement " + (i + 1) + ": " + results[i] + " row(s) affected");
}
conn.commit();
}
// Output:
// Statement 1: 1 row(s) affected
// Statement 2: 1 row(s) affected
// Statement 3: 3 row(s) affected
9. Connection Pooling
Creating a database connection is expensive. It involves TCP handshake, authentication, SSL negotiation, and resource allocation. Opening a new connection for every database call and closing it afterward is extremely wasteful in a real application.
Connection pooling solves this by maintaining a pool of pre-created, reusable connections. When your code needs a connection, it borrows one from the pool. When done, it returns it to the pool instead of closing it.
Without Pooling vs With Pooling
Without Pooling: Request 1: Open connection -> Execute query -> Close connection (200ms overhead) Request 2: Open connection -> Execute query -> Close connection (200ms overhead) Request 3: Open connection -> Execute query -> Close connection (200ms overhead) With Pooling: Startup: Create 10 connections in pool Request 1: Borrow connection -> Execute query -> Return to pool (0ms overhead) Request 2: Borrow connection -> Execute query -> Return to pool (0ms overhead) Request 3: Borrow connection -> Execute query -> Return to pool (0ms overhead)
HikariCP -- The Industry Standard
HikariCP is the fastest and most widely used connection pool for Java. Spring Boot uses it as the default. Add it as a dependency:
com.zaxxer HikariCP 5.1.0
Setting up HikariCP:
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class ConnectionPoolExample {
private static HikariDataSource dataSource;
// Initialize the pool once at application startup
public static void initPool() {
HikariConfig config = new HikariConfig();
// Required settings
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");
config.setUsername("root");
config.setPassword("secret");
// Pool sizing
config.setMaximumPoolSize(10); // Max connections in pool
config.setMinimumIdle(5); // Min idle connections maintained
config.setIdleTimeout(300000); // 5 min -- close idle connections after this
config.setMaxLifetime(1800000); // 30 min -- max lifetime of a connection
// Connection validation
config.setConnectionTimeout(30000); // 30 sec -- wait for connection from pool
config.setConnectionTestQuery("SELECT 1"); // Validate connection health
// Performance settings
config.addDataSourceProperty("cachePrepStmts", "true");
config.addDataSourceProperty("prepStmtCacheSize", "250");
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
dataSource = new HikariDataSource(config);
System.out.println("Connection pool initialized.");
}
// Get a connection from the pool
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
// Shutdown the pool at application exit
public static void closePool() {
if (dataSource != null && !dataSource.isClosed()) {
dataSource.close();
System.out.println("Connection pool closed.");
}
}
public static void main(String[] args) {
initPool();
// Use connections from the pool
try (Connection conn = getConnection()) {
// Connection is borrowed from the pool
System.out.println("Got connection from pool: " + conn.isValid(2));
// ... do work ...
} catch (SQLException e) {
e.printStackTrace();
}
// Connection is returned to the pool here, NOT closed
closePool();
}
}
// Output:
// Connection pool initialized.
// Got connection from pool: true
// Connection pool closed.
DataSource vs DriverManager
| Feature | DriverManager | DataSource (with pool) |
|---|---|---|
| Connection creation | New connection every time | Reuses pooled connections |
| Performance | Slow (TCP+auth per call) | Fast (borrow/return) |
| Resource management | Manual | Automatic (pool manages lifecycle) |
| Configuration | URL + user + password | Pool size, timeouts, validation, metrics |
| Use case | Learning, small scripts | Production applications |
Rule: Use DriverManager for learning and scripts. Use DataSource with HikariCP for any real application.
10. Stored Procedures
A stored procedure is a precompiled SQL program stored in the database. JDBC calls stored procedures using CallableStatement, which extends PreparedStatement.
First, here is a simple stored procedure in MySQL:
-- MySQL stored procedure: Get user by ID
DELIMITER //
CREATE PROCEDURE get_user_by_id(IN user_id INT)
BEGIN
SELECT id, username, email, salary FROM users WHERE id = user_id;
END //
DELIMITER ;
-- MySQL stored procedure with OUT parameter
DELIMITER //
CREATE PROCEDURE count_active_users(OUT user_count INT)
BEGIN
SELECT COUNT(*) INTO user_count FROM users WHERE active = true;
END //
DELIMITER ;
-- MySQL stored procedure with IN and OUT
DELIMITER //
CREATE PROCEDURE calculate_bonus(
IN employee_id INT,
IN bonus_percentage DECIMAL(5,2),
OUT bonus_amount DECIMAL(10,2)
)
BEGIN
SELECT salary * (bonus_percentage / 100) INTO bonus_amount
FROM users WHERE id = employee_id;
END //
DELIMITER ;
Calling these procedures from Java:
import java.sql.*;
public class StoredProcedureExample {
// Call procedure with IN parameter that returns a ResultSet
public static void getUserById(Connection conn, int userId) throws SQLException {
String sql = "{CALL get_user_by_id(?)}";
try (CallableStatement cstmt = conn.prepareCall(sql)) {
cstmt.setInt(1, userId);
try (ResultSet rs = cstmt.executeQuery()) {
if (rs.next()) {
System.out.printf("User: %s (%s) - $%.2f%n",
rs.getString("username"),
rs.getString("email"),
rs.getDouble("salary"));
}
}
}
}
// Call procedure with OUT parameter
public static int countActiveUsers(Connection conn) throws SQLException {
String sql = "{CALL count_active_users(?)}";
try (CallableStatement cstmt = conn.prepareCall(sql)) {
cstmt.registerOutParameter(1, Types.INTEGER); // Register OUT param
cstmt.execute();
int count = cstmt.getInt(1); // Get the OUT value
System.out.println("Active users: " + count);
return count;
}
}
// Call procedure with IN and OUT parameters
public static double calculateBonus(Connection conn, int employeeId,
double percentage) throws SQLException {
String sql = "{CALL calculate_bonus(?, ?, ?)}";
try (CallableStatement cstmt = conn.prepareCall(sql)) {
cstmt.setInt(1, employeeId); // IN
cstmt.setDouble(2, percentage); // IN
cstmt.registerOutParameter(3, Types.DECIMAL); // OUT
cstmt.execute();
double bonus = cstmt.getDouble(3);
System.out.printf("Bonus for employee %d at %.1f%%: $%.2f%n",
employeeId, percentage, bonus);
return bonus;
}
}
}
// Output:
// User: john_doe (john@example.com) - $75000.00
// Active users: 3
// Bonus for employee 1 at 10.0%: $7500.00
11. Common Mistakes
These are the mistakes that cause the most bugs, security vulnerabilities, and performance issues in JDBC code. Avoid every one of them.
Mistake 1: SQL Injection via String Concatenation
The single most dangerous mistake. Never concatenate user input into SQL strings:
// WRONG -- SQL injection vulnerability String sql = "SELECT * FROM users WHERE username = '" + userInput + "'"; Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(sql); // RIGHT -- parameterized query String sql = "SELECT * FROM users WHERE username = ?"; PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setString(1, userInput); ResultSet rs = pstmt.executeQuery();
Mistake 2: Not Closing Resources
Every Connection, Statement, and ResultSet holds database and JVM resources. Forgetting to close them causes connection leaks, which eventually crash your application:
// WRONG -- resources never closed if exception occurs
Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
// if exception here, conn, pstmt, and rs are leaked
rs.close();
pstmt.close();
conn.close();
// RIGHT -- try-with-resources guarantees cleanup
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
// Work with rs...
} // All three auto-closed, even on exception
Mistake 3: Ignoring Transactions
With auto-commit on (the default), each statement is its own transaction. If a multi-step operation fails halfway, you end up with inconsistent data:
// WRONG -- auto-commit means each statement is independent
pstmt1.executeUpdate(); // Debits account A -- committed immediately
pstmt2.executeUpdate(); // Credits account B -- FAILS!
// Account A was debited but account B was never credited. Money vanished.
// RIGHT -- wrap related operations in a transaction
conn.setAutoCommit(false);
try {
pstmt1.executeUpdate(); // Debits account A -- NOT committed yet
pstmt2.executeUpdate(); // Credits account B -- NOT committed yet
conn.commit(); // Both committed together
} catch (SQLException e) {
conn.rollback(); // Both rolled back together
}
Mistake 4: The N+1 Query Problem
Executing a query inside a loop, generating N additional queries for N results:
// WRONG -- N+1 problem: 1 query to get orders + N queries to get users
ResultSet orders = stmt.executeQuery("SELECT * FROM orders"); // 1 query
while (orders.next()) {
int userId = orders.getInt("user_id");
// This runs once per order -- if 1000 orders, that's 1000 extra queries!
PreparedStatement userStmt = conn.prepareStatement("SELECT * FROM users WHERE id = ?");
userStmt.setInt(1, userId);
ResultSet user = userStmt.executeQuery();
// ...
}
// RIGHT -- use a JOIN to get all data in one query
String sql = """
SELECT o.id AS order_id, o.total, u.username, u.email
FROM orders o
JOIN users u ON o.user_id = u.id
""";
ResultSet rs = stmt.executeQuery(sql); // 1 query for everything
Mistake 5: Hardcoding Database Credentials
// WRONG -- credentials in source code (committed to git!)
Connection conn = DriverManager.getConnection(
"jdbc:mysql://prod-server:3306/mydb", "admin", "P@ssw0rd!");
// RIGHT -- use environment variables or config files
String url = System.getenv("DB_URL");
String user = System.getenv("DB_USER");
String password = System.getenv("DB_PASSWORD");
Connection conn = DriverManager.getConnection(url, user, password);
Mistake 6: Using getObject() Without Type Safety
// WRONG -- loses type safety, requires casting
Object value = rs.getObject("salary");
double salary = (Double) value; // ClassCastException if null or wrong type
// RIGHT -- use typed getters
double salary = rs.getDouble("salary");
if (rs.wasNull()) {
// Handle null case
}
// ALSO RIGHT -- use getObject with type parameter (Java 7+)
Double salary = rs.getObject("salary", Double.class); // Returns null if SQL NULL
12. Best Practices
These are the practices that separate production-quality JDBC code from tutorial-level code. Follow every one of them.
12.1 Always Use PreparedStatement
Even when the query has no parameters, PreparedStatement gives you precompilation benefits and establishes a consistent pattern. The only exception is DDL (CREATE TABLE, ALTER TABLE).
12.2 Always Use try-with-resources
Close resources in the reverse order of creation. With try-with-resources, this is automatic:
// Gold standard pattern for JDBC
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, value);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
// Process row
}
}
}
12.3 Use Connection Pooling in Production
Never use DriverManager.getConnection() in production. Always use a connection pool (HikariCP). If using Spring Boot, HikariCP is the default -- just configure it in application.properties.
12.4 Use Transactions for Multi-Statement Operations
Any operation that modifies multiple rows or tables should be wrapped in a transaction. Follow this pattern:
public void doMultiStepWork(Connection conn) throws SQLException {
conn.setAutoCommit(false);
try {
// Step 1...
// Step 2...
// Step 3...
conn.commit();
} catch (SQLException e) {
conn.rollback();
throw e; // Re-throw so the caller knows it failed
} finally {
conn.setAutoCommit(true);
}
}
12.5 Keep SQL Out of Business Logic
Use the DAO pattern (covered in the next section) to separate data access from business logic. Your service classes should not contain SQL strings.
12.6 Log SQL Errors Properly
try {
// database operation
} catch (SQLException e) {
// Log ALL the information -- you will need it for debugging
logger.error("Database error - Message: {} | SQLState: {} | ErrorCode: {} | SQL: {}",
e.getMessage(), e.getSQLState(), e.getErrorCode(), sql, e);
throw e; // Re-throw or wrap in a custom exception
}
12.7 Use Meaningful Column Aliases
// WRONG -- what does rs.getString(1) mean? Fragile if column order changes.
ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM table1");
String x = rs.getString(1);
// RIGHT -- use aliases and access by name
String sql = """
SELECT u.username AS user_name,
o.total AS order_total,
o.created AS order_date
FROM users u
JOIN orders o ON u.id = o.user_id
""";
ResultSet rs = stmt.executeQuery(sql);
String name = rs.getString("user_name");
double total = rs.getDouble("order_total");
Best Practices Summary
| Practice | Do | Don't |
|---|---|---|
| SQL parameters | Use PreparedStatement with ? |
Concatenate strings into SQL |
| Resource cleanup | Use try-with-resources | Manual close in finally block |
| Connections | Use connection pool (HikariCP) | Create new connections per query |
| Transactions | Explicit setAutoCommit(false) for multi-step ops |
Rely on auto-commit for related changes |
| Architecture | DAO pattern, SQL in data layer only | SQL strings scattered in business logic |
| Column access | Access by column name | Access by column index |
| Credentials | Environment variables or config files | Hardcode in source code |
| Error handling | Log SQL state, error code, and message | Catch and swallow exceptions |
| Queries | Use JOINs for related data | Query in a loop (N+1) |
| Null handling | Check wasNull() or use getObject() |
Assume primitives from DB are never null |
13. DAO Pattern
The Data Access Object (DAO) pattern separates the data access logic from the business logic. Your service layer should not know or care whether data comes from MySQL, PostgreSQL, a REST API, or a flat file. It just calls methods on a DAO interface.
Why Use the DAO Pattern?
- Separation of concerns -- SQL stays in one place, business logic in another
- Testability -- you can mock the DAO interface in unit tests
- Swappability -- switch databases or use in-memory implementations without changing business logic
- Single responsibility -- each DAO handles one entity (UserDAO, OrderDAO, ProductDAO)
Structure
+------------------+ +------------------+
| UserService | -------> | UserDAO | <-- Interface
| (business logic) | | (data contract) |
+------------------+ +------------------+
^
| implements
+------------------+
| UserDAOImpl | <-- JDBC implementation
| (SQL + JDBC) |
+------------------+
Step 1: Define the Model
import java.time.LocalDateTime;
public class User {
private int id;
private String username;
private String email;
private int age;
private double salary;
private boolean active;
private LocalDateTime createdAt;
// No-arg constructor (needed for DAO mapping)
public User() {}
// Constructor for creating new users (no ID yet)
public User(String username, String email, int age, double salary) {
this.username = username;
this.email = email;
this.age = age;
this.salary = salary;
this.active = true;
}
// Getters and setters
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getUsername() { return username; }
public void setUsername(String username) { this.username = username; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
public int getAge() { return age; }
public void setAge(int age) { this.age = age; }
public double getSalary() { return salary; }
public void setSalary(double salary) { this.salary = salary; }
public boolean isActive() { return active; }
public void setActive(boolean active) { this.active = active; }
public LocalDateTime getCreatedAt() { return createdAt; }
public void setCreatedAt(LocalDateTime createdAt) { this.createdAt = createdAt; }
@Override
public String toString() {
return String.format("User{id=%d, username='%s', email='%s', age=%d, salary=%.2f, active=%b}",
id, username, email, age, salary, active);
}
}
Step 2: Define the DAO Interface
import java.util.List;
import java.util.Optional;
public interface UserDAO {
// Create
User save(User user);
// Read
Optional findById(int id);
Optional findByUsername(String username);
List findAll();
List findByMinSalary(double minSalary);
// Update
boolean update(User user);
// Delete
boolean deleteById(int id);
// Count
long count();
}
Step 3: Implement the DAO with JDBC
import javax.sql.DataSource;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
public class UserDAOImpl implements UserDAO {
private final DataSource dataSource;
public UserDAOImpl(DataSource dataSource) {
this.dataSource = dataSource; // Injected -- no hardcoded connection info
}
@Override
public User save(User user) {
String sql = "INSERT INTO users (username, email, age, salary, active) VALUES (?, ?, ?, ?, ?)";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
pstmt.setString(1, user.getUsername());
pstmt.setString(2, user.getEmail());
pstmt.setInt(3, user.getAge());
pstmt.setDouble(4, user.getSalary());
pstmt.setBoolean(5, user.isActive());
pstmt.executeUpdate();
try (ResultSet keys = pstmt.getGeneratedKeys()) {
if (keys.next()) {
user.setId(keys.getInt(1));
}
}
return user;
} catch (SQLException e) {
throw new RuntimeException("Failed to save user: " + user.getUsername(), e);
}
}
@Override
public Optional findById(int id) {
String sql = "SELECT * FROM users WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return Optional.of(mapRow(rs));
}
}
return Optional.empty();
} catch (SQLException e) {
throw new RuntimeException("Failed to find user by ID: " + id, e);
}
}
@Override
public Optional findByUsername(String username) {
String sql = "SELECT * FROM users WHERE username = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, username);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return Optional.of(mapRow(rs));
}
}
return Optional.empty();
} catch (SQLException e) {
throw new RuntimeException("Failed to find user by username: " + username, e);
}
}
@Override
public List findAll() {
String sql = "SELECT * FROM users ORDER BY id";
List users = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
users.add(mapRow(rs));
}
return users;
} catch (SQLException e) {
throw new RuntimeException("Failed to find all users", e);
}
}
@Override
public List findByMinSalary(double minSalary) {
String sql = "SELECT * FROM users WHERE salary >= ? ORDER BY salary DESC";
List users = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, minSalary);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
users.add(mapRow(rs));
}
}
return users;
} catch (SQLException e) {
throw new RuntimeException("Failed to find users by salary", e);
}
}
@Override
public boolean update(User user) {
String sql = "UPDATE users SET username = ?, email = ?, age = ?, salary = ?, active = ? WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, user.getUsername());
pstmt.setString(2, user.getEmail());
pstmt.setInt(3, user.getAge());
pstmt.setDouble(4, user.getSalary());
pstmt.setBoolean(5, user.isActive());
pstmt.setInt(6, user.getId());
return pstmt.executeUpdate() > 0;
} catch (SQLException e) {
throw new RuntimeException("Failed to update user: " + user.getId(), e);
}
}
@Override
public boolean deleteById(int id) {
String sql = "DELETE FROM users WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
return pstmt.executeUpdate() > 0;
} catch (SQLException e) {
throw new RuntimeException("Failed to delete user: " + id, e);
}
}
@Override
public long count() {
String sql = "SELECT COUNT(*) FROM users";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
rs.next();
return rs.getLong(1);
} catch (SQLException e) {
throw new RuntimeException("Failed to count users", e);
}
}
// Private helper -- maps a ResultSet row to a User object
private User mapRow(ResultSet rs) throws SQLException {
User user = new User();
user.setId(rs.getInt("id"));
user.setUsername(rs.getString("username"));
user.setEmail(rs.getString("email"));
user.setAge(rs.getInt("age"));
user.setSalary(rs.getDouble("salary"));
user.setActive(rs.getBoolean("active"));
Timestamp ts = rs.getTimestamp("created_at");
if (ts != null) {
user.setCreatedAt(ts.toLocalDateTime());
}
return user;
}
}
Step 4: Use the DAO in Business Logic
public class UserService {
private final UserDAO userDAO;
public UserService(UserDAO userDAO) {
this.userDAO = userDAO; // Dependency injection
}
public User registerUser(String username, String email, int age, double salary) {
// Business logic validation -- no SQL here
if (username == null || username.isBlank()) {
throw new IllegalArgumentException("Username cannot be empty");
}
if (userDAO.findByUsername(username).isPresent()) {
throw new IllegalArgumentException("Username already taken: " + username);
}
User user = new User(username, email, age, salary);
return userDAO.save(user);
}
public User getUserOrThrow(int id) {
return userDAO.findById(id)
.orElseThrow(() -> new RuntimeException("User not found: " + id));
}
public List getHighEarners(double threshold) {
return userDAO.findByMinSalary(threshold);
}
}
// Usage:
// UserDAO dao = new UserDAOImpl(dataSource);
// UserService service = new UserService(dao);
// User user = service.registerUser("john_doe", "john@example.com", 28, 75000);
14. Complete Practical Example
Let us put everything together in a complete, runnable application. This example demonstrates a CRUD application for managing employees with proper resource management, transactions, batch operations, the DAO pattern, and all the best practices covered in this tutorial.
We will use the H2 in-memory database so you can run this without installing anything.
Project Structure
src/ Employee.java -- Model class EmployeeDAO.java -- DAO interface EmployeeDAOImpl.java -- JDBC implementation with all best practices EmployeeApp.java -- Main application demonstrating all operations
Employee Model
import java.math.BigDecimal;
import java.time.LocalDate;
import java.time.LocalDateTime;
public class Employee {
private int id;
private String firstName;
private String lastName;
private String email;
private String department;
private BigDecimal salary;
private LocalDate hireDate;
private boolean active;
private LocalDateTime createdAt;
public Employee() {}
public Employee(String firstName, String lastName, String email,
String department, BigDecimal salary, LocalDate hireDate) {
this.firstName = firstName;
this.lastName = lastName;
this.email = email;
this.department = department;
this.salary = salary;
this.hireDate = hireDate;
this.active = true;
}
// Getters and setters
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getFirstName() { return firstName; }
public void setFirstName(String firstName) { this.firstName = firstName; }
public String getLastName() { return lastName; }
public void setLastName(String lastName) { this.lastName = lastName; }
public String getEmail() { return email; }
public void setEmail(String email) { this.email = email; }
public String getDepartment() { return department; }
public void setDepartment(String department) { this.department = department; }
public BigDecimal getSalary() { return salary; }
public void setSalary(BigDecimal salary) { this.salary = salary; }
public LocalDate getHireDate() { return hireDate; }
public void setHireDate(LocalDate hireDate) { this.hireDate = hireDate; }
public boolean isActive() { return active; }
public void setActive(boolean active) { this.active = active; }
public LocalDateTime getCreatedAt() { return createdAt; }
public void setCreatedAt(LocalDateTime createdAt) { this.createdAt = createdAt; }
public String getFullName() {
return firstName + " " + lastName;
}
@Override
public String toString() {
return String.format("Employee{id=%d, name='%s %s', dept='%s', salary=%s, active=%b}",
id, firstName, lastName, department, salary, active);
}
}
EmployeeDAO Interface
import java.math.BigDecimal;
import java.util.List;
import java.util.Optional;
public interface EmployeeDAO {
// Schema management
void createTable();
// CRUD
Employee save(Employee employee);
Optional findById(int id);
List findAll();
List findByDepartment(String department);
boolean update(Employee employee);
boolean deleteById(int id);
// Batch
int[] saveBatch(List employees);
// Transaction example
boolean transferDepartment(int employeeId, String newDepartment, BigDecimal salaryAdjustment);
// Aggregation
long count();
BigDecimal getAverageSalaryByDepartment(String department);
}
EmployeeDAOImpl -- Full JDBC Implementation
import javax.sql.DataSource;
import java.math.BigDecimal;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
public class EmployeeDAOImpl implements EmployeeDAO {
private final DataSource dataSource;
public EmployeeDAOImpl(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void createTable() {
String sql = """
CREATE TABLE IF NOT EXISTS employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL UNIQUE,
department VARCHAR(50) NOT NULL,
salary DECIMAL(10,2) NOT NULL,
hire_date DATE NOT NULL,
active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""";
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
stmt.executeUpdate(sql);
} catch (SQLException e) {
throw new RuntimeException("Failed to create employees table", e);
}
}
@Override
public Employee save(Employee emp) {
String sql = """
INSERT INTO employees (first_name, last_name, email, department, salary, hire_date, active)
VALUES (?, ?, ?, ?, ?, ?, ?)
""";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)) {
setEmployeeParams(pstmt, emp);
pstmt.executeUpdate();
try (ResultSet keys = pstmt.getGeneratedKeys()) {
if (keys.next()) {
emp.setId(keys.getInt(1));
}
}
return emp;
} catch (SQLException e) {
throw new RuntimeException("Failed to save employee: " + emp.getEmail(), e);
}
}
@Override
public Optional findById(int id) {
String sql = "SELECT * FROM employees WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
return rs.next() ? Optional.of(mapRow(rs)) : Optional.empty();
}
} catch (SQLException e) {
throw new RuntimeException("Failed to find employee: " + id, e);
}
}
@Override
public List findAll() {
String sql = "SELECT * FROM employees ORDER BY last_name, first_name";
return executeQuery(sql);
}
@Override
public List findByDepartment(String department) {
String sql = "SELECT * FROM employees WHERE department = ? AND active = true ORDER BY last_name";
List employees = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, department);
try (ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
employees.add(mapRow(rs));
}
}
return employees;
} catch (SQLException e) {
throw new RuntimeException("Failed to find employees in department: " + department, e);
}
}
@Override
public boolean update(Employee emp) {
String sql = """
UPDATE employees
SET first_name = ?, last_name = ?, email = ?, department = ?,
salary = ?, hire_date = ?, active = ?
WHERE id = ?
""";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
setEmployeeParams(pstmt, emp);
pstmt.setInt(8, emp.getId());
return pstmt.executeUpdate() > 0;
} catch (SQLException e) {
throw new RuntimeException("Failed to update employee: " + emp.getId(), e);
}
}
@Override
public boolean deleteById(int id) {
String sql = "DELETE FROM employees WHERE id = ?";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
return pstmt.executeUpdate() > 0;
} catch (SQLException e) {
throw new RuntimeException("Failed to delete employee: " + id, e);
}
}
@Override
public int[] saveBatch(List employees) {
String sql = """
INSERT INTO employees (first_name, last_name, email, department, salary, hire_date, active)
VALUES (?, ?, ?, ?, ?, ?, ?)
""";
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(false);
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
for (Employee emp : employees) {
setEmployeeParams(pstmt, emp);
pstmt.addBatch();
}
int[] results = pstmt.executeBatch();
conn.commit();
return results;
} catch (SQLException e) {
conn.rollback();
throw e;
} finally {
conn.setAutoCommit(true);
}
} catch (SQLException e) {
throw new RuntimeException("Batch insert failed", e);
}
}
@Override
public boolean transferDepartment(int employeeId, String newDepartment,
BigDecimal salaryAdjustment) {
String updateEmpSql = "UPDATE employees SET department = ?, salary = salary + ? WHERE id = ?";
String auditSql = """
INSERT INTO department_transfers (employee_id, new_department, salary_change, transfer_date)
VALUES (?, ?, ?, CURRENT_DATE)
""";
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(false);
try {
// Step 1: Update employee's department and salary
try (PreparedStatement pstmt = conn.prepareStatement(updateEmpSql)) {
pstmt.setString(1, newDepartment);
pstmt.setBigDecimal(2, salaryAdjustment);
pstmt.setInt(3, employeeId);
int rows = pstmt.executeUpdate();
if (rows == 0) {
throw new SQLException("Employee not found: " + employeeId);
}
}
// Step 2: Record the transfer in audit table
// (Create audit table if it does not exist)
try (Statement stmt = conn.createStatement()) {
stmt.executeUpdate("""
CREATE TABLE IF NOT EXISTS department_transfers (
id INT AUTO_INCREMENT PRIMARY KEY,
employee_id INT NOT NULL,
new_department VARCHAR(50) NOT NULL,
salary_change DECIMAL(10,2),
transfer_date DATE NOT NULL
)
""");
}
try (PreparedStatement pstmt = conn.prepareStatement(auditSql)) {
pstmt.setInt(1, employeeId);
pstmt.setString(2, newDepartment);
pstmt.setBigDecimal(3, salaryAdjustment);
pstmt.executeUpdate();
}
conn.commit();
return true;
} catch (SQLException e) {
conn.rollback();
throw e;
} finally {
conn.setAutoCommit(true);
}
} catch (SQLException e) {
throw new RuntimeException("Department transfer failed for employee: " + employeeId, e);
}
}
@Override
public long count() {
String sql = "SELECT COUNT(*) FROM employees";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
rs.next();
return rs.getLong(1);
} catch (SQLException e) {
throw new RuntimeException("Failed to count employees", e);
}
}
@Override
public BigDecimal getAverageSalaryByDepartment(String department) {
String sql = "SELECT AVG(salary) FROM employees WHERE department = ? AND active = true";
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, department);
try (ResultSet rs = pstmt.executeQuery()) {
rs.next();
BigDecimal avg = rs.getBigDecimal(1);
return avg != null ? avg : BigDecimal.ZERO;
}
} catch (SQLException e) {
throw new RuntimeException("Failed to get average salary for: " + department, e);
}
}
// ---------- Private Helpers ----------
private void setEmployeeParams(PreparedStatement pstmt, Employee emp) throws SQLException {
pstmt.setString(1, emp.getFirstName());
pstmt.setString(2, emp.getLastName());
pstmt.setString(3, emp.getEmail());
pstmt.setString(4, emp.getDepartment());
pstmt.setBigDecimal(5, emp.getSalary());
pstmt.setDate(6, Date.valueOf(emp.getHireDate()));
pstmt.setBoolean(7, emp.isActive());
}
private Employee mapRow(ResultSet rs) throws SQLException {
Employee emp = new Employee();
emp.setId(rs.getInt("id"));
emp.setFirstName(rs.getString("first_name"));
emp.setLastName(rs.getString("last_name"));
emp.setEmail(rs.getString("email"));
emp.setDepartment(rs.getString("department"));
emp.setSalary(rs.getBigDecimal("salary"));
emp.setHireDate(rs.getDate("hire_date").toLocalDate());
emp.setActive(rs.getBoolean("active"));
Timestamp ts = rs.getTimestamp("created_at");
if (ts != null) {
emp.setCreatedAt(ts.toLocalDateTime());
}
return emp;
}
private List executeQuery(String sql) {
List employees = new ArrayList<>();
try (Connection conn = dataSource.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
while (rs.next()) {
employees.add(mapRow(rs));
}
return employees;
} catch (SQLException e) {
throw new RuntimeException("Query failed: " + sql, e);
}
}
}
EmployeeApp -- Main Application
import org.h2.jdbcx.JdbcDataSource;
import java.math.BigDecimal;
import java.time.LocalDate;
import java.util.List;
public class EmployeeApp {
public static void main(String[] args) {
// 1. Set up DataSource (H2 in-memory database)
JdbcDataSource dataSource = new JdbcDataSource();
dataSource.setURL("jdbc:h2:mem:company;DB_CLOSE_DELAY=-1");
dataSource.setUser("sa");
dataSource.setPassword("");
// 2. Create DAO
EmployeeDAO dao = new EmployeeDAOImpl(dataSource);
// 3. Create the table
dao.createTable();
System.out.println("=== Table created ===\n");
// 4. INSERT -- Save individual employees
Employee alice = dao.save(new Employee(
"Alice", "Johnson", "alice@company.com",
"Engineering", new BigDecimal("95000.00"), LocalDate.of(2020, 3, 15)));
Employee bob = dao.save(new Employee(
"Bob", "Smith", "bob@company.com",
"Engineering", new BigDecimal("88000.00"), LocalDate.of(2021, 7, 1)));
System.out.println("Saved: " + alice);
System.out.println("Saved: " + bob);
// 5. BATCH INSERT -- Save multiple employees at once
List batch = List.of(
new Employee("Carol", "Williams", "carol@company.com",
"Marketing", new BigDecimal("72000.00"), LocalDate.of(2022, 1, 10)),
new Employee("David", "Brown", "david@company.com",
"Marketing", new BigDecimal("68000.00"), LocalDate.of(2022, 6, 20)),
new Employee("Eve", "Davis", "eve@company.com",
"Engineering", new BigDecimal("105000.00"), LocalDate.of(2019, 11, 5))
);
int[] batchResults = dao.saveBatch(batch);
System.out.println("\nBatch inserted " + batchResults.length + " employees.");
// 6. SELECT -- Find all employees
System.out.println("\n=== All Employees ===");
List allEmployees = dao.findAll();
allEmployees.forEach(System.out::println);
// 7. SELECT -- Find by ID
System.out.println("\n=== Find by ID ===");
dao.findById(1).ifPresentOrElse(
e -> System.out.println("Found: " + e),
() -> System.out.println("Not found")
);
// 8. SELECT -- Find by department
System.out.println("\n=== Engineering Department ===");
dao.findByDepartment("Engineering").forEach(System.out::println);
// 9. UPDATE -- Give Alice a raise
System.out.println("\n=== Update: Alice gets a raise ===");
alice.setSalary(new BigDecimal("105000.00"));
alice.setEmail("alice.johnson@company.com");
boolean updated = dao.update(alice);
System.out.println("Updated: " + updated);
dao.findById(alice.getId()).ifPresent(System.out::println);
// 10. TRANSACTION -- Transfer Bob to Marketing with a salary adjustment
System.out.println("\n=== Transaction: Transfer Bob to Marketing ===");
boolean transferred = dao.transferDepartment(bob.getId(), "Marketing", new BigDecimal("5000.00"));
System.out.println("Transfer successful: " + transferred);
dao.findById(bob.getId()).ifPresent(System.out::println);
// 11. AGGREGATION -- Average salary by department
System.out.println("\n=== Average Salaries ===");
System.out.println("Engineering avg: $" + dao.getAverageSalaryByDepartment("Engineering"));
System.out.println("Marketing avg: $" + dao.getAverageSalaryByDepartment("Marketing"));
// 12. DELETE -- Remove David
System.out.println("\n=== Delete David ===");
boolean deleted = dao.deleteById(4);
System.out.println("Deleted: " + deleted);
// 13. Final state
System.out.println("\n=== Final State ===");
System.out.println("Total employees: " + dao.count());
dao.findAll().forEach(System.out::println);
}
}
Expected Output
=== Table created ===
Saved: Employee{id=1, name='Alice Johnson', dept='Engineering', salary=95000.00, active=true}
Saved: Employee{id=2, name='Bob Smith', dept='Engineering', salary=88000.00, active=true}
Batch inserted 3 employees.
=== All Employees ===
Employee{id=4, name='David Brown', dept='Marketing', salary=68000.00, active=true}
Employee{id=5, name='Eve Davis', dept='Engineering', salary=105000.00, active=true}
Employee{id=1, name='Alice Johnson', dept='Engineering', salary=95000.00, active=true}
Employee{id=2, name='Bob Smith', dept='Engineering', salary=88000.00, active=true}
Employee{id=3, name='Carol Williams', dept='Marketing', salary=72000.00, active=true}
=== Find by ID ===
Found: Employee{id=1, name='Alice Johnson', dept='Engineering', salary=95000.00, active=true}
=== Engineering Department ===
Employee{id=5, name='Eve Davis', dept='Engineering', salary=105000.00, active=true}
Employee{id=1, name='Alice Johnson', dept='Engineering', salary=95000.00, active=true}
Employee{id=2, name='Bob Smith', dept='Engineering', salary=88000.00, active=true}
=== Update: Alice gets a raise ===
Updated: true
Employee{id=1, name='Alice Johnson', dept='Engineering', salary=105000.00, active=true}
=== Transaction: Transfer Bob to Marketing ===
Transfer successful: true
Employee{id=2, name='Bob Smith', dept='Marketing', salary=93000.00, active=true}
=== Average Salaries ===
Engineering avg: $105000.00
Marketing avg: $77666.67
=== Delete David ===
Deleted: true
=== Final State ===
Total employees: 4
Employee{id=5, name='Eve Davis', dept='Engineering', salary=105000.00, active=true}
Employee{id=1, name='Alice Johnson', dept='Engineering', salary=105000.00, active=true}
Employee{id=2, name='Bob Smith', dept='Marketing', salary=93000.00, active=true}
Employee{id=3, name='Carol Williams', dept='Marketing', salary=72000.00, active=true}
Concepts Demonstrated
| # | Concept | Where in Code |
|---|---|---|
| 1 | DataSource (not DriverManager) | JdbcDataSource setup in EmployeeApp |
| 2 | DAO pattern | EmployeeDAO interface + EmployeeDAOImpl |
| 3 | PreparedStatement everywhere | Every CRUD method uses ? placeholders |
| 4 | try-with-resources | Every method auto-closes Connection, PreparedStatement, ResultSet |
| 5 | Generated keys | save() retrieves auto-increment ID |
| 6 | Optional for nullable results | findById() returns Optional<Employee> |
| 7 | ResultSet mapping | Private mapRow() helper converts rows to objects |
| 8 | Batch operations | saveBatch() uses addBatch() + executeBatch() |
| 9 | Transactions | transferDepartment() wraps two tables in a transaction |
| 10 | Rollback on failure | saveBatch() and transferDepartment() both rollback on exception |
| 11 | BigDecimal for money | Salary uses BigDecimal, not double |
| 12 | java.time API | Uses LocalDate and LocalDateTime, not legacy java.util.Date |
| 13 | Dependency injection | DAO receives DataSource via constructor |
| 14 | Aggregation queries | count() and getAverageSalaryByDepartment() |
15. Quick Reference
| Topic | Key Point |
|---|---|
| JDBC | Java's standard API for database connectivity. Uses interfaces in java.sql with vendor-specific drivers. |
| Driver | Use Type 4 (pure Java). Auto-loaded since JDBC 4.0 -- no Class.forName() needed. |
| Connection | Use DataSource + HikariCP in production. Always close with try-with-resources. |
| Statement | For static SQL only (DDL). Never concatenate user input. |
| PreparedStatement | For all parameterized SQL. Prevents SQL injection. Precompiled for performance. |
| CallableStatement | For calling stored procedures. Register OUT parameters with registerOutParameter(). |
| ResultSet | Forward-only cursor by default. Use column names over indices. Check wasNull() for primitives. |
| Transactions | setAutoCommit(false), then commit() or rollback(). Always restore auto-commit in finally. |
| Batch | addBatch() + executeBatch(). Combine with transactions for maximum performance. |
| Connection Pool | HikariCP is the standard. Set max pool size, idle timeout, and enable statement caching. |
| DAO Pattern | Interface + implementation. Separates SQL from business logic. Enables testability. |
| Resource Cleanup | Always try-with-resources. Close in reverse order: ResultSet, Statement, Connection. |
| Security | Always PreparedStatement. Never concatenate. Credentials in env vars, not code. |