Any RuntimeException (unchecked exception) or Error will cause by default a rollback. Checked exceptions don’t cause a rollback
Spring Study Guide – Data Integration
A checked exception is an exception that is caught during compile time. Usually, if you use an IDE, the IDE will show you that you have a checked exception.
An unchecked exception is an exception that is caught at runtime. It is not caught during compile time. You have to account for this type of exception and provide a way to handle it at runtime.
- Checked exceptions: Java compiler requires to handle. E.g.,
Exception - Unchecked exceptions: compiler not require to declare. E.g.,
RuntimeException.
2. Why does Spring prefer unchecked exceptions?
- Checked exceptions reqires handling, result in cluttered code and unnecessary coupling.
- Unchecked exceptions are non-recoverable exceptions, should not let developer to handle. E.g., when
SQLExceptionhappens, nothing you can do.
Spring prefers unchecked exception because this way it gives the developer possibility to choose to handle them or not – he is not enforced to handle them. To use Spring specific exceptions you must use Spring templates. JdbcTemplate takes care of transforming SQLExceptions to meaningful DataAccessExceptions, this is done using SQLExceptionTranslators.
3. What is the data access exception hierarchy?
Each data access technology has its own exception types, such as
- SQLException for direct JDBC access,
- HibernateException used by native Hibernate, or
- EntityException used by JPA
What Spring does is to handle technology‐specific exceptions and translate them into its own exception hierarchy. The hierarchy is to isolate developers from the particulars of JDBC data access APIs from different vendors.
Spring’s DataAccessException
- It is an abstract class,
- It is the root exception.
- Its sub-classes are unchecked exceptions.
Spring data access exception family has three main branches:
org.springframework.dao.NonTransientDataAccessException- non-transient exceptions,
- which means that retrying the operation will fail unless the originating cause is fixed.
- The most obvious example here is searching for an object that does not exist.
RecoverableDataAccessException- when a previously failed operation might succeed if some recovery steps are performed,
- usually closing the current connection and using a new one.
- E.g., a temporary network hiccup
springframework.dao.TransientDataAccessException.- transient exception,
- which means that retrying the operation might succeed without any intervention.
- These are concurrency or latency exceptions.
- For example, when the database becomes unavailable because of a bad network connection in the middle of the execution of a query, an exception of type
QueryTimeoutExceptionis thrown. The developer can treat this exception by retrying the query.
4. How do you configure a DataSource in Spring? Which bean is very useful for development/test databases?
DataSource is a generalized connection factory. It hides connection pooling and transaction management from application code. Spring obtains connections to a database through a DataSource.
With Spring you can configure different types of DataSources:
- JDBC-driver defined DataSources
- JNDI DataSources
- Connection-pooling DataSources
JDBC driver-based DataSources are the simples type. Spring has 3 types of them:
- DriverManagerDataSource
- SimpleDriverDataSource
- SingleConnectionDataSource
@Bean
public DataSource datasource(){
DriverManagerDataSource ds = new DriverManagerDataSource();
ds.setDriverClassName("org.h2.Driver"); //this is a in-memory DB
ds.setUrl("jdbc:h2:tcp://localhost/~/databaseName");
ds.setUsername("admin");
ds.setPassword("pass");
return ds;
}
A very important DataSource implementation for development/testing purposes is the embedded data source. H2 is an embedded data source that is mostly used by developers for testing.
5. What is the Template design pattern and what is the JDBC template?
The Template method design pattern is about the following: you have an abstract class that has one final non-abstract method that defines some algorithm and more abstract methods that are to be implemented in the child classes. And when you run the final method (that you get from the abstract class) you get the algorithm defined in the abstract class but the implementation is done in the child non-abstract class. Meanwhile, our JdbcAccessor class that is abstract and is the parent class for JdbcTemplate has no such a method that is final and defines some algorithm.
JdbcTemplate is a convenience class that hides a lot of JDBC boilerplate code and allows to:
- execute SQL queries
- execute update statement
- performs stored procedures calls
- iterates over ResultSets
- extracts returned parameter values
The Spring JdbcTemplate simplifies the use of JDBC by implementing common workflows for
- querying,
- updating,
- statement execution etc.
Benefits are:
- Simplification: reduces boilerplate code for operations
- Handle exceptions
- Translates Exception from different vendors, e.g.,
DataAccessException - Avoids common mistake: release connections
- Allows customization, it’s template design pattern
- Thread safe
Spring comes with three template classes to choose from:
- JdbcTemplate
- NamedParameterJdbcTemplate
- SimpleJdbcTemplate (deprecated)
JdbcTemplate:
-
JdbcTemplate works with queries that specify parameters using the
'?'placeholder. -
Use
queryForObjectwhen it is expected that execution of the query will return a single result. -
Use
RowMapper<T>when each row of the ResultSet maps to a domain object. -
Use
RowCallbackHandlerwhen no value should be returned. -
Use
ResultSetExtractor<T>when multiple rows in the ResultSet map to a single object. -
initialize JdbcTemplate
The general practice is to initialize JdbcTemplate within the setDataSource method so that once the data source is injected by Spring, JdbcTemplate will also be initialized and ready for use.
Once configured, JdbcTemplate is thread-safe. That means you can also choose to initialize a single instance of JdbcTemplate in Spring’s configuration and have it injected into all DAO beans.
@Configuration
public class DemoJdbcConfig {
@Bean
public DataSource dataSource() {
return new DataSource();
}
@Bean
public JdbcTemplate jdbcTemplate(){
JdbcTemplate jdbcTemplate = new JdbcTemplate();
jdbcTemplate.setDataSource(dataSource());
return jdbcTemplate;
}
}
NamedParameterJdbcTemplate:
The NamedParameterJdbcTemplate class adds support for programming JDBC statements by using named parameters, as opposed to programming JDBC statements using only classic placeholder ( '?' ) arguments.
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
SqlParameterSource namedParameters = new MapSqlParameterSource("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}
//Map-based style
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
Map<String, String> namedParameters = Collections.singletonMap("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}
// BeanPropertySqlParameterSource
public int countOfActors(Actor exampleActor) {
String sql = "select count(*) from T_ACTOR where first_name = :firstName and last_name = :lastName";
SqlParameterSource namedParameters = new BeanPropertySqlParameterSource(exampleActor);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}
6. What is a callback? What are the three JdbcTemplate callback interfaces that can be used with queries? What is each used for?
a callback is any executable code that is passed as an argument to other code, which is expected to call back(execute) the argument at a given time
public class Test {
public static void main(String[] args) throws Exception {
new Test().doWork(new Callback() { // implementing class
@Override
public void call() {
System.out.println("callback called");
}
});
}
public void doWork(Callback callback) {
System.out.println("doing work");
callback.call();
}
public interface Callback {
void call();
}
}
JdbcTemplate 3 central callback interfaces:
- RowCallbackHandler – An interface used by JdbcTemplate for processing rows of a ResultSet on a per-row basis
- CallableStatementCreator – One of the three central callback interfaces used by the JdbcTemplate class. This interface creates a CallableStatement given a connection, provided by the JdbcTemplate class.
- PreparedStatementCreator – One of the two central callback interfaces used by the JdbcTemplate class. This interface creates a PreparedStatement given a connection, provided by the JdbcTemplate class.
Others:
- ResultSetExtractor
- BatchPreparedStatementSetter – Batch update callback interface used by the JdbcTemplate class. This interface sets values on a PreparedStatement provided by the JdbcTemplate class
- ParameterizedPreparedStatementSetter – Parameterized callback interface used by the JdbcTemplate class for batch updates. This interface sets values on a PreparedStatement provided by the JdbcTemplate class.
- PreparedStatementCallback – Generic callback interface for code that operates on a PreparedStatement
- StatementCallback – Generic callback interface for code that operates on a JDBC Statement
- CallableStatementCallback – Generic callback interface for code that operates on a CallableStatement
- ResultSetExtractor – Callback interface used by JdbcTemplate’s query methods.
- PreparedStatementSetter – General callback interface used by the JdbcTemplate class. This interface sets values on a PreparedStatement provided by the JdbcTemplate class.
7. Can you execute a plain SQL statement with the JDBC template?
Yes, using execute() methods – one of them accepts StatementCallback objects and the other wraps the String you pass in a StatementCallback. StatementCallback in its turn has a doInStatement() method that accepts Statement objects. So you can pass either an anonymous class with overridden doInStatement() method or just a simple String that execute() method of Statement will be run on.
template.execute(new StatementCallback<ResultSet>() {
public ResultSet doInStatement(Statement statement) throws SQLException, DataAccessException {
ResultSet rs = statement.executeQuery("SELECT * FROM databaseTable");
RowCallbackHandler handler = new RowCallbackHandler() {
public void processRow(ResultSet resultSet) throws SQLException {
while (resultSet.next()) {
System.out.println(resultSet.getObject(1) + "," + resultSet.getObject(3));
}
}
};
handler.processRow(rs);
return rs;
}
});
Yes. With following methods:
- batchUpdate()
- execute()
- query()
- queryForList()
- queryForObject()
- queryForRowSet()
- update()
DML
DML stands for Data Manipulation Language, the commands SELECT, INSERT, UPDATE, and DELETE are database statements used to create, update, or delete data from existing tables.
DDL DDL stands for Data Definition Language, used to manipulate database objects: tables, views, cursors, etc. DDL database statements can be executed with JdbcTemplate using the execute method.
public int createTable(String name) {
jdbcTemplate.execute("create table " + name + " (id integer, name varchar2)" );
String sql = "select count(*) from " + name;
return jdbcTemplate.queryForObject(sql, Integer.class);
}
8. When does the JDBC template acquire (and release) a connection – for every method called or once per template? Why?
9. How does the JdbcTemplate support generic queries? How does it return objects and lists/maps of objects?
10. What is a transaction? What is the difference between a local and a global transaction?
The context of execution for a group of SQL operations is called a transaction. Run them all successfully, or reverted. Tansaction enforces ACID principle.
Transactions are described in terms of ACID properties, which are as follows:
- Atomicity: All changes to data are performed as if they are a single operation. That is, all the changes are persisted, or none of them are. For example, in an application that transfers funds from one account to another, the atomicity property ensures that, if a debit is made successfully from one account, the corresponding credit is made to the other account.
- Consistency: Data is in a consistent state when a transaction starts and when it ends. For example, in an application that transfers funds from one account to another, the consistency property ensures that the total value of funds in both the accounts is the same at the start and end of each transaction.
- Isolatation: The intermediate state of a transaction is invisible to other transactions. As a result, transactions that run concurrently appear to be serialized. For example, in an application that transfers funds from one account to another, the isolation property ensures that another transaction sees the transferred funds in one account or the other, but not in both, nor in neither.
- Durability: After a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure. For example, in an application that transfers funds from one account to another, the durability property ensures that the changes made to each account will not be reversed.
In short a local transaction is a simple transaction that is about one single database; whilst a global one is application server managed and spreads across many components/ technologies. For global transactions consider the case that a record must be persisted in a database ONLY if some message is sent to a queue and processed – if the later fail the transaction must be rolled back.
11. Is a transaction a cross-cutting concern? How is it implemented by Spring?
Yes as it can affect many components. The core concept in Spring transactions world is the transaction strategy that is defined by PlatformTransactionManager. This interface is a service provider interface. It has multiple implementations and the one you choose depends on your requirements. From PlatformTransactionManager through getTransaction() method – by passing the TransactionDefinition in, you get the TransactionStatus that may represent a new or an existing transaction.
TransactionStatus specifies:
- isolation
- propagation
- propagation
- read-only status
of the transaction to be looked up in the PlatformTransactionManager.
12. How are you going to define a transaction in Spring?
Two ways of implementing it:
- Declarative, use
@transaction - Programmatic
- Use
TransactionTemplate - Use
PlatformTransactionManager
- Use
Declarative transaction management
Declarative transaction management is non-invasive.
- Configure transaction management support
- Marked a Spring Configuration class using the
@Configuration - Using Java Configuration, define a
PlatformTransactionManagerbean using@bean - Enable transaction management by annotate the config file with
@EnableTransactionManagement -
@Configuration @EnableTransactionManagement public class TestDataConfig { @Bean public PlatformTransactionManager txManager(){ return new DataSourceTransactionManager(dataSource()); } }
- Marked a Spring Configuration class using the
- Declare transactional methods using
@Transactional@Service public class UserServiceImpl implements UserService { @Transactional(propagation = Propagation.REQUIRED, readOnly= true) @Override public User findById(Long id) { return userRepo.findById(id); } }Programmatic transaction management
It is possible to use both declarative and programmatic transaction models simultaneously.
Programmatic transaction management allows you to control transactions through your codeexplicitly starting, committing, and joining them as you see fit.
Spring Framework provides two ways of implemeting Programmatic Transaction:
- Using
TransactionTemplate, which is recommended by Spring; - Using
PlatformTransactionManagerdirectly, which is low level.
Using
TransactionTemplateIt uses a callback approach.
can write aTransactionCallbackimplementation, runexecute(..)public class SimpleService implements Service { // single TransactionTemplate shared amongst all methods in this instance private final TransactionTemplate transactionTemplate; // use constructor-injection to supply the PlatformTransactionManager public SimpleService(PlatformTransactionManager transactionManager) { this.transactionTemplate = new TransactionTemplate(transactionManager); } public Object someServiceMethod() { return transactionTemplate.execute(new TransactionCallback() { // the code in this method executes in a transactional context public Object doInTransaction(TransactionStatus status) { updateOperation1(); return resultOfUpdateOperation2(); } }); } } - Using
Declarative way deals with adding some AOP related to transactions to the methods annotated with @Transactional or that have some tx-advices defined by XML.
Programmatic way is about using either TransactionTemplate or directly PlatformTransactionManager.
13. What does @Transactional do? What is the PlatformTransactionManager?
General Rule: Add the @Transaction annotation to the method that start (and finish) the unit of work. That is the part of your program that should been handled in on transaction (meaning, that it should be done/saved completely or not at all).
Rather than using XML AOP for matching the methods that should be transactional you can add this (@Transactional) annotation. PlatformTransactionManager is an interface that defines the transaction strategy through different implementations that match requirements specific to the project they are used in.
@Transactional is metadata that specifies that an interface, class, or method must have transactional semantics.
@Transactional Settings
-
The transactionManager attribute value defines the transaction manager used to manage the transaction in the context of which the annotated method is executed
-
The readOnly attribute should be used for transactions that involve operations that do not modify the database (example: searching, counting records). Defalt FALSE.
-
The propagation attribute can be used to define behavior of the target methods: if they should be executed in an existing or new transaction, or no transaction at all. There are seven propagation types. Default: PROPAGATION_REQUIRED.
-
The isolation attribute value defines how data modified in a transaction affects other simultaneous transactions. As a general idea, transactions should be isolated. A transaction should not be able to access changes from another uncommitted transaction. There are four levels of isolation, but every database management system supports them differently. In Spring, there are five isolation values. DEFAULT: the default isolation level of the DBMS.
-
timeout. By default, the value of this attribute is defined by the transaction manager provider, but it can be changed by setting a different value in the annotation:
@Transactional(timeout=3600)by milliseconds. -
rollbackFor. When this type of exception is thrown during the execution of a transactional method, the transaction is rolled back. By default, i’s rolled back only when a RuntimeException or Errors is thrown. In using this attribute, the rollback can be triggered for checked exceptions as well.
-
noRollbackFor attribute values should be one or more exception classes, subclasses of Throwable. When this type of exception is thrown during the execution of a transactional method, the transaction is not rolled back. By default, a transaction is rolled back only when a RuntimeException is thrown. Using this attribute, rollback of a transaction can be avoided for a RuntimeException as well.
Default settings for @Transactional:
- Propagation setting is
PROPAGATION_REQUIRED. - Isolation level is
ISOLATION_DEFAULT. - Transaction is
read/write, which isread only = FALSE. - Transaction timeout defaults to the default timeout of the underlying transaction system, or to none if timeouts are not supported.
- Any RuntimeException triggers rollback, and any checked Exception does not.
Annotation driven transaction settings:
mode- The default mode (proxy) processes annotated beans to be proxied by using Spring’s AOP framework.
- The alternative mode (aspectj) instead weaves the affected classes with Spring’s AspectJ transaction aspect, modifying the target class byte code to apply to any kind of method call. AspectJ weaving requires
spring-aspects.jarin the classpath as well as having load-time weaving (or compiletime weaving) enabled.
proxyTargetClas- Applies to proxy mode only.
- If it’s false or omitted, then standard JDK interface-based proxies are created.
- If the proxy-target-class attribute is set to true, class-based proxies are created.
order- Defines the order of the transaction advice that is applied to beans annotated with
@Transactional - Default
Ordered.LOWEST_PRECEDE NCE.
- Defines the order of the transaction advice that is applied to beans annotated with
14. Is the JDBC template able to participate in an existing transaction?
If you define a method as @Transactional and internally add some JdbcTemplate code it will run in that transaction; but JdbcTemplate itself cannot manage transactions – that is job of TransactionTemplate.
15. What is a transaction isolation level? How many do we have and how are they ordered?
Transaction isolation level is the level of one isolation of one transaction from another. Transaction level is defined from the perspective of 3 characteristics:
- Dirty reads – one transaction can read uncommitted data from other transaction
- Non-repeatable read – occurs when a second transaction reads the same row from the first transaction at different times getting different data each time because of the first transaction committing some changes or deleting the row.
- Phantom reads – occurs when the same search criteria is returning different data because of some other transaction interfering and deleting/adding data.
In Spring we have the following isolation levels:
- int ISOLATION_DEFAULT = -1 – Use the default isolation level of the underlying datastore.
- int ISOLATION_READ_UNCOMMITTED = 1 – Indicates that dirty reads, non-repeatable reads, and phantom reads can occur.
- int ISOLATION_READ_COMMITTED = 2 – Indicates that dirty reads are prevented; non-repeatable reads and phantom reads can occur.
- int ISOLATION_REPEATABLE_READ = 4 – Indicates that dirty reads and non-repeatable reads are prevented; phantom reads can occur.
- int ISOLATION_SERIALIZABLE = 8 – Indicates that dirty reads, non-repeatable reads, and phantom reads are prevented.
16. What is @EnableTransactionManagement for?
The @EnableTransactionManagement annotation to be used in on @Configuration classes and enable transactional support:
@Configuration
@EnableTransactionManagement
public class PersistenceJPAConfig{
@Bean
public LocalContainerEntityManagerFactoryBean
entityManagerFactoryBean(){
//...
}
@Bean
public PlatformTransactionManager transactionManager(){
JpaTransactionManager transactionManager
= new JpaTransactionManager();
transactionManager.setEntityManagerFactory(
entityManagerFactoryBean().getObject() );
return transactionManager;
}
}
Both @EnableTransactionManagement and <tx:annotation-driven ../> enable all infrastructure beans necessary for supporting transactional execution.
Components registered when the @EnableTransactionManagement annotation is used are:
- A TransactionInterceptor: calls to @Transactional methods
- A JDK Proxy or AspectJ advice, intercepts methods annotated with
@Transactional
@EnableTransactionManagement and <tx:annotation-driven/> only looks for @Transactional on beans in the same application context they are defined in. This means that, if you put annotation driven configuration in a WebApplicationContext for a DispatcherServlet it only checks for @Transactional beans in your controllers, and not your services.
17. What does transaction propagation mean?
Transaction propagation defines whether the current transaction will be extended or not.
There is an Enum that specifies the list of all possible propagation types – org.springframework.transaction.annotation.Propagation:
| REQUIRES_NEW | create a new transaction, suspend any existing one |
| MANDATORY | use current transaction, throw exception if none exists |
| REQUIRED | use current transaction, if non exists – create one |
| SUPPORTS | use current transaction, execute non-transactionally if none exists |
| NEVER | execute non-transactionally, throw exception if any transaction exists |
| NOT_SUPPORTED | execute non-transactionally, suspend any existing transaction |
| NESTED | if a transaction exists create a nested one in it and execute everything there, else behave like Propagation.REQUIRED |
It is to define behavior of the target methods: if they should be executed in an existing or new transaction, or no transaction at all.
Spring Propagation enum:
Propagation.REQUIRED:@Transactional(propagation = Propagation.REQUIRED)- Starts a new transaction if there is no transaction.
- An existing transaction is kept and the second method call is executed within the same transaction.
- If the second method throws an exception that causes rollback, the whole transaction rolls back. It doesn’t matter if the first transaction handles that exception or not.
- Transaction rolls back and throws
UnexpectedRollbackException.
Propagation.REQUIRES_NEW:- always starts a new transaction regardless of whether there is already an active one.
Propagation.NESTED.- there is only one active transaction that spans method calls.
- only available if your persistence technology is JDBC.
- it won’t work if you are using JPA or Hibernate.
JDBC savepointsare used to mark new method calls. When an exception occurs in the second method, the transaction until the last savepoint is rolled back
Propagation.MANDATORY.- An error occurs if there is not an active transaction.
Propagation.NEVER.- An error occurs if there is an active transaction in the system when the method is called.
Propagation.NOT_SUPPORTED:- If there is an active transaction when the method is called, the active transaction is suspended until the end of the method call.
Propagation.SUPPORTS.- current method work in a transaction if one already exists.
- Otherwise, the method will work without any transaction.
@Service
public class UserServiceImpl implements UserService {
@Transactional(propagation = Propagation.REQUIRED, readOnly= true)
@Override public User findById(Long id) {
return userRepo.findById(id);
}
}
18. What happens if one @Transactional annotated method is calling another @Transactional annotated method on the same object instance?
Since transaction-management is implemented using AOP @Transactional annotation will have no effect on the method being called as no proxy is created. The same behavior is characteristic of AOP aspects.
As per the limitation of Spring AOP, a self-invocation of a proxied Spring Bean effectively bypasses the proxy, thus the second method will be excuted in the same transaction with the first.
Service layer or Repository layer
Use @Transactional in the service layer or the DAO/ repository layer, but not both.
The service layer is the usual choice, because service methods call multiple repository methods that need to be executed in the same transaction.
The only reason to make your repositories transactional is if you do not need a service layer at all, which is usually the case for small educational applications.
19. Where can the @Transactional annotation be used? What is a typical usage if you put it at the class level?
If you put @Transactional at class-level this is equal to annotating each method of that class.
Class level:
- default for all methods of the declaring class
- method level transactional can override some attributes
- its subclasses
- does not apply to ancestor classes up the class hierarchy
Method level:
- Only Public method
- protected, private or package-visible methods with the @Transactional annotation, no error is raised, but the annotated method does not exhibit the congured transactional settings.
- If you need to annotate non-public methods, consider using AspectJ
Interface:
- this works only as you would expect it to if you use interface-based proxies
- recommends that you annotate only concrete classes and methods
20. What does declarative transaction management mean?
For declarative transaction management:
- It keeps transaction management out of business logic.
- Easy to configure. Use Java annotations or XML configuration files.
Basically, when those specified methods are called, Spring begins a new transaction, and when the method returns without any exception it commits the transaction; otherwise, it rolls back. Hence, you don’t have to write a single line of transaction demarcation code in your method bodies.
How It Works:
-
The
@EnableTransactionManagementannotation activates annotation‐based declarative transaction management.
-
Spring Container scans managed beans’ classes for the
@Transactionalannotation. -
When the annotation is found, it creates a proxy that wraps your actual bean instance.
-
From now on, that proxy instance becomes your bean, and it’s delivered from Spring Container when requested.
Programmatic transaction management is a good idea only if:
- Has only a small number of transactional operations. For example, if you have a web application that requires transactions only for certain update operations, you may not want to set up transactional proxies by using Spring or any other technology.
- Being able to set the transaction name explicitly.
21. What is the default rollback policy? How can you override it?
22. What is the default rollback policy in a JUnit test, when you use the
@RunWith(SpringJUnit4ClassRunner.class) in JUnit 4 or @ExtendWith(SpringExtension.class) in JUnit 5, and annotate your @Test annotated method with @Transactional?
23. Why is the term “unit of work” so important and why does JDBC AutoCommit violate this pattern?
JDBC AutoCommit will treat each individual SQL statement as a transaction. This means that if logically or from business point of view you need to make sure some statement is OK before executing another one, it would fail. Transactions are meant to solve this problem by “grouping” operations in some logical way so that you confirm to ACID principle (Atomicity, Consistency, Isolation, Durability).
- The unit of work describes the atomicity of transactions.
- JDBC AutoCommit will cause each individual SQL statement as to be executed in its own transaction, which makes it impossible to perform operations that consist of multiple SQL statements as a unit of work.
- JDBC AutoCommit can be disabled by calling the
setAutoCommit()to false on a JDBC connection.
24. What does JPA stand for – what about ORM?
JPA stands for Java Persistent API. ORM stands for Object Relational Mapping.
JPA: Java Persistence API. JPA is a POJO-based persistence mechanism that draws ideas from both Hibernate and Java Data Objects (JDO) and mixes Java 5 annotations in for good measure.
ORM: Object-Relational Mapping. Mappingg a java entity to SQL database table.
Benefits of using Spring’s JPA support in your data access layer:
- Easier and more powerful persistence unit configuration
- Automatic EntityManager management
- Easier testing
- Common data access exceptions
- Integrated transaction management
The first step toward using JPA with Spring is to configure an entity manager factory as a bean in the Spring application context. JPA-based applications use an implementation of EntityManagerFactory to get an instance of an EntityManager. The JPA specification defines two kinds of entity managers:
Application-managed
- the application is responsible for opening or closing entity managers and involving the entity manager in transactions.
- most appropriate for use in standalone applications that don’t run in a Java EE container.
EntityManagersare created by anEntityManagerFactoryobtained by calling thecreateEntityManagerFactory()method of the PersistenceProvider.- If you’re using an application-managed entity manager, Spring plays the role of an application and transparently deals with the EntityManager on your behalf.
LocalEntityManagerFactoryBeanproduces an application-managedEntityManagerFactory.- Application-managed entity-manager factories derive most of their configuration information from a configuration file called
persistence.xml. This file must appear in theMETA-INFdirectory in the classpath. The purpose of thepersistence.xmlfile is to define one or more persistence units.
@Bean
public LocalEntityManagerFactoryBean entityManagerFactoryBean() {
LocalEntityManagerFactoryBean emfb = new LocalEntityManagerFactoryBean();
emfb.setPersistenceUnitName("demo");
return emfb;
}
Container-managed
- Entity managers are created and managed by a Java EE container.
- The application doesn’t interact with the entity manager factory at all.
- Instead, entity managers are obtained directly through injection or from JNDI.
- The container is responsible for configuring the entity manager factories.
- most appropriate for use by a Java EE container that wants to maintain some control over JPA configuration beyond what’s specified in
persistence.xml. EntityManagerFactorysare obtained through PersistenceProvider’screateContainerEntityManagerFactory()method.- Spring plays the role of the container.
LocalContainerEntityManagerFactoryBeanproduces a container-managedEntityManagerFactory.- Instead of configuring data-source details in persistence.xml, you can configure this information in the Spring application context.
- JPA has two annotations to obtain container‐managed
EntityManagerFactoryorEntityManagerinstances within Java EE environments.- The
@PersistenceUnitannotation expresses a dependency on anEntityManagerFactory, and @PersistenceContextexpresses a dependency on a containermanagedEntityManagerinstance.
- The
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory( DataSource dataSource, JpaVendorAdapter jpaVendorAdapter) {
LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean();
emfb.setDataSource(dataSource);
emfb.setJpaVendorAdapter(jpaVendorAdapter);
return emfb;
}
25. What is the idea behind an ORM? What are the benefits/disadvantages or ORM?
ORM is to help map our domain or entity models into database tables. In the application level, we deal with objects and not with database operations.
Idea: Developers only work on objects and no need to care about how to maintain the relationship and how they persist.
ORM Duties:
- Data type convertion
- Maintaining relations between objects
- JAP Query language to handle vendor spedific SQL
Benefits:
- Easier testing. It’s easier to test each piece of persistence-related code in isolation.
- Common data access exceptions. In
DataAccessExceptionhierarchy. - General resource management. Spring offers effcient, easy, and safe handling of persistence resources. E.g., Spring makes it easy to create and bind a Session to the current thread transparently, by exposing a current Session through the Hibernate SessionFactory .
- Integrated transaction management. Declarative, aspect-oriented programming (AOP) style method interceptor.
- Keep track of changes
- Reduce code (and develop time)
- Lazy loading. As object graphs become more complex, you sometimes don’t want to fetch entire relationships immediately.
- Eager fetching. Eager fetching allows you to grab an entire object graph in one query.
- Cascading. Sometimes changes to a database table should result in changes to other tables as well
- Save you literally thousands of lines of code and hours of development time.
- Lets you switch your focus from writing error-prone SQL code to addressing your application’s requirements.
Disadvantage:
- Generated SQL Query low performance
- Complexity, requires more knowledge
- Deal with legacy database is difficult
26. What is a PersistenceContext and what is an EntityManager? What is the relationship between both?
JPA has two annotations to obtain container‐managed EntityManagerFactory or EntityManager instances within Java EE environments.
- The
@PersistenceUnitannotation expresses a dependency on anEntityManagerFactory, and @PersistenceContextexpresses a dependency on a containermanagedEntityManagerinstance.
@PersistenceUnit and @PersistenceContext
- They aren’t Spring annotations; they’re provided by the JPA specification.
- Both annotations can be used at either the field or method level.
- Visibility of those fields and methods doesn’t matter.
-
Spring’s
PersistenceAnnotationBeanPostProcessormust be configured explicitly: -
@Bean public PersistenceAnnotationBeanPostProcessor paPostProcessor() { return new PersistenceAnnotationBeanPostProcessor(); } -
if you do use Spring’s exception translation
@Bean public BeanPostProcessor persistenceTranslation() { return new PersistenceExceptionTranslationPostProcessor(); }@PersistenceContext- Used for entity manager injection.
- Expresses a dependency on a container-managed EntityManager and its associated persistence context.
- This field does not need to be autowired, since this annotation is picked up by an infrastructure Spring bean postprocessor bean that makes sure to create and inject an EntityManager instance.
- @PersistenceContext has a type attribute
PersistenceContextType.TRANSACTIONIn stateless beans, like singleton bean, it is safe to use only the PersistenceContextType.TRANSACTION value for a shared EntityManager to be created and injected into for the current activePersistenceContextType.EXTENDED- is purposefully designed to support beans, like stateful EJBs, session Spring beans, or request‐scoped Spring beans. The shared EntityManager instance wouldn’t be bound to the active transaction and might span more than one transaction.
PersistenceContext It’s essentially a Cache, containing a set of domain objects/entities in which for every persistent entity there is a unique entity instance.
- Default persistence context duration is one single transaction
- Can be configured
- the persistence context itself is managed by EntityManager
Persistence Unit:
a group of entity classes defined by the developer to map database records to objects that are managed by an Entity Manager, basically all classes annotated with @Entity, @MappedSuperclass, and @Embedded in an application.- All entity classes must define a primary key, must have a non-arg constructor or not allowed to be final.
- This set of entity classes represents data contained in a single datasource.
- Multiple persistence units can be defined within the same application.
- Configuration of persistence units can be done using XML, e.g.,
persistence.xmlfile under theMETA-INFdirectory. JPA no need to specify it.
EntityManager represents a PersistenceContext. The entity manager provides an API for managing a persistence context and interacting with the entities in the persistence context.
- It does creation, update, querying, deletion.
- An EntityManager isn’t thread-safe and generally shouldn’t be injected into a shared singleton bean like your repository.
@PersistenceContextdoesn’t inject an EntityManager—at least, not exactly. Instead of giving the repository a real EntityManager, it gives a proxy to a real EntityManager. That real EntityManager either is one associated with the current transaction or, if one doesn’t exist, creates a new one.
EntityManagerFactory
It has the responsibility of creating application-managed Entity Manager instances and therefore a PersistenceContext/Cache. Thread safe, shareable, represent a single datasource and persistence context.@Repository public class JpaUserRepo implements UserRepo { private EntityManager entityManager; @PersistenceContext void setEntityManager(EntityManager entityManager) { this.entityManager = entityManager; } }
27. Why do you need the @Entity annotation? Where can it be placed?
28. What do you need to do in Spring if you would like to work with JPA?
-
Declare dependencies: ORM dependency, db driver dependency, transaction manager dependency.
@Entityclasses- is part of the javax.persistence.*, not JPA!
@Entitymarks classes as templates for domain objects, also called entities to database tables.- The
@Entityannotation can be applied only at class level. @Entityare mapped to database tables matching the class name, unless specified otherwise using the@Tableannotation.@Entityand@Idare mandatory for a domain class.
- Define an EntityManagerFactory bean.
- Simplest:
LocalEntityManagerFactoryBean. It produces an application-managed EntityManagerFactory. - Obtain an
EntityManagerFactoryusing JNDI, use when app ran in Java EE server - Full JPA capabilities:
LocalContainerEntityManagerFactoryBean
- Simplest:
-
Define a
DataSourcebean -
Define a
TransactionManagerbean - Implement repositories
@Configuration
@EnableJpaRepositories
@EnableTransactionManagement
class ApplicationConfig {
@Bean
public DataSource dataSource() {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
return builder.setType(EmbeddedDatabaseType.HSQL).build();
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
vendorAdapter.setGenerateDdl(true);
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
factory.setPackagesToScan("com.acme.domain");
factory.setDataSource(dataSource());
return factory;
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
You must create LocalContainerEntityManagerFactoryBean and not EntityManagerFactory directly, since the former also participates in exception translation mechanisms in addition to creating EntityManagerFactory .
29. Are you able to participate in a given transaction in Spring while working with JPA?
Yes you can.
The Spring JpaTransactionManager supports direct DataSource access within one and the same transaction allowing for mixing plain JDBC code that is unaware of JPA with code that use JPA.
If the Spring application is to be deployed to a JavaEE server, then JtaTransactionManager can be used in the Spring application.
30. Which PlatformTransactionManager(s) can you use with JPA?
Implementations of PlatformTransactionManager interface. E.g.,
-
DataSourceTransactionManager: Suitable if you are only using JDBC HibernateTransactionManager- Hibernate without JPA
- Also possible to use JDBC at the same time
JpaTransactionManager:- Suitable if you are using JPA.
- Also possible to use JDBC at the same time
JdoTransactionManage- using JDO
- Also possible to use JDBC at the same time
JtaTransactionManager- Suitable if you are using global transactions—that is, the distributed transaction management capability of your application server.
- You can use any data access technology
-
WebLogicJtaTransactionManager
JtaTransactionManager is used for global transactions, so that they can span multiple resources such as databases, queues etc. If the application has multiple JPA entity manager factories that are to be transactional, then a JTA transaction manager is required.
When using JPA with one single entity manager factory, the Spring Framework JpaTransactionManager is the recommended choice. This is also the only transaction manager that is JPA entity manager factory aware.
31. What does @PersistenceContext do?
@PersistenceContext
- Used for entity manager injection.
- Expresses a dependency on a container-managed EntityManager and its associated persistence context.
- This field does not need to be autowired, since this annotation is picked up by an infrastructure Spring bean postprocessor bean that makes sure to create and inject an EntityManager instance.
- @PersistenceContext has a type attribute
- PersistenceContextType.TRANSACTION In stateless beans, like singleton bean, it is safe to use only the PersistenceContextType.TRANSACTION value for a shared EntityManager to be created and injected into for the current active
- PersistenceContextType.EXTENDED
- is purposefully designed to support beans, like stateful EJBs, session Spring beans, or request‐scoped Spring beans. The shared EntityManager instance wouldn’t be bound to the active transaction and might span more than one transaction.
PersistenceContext It’s essentially a Cache, containing a set of domain objects/entities in which for every persistent entity there is a unique entity instance.
- Default persistence context duration is one single transaction
- Can be configured
- the persistence context itself is managed by EntityManager
32. What do you have to configure to use JPA with Spring? How does Spring Boot make this easier?
To use Spring Data components in a JPA project, a dependency on the package spring-data-jpa must be introduced.
JPA in SpringBoot
- SpringBoot provides a default set fo dependencies needed for JPA in starter.
- Provides all default Spring beans needed to use JPA.
- Provides a number of default properties related to persistence and JPA.
Disable Spring Data Auto Configuration in SpringBoot:
It’s useful in testing.
-
Disable Using Annotation
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class, DataSourceTransactionManagerAutoConfiguration.class, HibernateJpaAutoConfiguration.class}) -
Disable Using Property File
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration, org.springframework.boot.autoconfigure.orm.jpa.HibernateJpaAutoConfiguration, org.springframework.boot.autoconfigure.jdbc.DataSourceTransactionManagerAutoConfiguration
33. What is an “instant repository”? (hint: recall Spring Data)
A Spring Data repository is also known as a “instant” repository, because they can be created instantly by extending one of the Spring-specialized interfaces.
When a custom repository interface extends JpaRepository, it will automatically be enriched with functionality to save entities, search them by ID, retrieve all of them from the database, delete entities, flush, etc.
By default, repositories are instantiated eagerly unless explicitly annotated with @Lazy. LAZY is a decent choice for testing scenarios.
34. How do you define an “instant” repository? Why is it an interface not a class?
Under the hood, Spring creates a proxy object that is a fullly functioning repository bean. The repository implementation is generated at application startup time, as the Spring application context is being created.
Any additional functionality that is not provided by default can be easily implemented by defining a method skeleton and providing the desired functionality using annotations. It’s including an implementation of all 18 methods inherited from
- JpaRepository,
- PagingAndSortingRepository, and
- CrudRepository.
JDBC Support typical JDBC support. You could have the DataSource injected into an initialization method, where you would create a JdbcTemplate and other data access support classes
@Repository
public class JdbcMovieFinder implements MovieFinder {
private JdbcTemplate jdbcTemplate;
@Autowired
public void init(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
}
JPA repository JPA-based repository needs access to an EntityManager.
@Repository
public class JpaMovieFinder implements MovieFinder {
@PersistenceContext
private EntityManager entityManager;
}
classic Hibernate APIs inject SessionFactory
@Repository
public class HibernateMovieFinder implements MovieFinder {
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
}
35. What is the naming convention for finder methods?
findBy+fieldName e.g findByEmail to find an entity by its email.
- verbs in the method name: get, read, find, query,stream and count.
-
prefixes findalso can be replaced with readget query stream private static final String QUERY_PATTERN = "find|read|get|query|stream"; - findAllByXxx()
arefindByXxx()` identical. - The
countverb, on the other hand, returns a count of matching objects, rather than the objects themselves.
-
- The subject of a repository method is optional.
readSpittersByFirstnameOrLastname()=readByFirstnameOrLastname()readPuppiesByFirstnameOrLastname()=readThoseThingsWeWantByFirstnameOrLastname()- They’re all requal! Beccause the type of object being retrieved is determined by how you parameterize the JpaRepository interface, not the subject of the method name.
- There is one exception to the subject being ignored. If the subject starts with the word
Distinct, then the generated query will be written to ensure a distinct result set.
- The
predicatespecifies the properties that will constrain the result set.- Each condition must reference a property and may also specify a comparison operation.
- If the comparison operator is left off, it’s implied to be an equals operation.
- You may choose any other comparison operations,
- When dealing with
Stringproperties, the condition may also includeIgnoringCaseorIgnoresCase. - you may also use
AllIgnoringCaseorAllIgnoresCaseafter all the conditions to ignore case for all conditions - conditional parts are separated by either
AndorOr
- Limiting Query Results
- The results of query methods can be limited by using the
firstortopkeywords - An optional numeric value can be appended to top or first to specify the maximum result size to be returned.
- If the number is left out, a result size of 1 is assumed.
- The results of query methods can be limited by using the
User findFirstByOrderByLastnameAsc(); User findTopByOrderByAgeDesc(); Page<User> queryFirst10ByLastname(String lastname, Pageable pageable); Slice<User> findTop3ByLastname(String lastname, Pageable pageable); List<User> findFirst10ByLastname(String lastname, Sort sort); List<User> findTop10ByLastname(String lastname, Pageable pageable);
36. How are Spring Data repositories implemented by Spring at runtime?
For a Spring Data repository a JDK dynamic proxy is created which intercepts all calls to the repository.
The default behavior is to route calls to the default repository implementation, which in Spring Data JPA is the SimpleJpaRepository class.
37. What is @Query used for?
Spring @Query annotation is used for customizing methods of some instant repository.
@Query allows for specifying a query to be used with a Spring Data JPA repository method.
When the name of the named parameter is the same as the name of the argument in the method annotated with @Query, the @Param annoation is not needed.
But if the method argument has a different name, the @Param annotation is needed to tell Spring that the value of this argument is to be injected in the named parameter in the query.
Queries annotated to the query method take precedence over queries defined using @NamedQuery or named queries declared in orm.xml .
Annotation-based configuration has the advantage of not needing another cofiguration file to be edited, lowering maintenance effort.
@Query("select p from Person u where p.name like %?1%")
List<Person> findAllByName(String name);
@Query("select p from Person p where p.name= :n")
Person findOneByName(@Param("n") String name);
@Query("select p.name from Person p where p.id= :id")
String findNameById(Long id);
AOP
1. What is the concept of AOP?
AOP is Aspect Oriented Programming. AOP is a type of programming that aims to help with separation of cross-cutting concerns to increase modularity; it implies declaring an aspect class that will alter the behavior of base code, by applying advices to specific join points, specified by pointcuts.
2. What problems does it solve? What two problems arise if you don’t solve a cross cutting concern via AOP?
Aims to help with separation of cross-cutting concerns to increase modularity.
- Avoid tangling: mixing business logic and cross cutting concerns
- Avoid scattering: code duplication in several modules
Code tangling and code scattering are two issues that come together when base code needs to be executed under certain conditions. Code tangling means that the same component is injected into many others, thus leading to significant dependencies coupling components together. Code scattering means duplication, because you can do the same thing in only one way. The resulting solution is difficult to extend and to maintain, harder to understand, and a pain to debug.
3. What is a cross cutting concern?
A cross-cutting concern is a functionality that is tangled with business code, which usually cannot be separated from the business logic.
4. Name three typical cross cutting concerns.
- Auditing
- Security
- Transaction management
Other examples of cross-cutting concerns
- Logging
- Caching
- Internationalization
- Error detection and correction
- Memory management
- Performance monitoring
- Measuring statistics
- Synchronization
Not a cross-cutting concerns
- connecting to the database
Two popular AOP libraries
- AspectJ is the original AOP technology which aims to provide complete AOP solution. More robust, more complicated. It uses three different types of weaving:
- Compile-time weaving
- Post-compile weaving
- Load-time weaving
It doesn’t do anything at runtime as the classes are compiled directly with aspects.
- Spring AOP aims to provide a simple AOP implementation across Spring IoC to solve the most common problems that programmers face. It makes use of only runtime weaving.
- JDK dynamic proxy, preferred
- CGLIB proxy
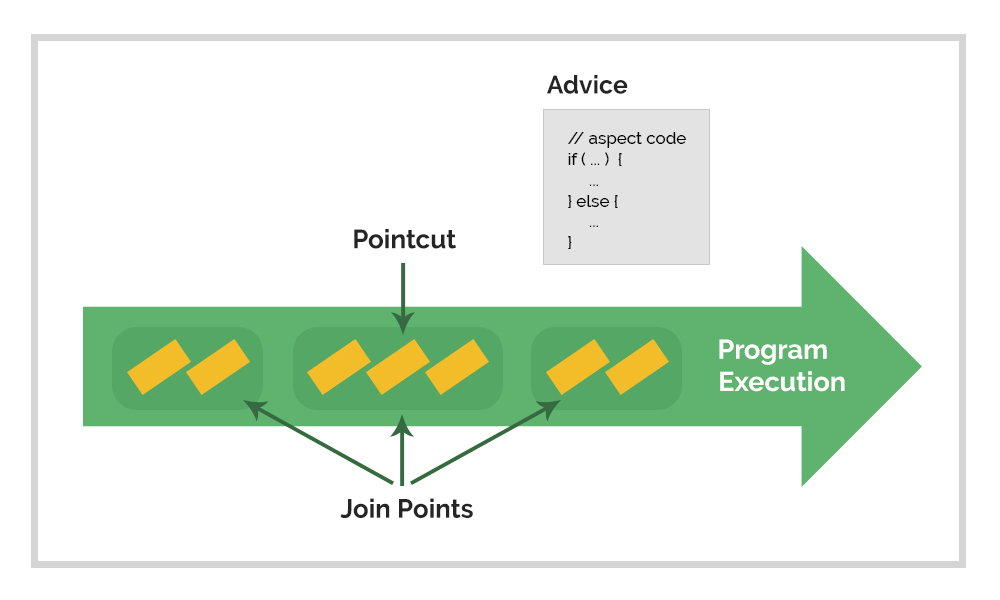
6. What is a pointcut, a join point, an advice, an aspect, weaving?
Pointcut
– An expression that selects one or more Join Points
Join Point
– A point in the execution of a program such as a method call or exception thrown
Advice
– Code to be executed at each selected Join Point
Aspect
– A module that encapsulates pointcuts and advice
Weaving
– Technique by which aspects are combined with main code
Introduction
-Spring AOP allows to introduce new interfaces (and a corresponding application) to any object advises.
Target Object
-An object is assisted by one or more respects. Also known as the object advised.
AOP Proxy
-AOP proxy is an object used to perform the contract area. This object is created by the AOP framework. In Spring AOP proxy is part of JDK dynamic proxy or proxy CGLIB.
7. How does Spring solve (implement) a cross cutting concern?
- Implement your mainline application logic
- – Focusing on the core problem
- Write aspects to implement your cross-cutting concerns
- – Spring provides many aspects out-of-the-box
- Weave the aspects into your application
- – Adding the cross-cutting behaviors to the right places
8. Which are the limitations of the two proxy-types?
Spring will create either JDK or CGLib proxies
- JDK Proxy
- Also called dynamic proxies
- API is built into the JDK
- Requirements: Java interface(s)
- All interfaces proxied
- CGLib Proxy
- NOT built into JDK
- Included in Spring jars
- Used when interface not available
- Cannot be applied to final classes or methods
9. What visibility must Spring bean methods have to be proxied using Spring AOP?
For JDK proxies, only public interface method calls on the proxy can be intercepted. With CGLIB, public and protected method calls on the proxy will be intercepted, and even package-visible methods if necessary. However, common interactions through proxies should always be designed through public signatures.
10. How many advice types does Spring support. Can you name each one? What are they used for?
-
Advice: action taken by an aspect at a join point.
- Before advice:
@Beforealways proceed to the join point unless an execution is thrown from within the advice code- Access control, security
- Statistics
- After returning advice:
@AfterReturningexecution of a join point has completed without throwing any exceptions- statistics
- Data validation
- After throwing advice:
@AfterThrowinginvoked after the execution of a join point that resulted in an exception being thrown- Error handling
- Sending alerts when an error has occurred.
- Attempt error recovery
- After (finally) advice:
@Aftermethod will execute after a join point execution, no matter how the execution ended (even exception happens).- Releasing resources
- Around:
@AroundAround advice can be used for all of the use-cases for AOP.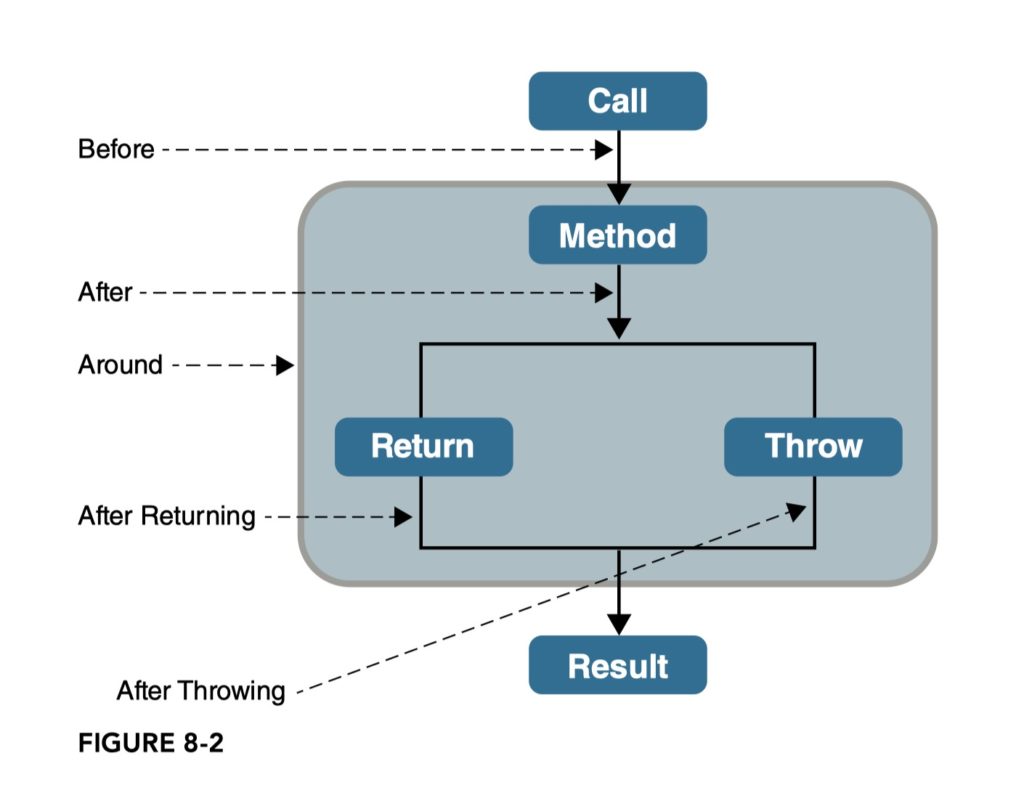
11. Which two advices can you use if you would like to try and catch exceptions?
@Around. Only around advice allows you to catch exceptions in an advice that occur during execution of a join point.
@Aspect
public class Audience {
@Pointcut("execution(** concert.Performance.perform(..))")
public void performance() {}
@Around("performance()")
public void watchPerformance(ProceedingJoinPoint jp) {
try {
System.out.println("Taking seats");
jp.proceed();
System.out.println("CLAP CLAP CLAP!!!");
} catch (Throwable e) {
System.out.println("Demanding a refund");
}
}
}
@AfterThrowing. After throwing advice runs when a matched method execution exits by throwing an exception. The type Throwable is the superclass of all errors and exceptions in the Java language. So, the following advice will catch any of the errors and exceptions thrown by the join points.
@Aspect
public class CalculatorLoggingAspect {
@AfterThrowing(
pointcut = "execution(* *.*(..))",
throwing = "e")
public void logAfterThrowing(JoinPoint joinPoint, Throwable e) {
log.error("An exception {} has been thrown in {}()", e, joinPoint.getSignature().getName());
}
}
12. What do you have to do to enable the detection of the @Aspect annotation?
3 ways of declaring Spring AOP configuration
- the ProxyFactoryBean,
- the aop namespace,
- and @AspectJ-style annotations.
What does @EnableAspectJAutoProxy do?
If shown pointcut expressions, would you understand them?
For example, in the course we matched getter methods on Spring Beans, what would be the
correct pointcut expression to match both getter and setter methods?
What is the JoinPoint argument used for?
What is a ProceedingJoinPoint? When is it used?
Core Spring
What is dependency injection?
IoC is also known as dependency injection (DI). It is a process whereby objects define their dependencies (that is, the other objects they work with) only through constructor arguments, arguments to a factory method, or properties that are set on the object instance after it is constructed or returned from a factory method. The container then injects those dependencies when it creates the bean. This process is fundamentally the inverse (hence the name, Inversion of Control) of the bean itself controlling the instantiation or location of its dependencies by using direct construction of classes or a mechanism such as the Service Locator pattern.
Dependency Injection is a form of Inversion of Control used by containers like Spring to customize beans (the bean – as objects managed by Spring IoC container are called beans) or apply some given implementations on objects whose customizations are defined using interfaces. Techniques used for customizing the beans are constructor and setter injection – in that case, you have to define a constructor that will accept certain implementation for the object field as a parameter.
what are the advantages of Dependency Injection?
- Code is more reusable – DI code becomes more generic and suitable for more implementation.
- Code is cleaner.
- Decoupling is more effective – less/or no direct dependencies are used the bean is less prone to be affected by changes in its dependencies.
- Classes become easier to test – interfaces or abstract classes are used for fields, one can use stubs or mocks implementations to be used while unit testing.
What is pattern?
Design patterns represent the best practices used by experienced software developers. Imagine them as solutions to general problems that software developers face during software development. They are well established and it is very vital for you to learn about them. Why would you reinvent the wheel, when you can just use it?
There is a lot of different design patterns out there.
- Creational patterns – Singleton, Prototype, Builder…
- Structural patterns – Proxy, Facade, Decorator…
- Behavioral patterns – Command, Observer, Template method…
What is an anti-pattern?
An anti-pattern is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive. Imagine it is the opposite of what the pattern means.
Is dependency injection a design pattern?
Yes. Dependency injection is a pattern.
What is an interface and what are the advantages of making use of them in Java?
Interface is very powerful to run time injection of various concrete implementations of an interface in the application. By using references to interfaces instead of their concrete implementation classes help to minimize ripple effects, as the user of interface reference doesn’t have to worry about the changes in the underlying concrete implementation. Interface is an abstract representation of a class. In Spring using an interface for some field in a class allows for automatic substituting with required specific implementation – this will be done by DI.
Why are they recommended for Spring beans?
When Spring beans are implementing interfaces, it is very easy to change the interface implementations. You can simply exchange entire beans by changing the Spring configuration, but you don’t have to make any changes to the code.
What is meant by “application-context?
The ApplicationContext is the central interface of the Spring framework. It provides you with access to your Spring configuration.
How are you going to create a new instance of an ApplicationContext?
ApplicationContext context = new ClassPathXmlApplicationContext("config_file.xml");
What is the concept of a “container” and what is its lifecycle?
Spring container is an “environment” for the beans to live. The container creates, configures and wires beans together. Spring has many container implementations but actually you can divide them in 2 types
- BeanFactory – a simple container with basic support for DI
- ApplicationContext – a more advanced container that has support for getting values from property files or sending events to different listeners.
When an ApplicationContext is created several things happen:
- BeanDefinition creation
- Customizing BeanDefinitions by BeanFactoryPostProcessor
- Custom FactoryBeans creation
- BeanFactory instantiates beans instances
- Beans customization by BeanPostProcessor
The ApplicationContext lets you read bean definitions and access them, as the following example shows:
// create and configure beans
ApplicationContext context = new ClassPathXmlApplicationContext("services.xml", "daos.xml");
// retrieve configured instance
PetStoreService service = context.getBean("petStore", PetStoreService.class);
// use configured instance
List<String> userList = service.getUsernameList();
Scopes for Spring Beans. What is the default?
Configuration metadata allows for defining 7 types of bean scopes. 5 of these scopes are available only if the ApplicaitonContext chosen implementation is web-aware, for example XmlWebApplicationContext or you’ll get an IllegalStateException meaning the selected scope is “unknown”.
- singleton – the default scope for the beans. Will ensure that only one instance of the bean will be created per current IoC container (Spring container). Used for stateless beans.
- prototype – any number of bean instances may be created. Used for stateful beans. For this type of beans configured destruction lifecycle callbacks are not called. User must clean up this type of objects and release the resources that they are holding; usually using custom bean post-processor for that.
- request – a bean instance will be created per each HTTP request. @RequestScope may be used with @Component to assign this scope.
- session – one instance per HTTP Session lifecycle. @SessionScope may be used with @Component to assign this scope.
- globalSession – one instance per HTTP global Session. Usually only valid when used in a Portlet context
- application – one instance per ServletContext. @ApplicationScope may be used with @Component to assign this scope.
- websocket – one instance per WebSocket
Can you describe the lifecycle of a Spring Bean in an ApplicationContext?

Spring bean factory is responsible for managing the life cycle of beans created through spring container. The life cycle of beans consist of call back methods which can be categorized broadly in two groups: Post initialization call back methods and Pre destruction call back methods
Destroy method is the method that is called when the container containing it is destroyed (closed)
Initialization method is a method that does some initialization work after all the properties of the bean were set by the container.

How are you going to create an ApplicationContext in an integration test?
It is possible to create ApplicationContext with @ContextConfiguration or @WebApplicationContext annotation.
@RunWith(SpringRunner.class)
// ApplicationContext will be loaded from AppConfig and TestConfig
@ContextConfiguration(classes = {AppConfig.class, TestConfig.class})
public class MyTest {
// class body...
}
What is the preferred way to close an application context? Does Spring Boot do this for you?
There is no need to register a shutdown hook in a web application. Spring web-based ApplicationContext implementations already have shutdown code in place.
In a non-web application, you should register a shutdown hook with the JVM. This hook will ensure, that ApplicationContext will be closed gracefully and it calls the relevant destroy methods on singleton beans (remember, that destroy callbacks are not called on prototype-scoped beans). You can register shutdown hook via ConfigurableApplicationContext. If you are using Spring Boot, then it will register this hook automatically for you.
public class Application {
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context =
new ClassPathXmlApplicationContext("beans.xml");
// add a shutdown hook for the above context...
context.registerShutdownHook();
// app runs here...
// main method exits, hook is called prior to the app shutting down...
}
}
What is an initialization method and how is it used in Spring?
Initialization method is a method that does some initialization work after all the properties of the bean were set by the container. It can be done in different ways:
- using XML init-method attribute for <bean>
- using initMethod attribute of @Bean
- using @PostConstruct annotation
- implementing InitializingBean and overriding afterPropertiesSet method
- in case there is a default-init-method attribute set for <beans> and the bean has a method whose name matches that attribute – it will be the initialization method, although this can be overridden using init-method in a specific <bean>
can you describe dependency injection using Java configuration?
Spring IoC container manages objects or beans. To configure and manage beans you need configuration metadata. One of the ways to create configuration metadata is by using java code. You can use @Configuration to annotate a class whose purpose is to create beans.
The @Bean annotation informs Spring container, that the method will instantiate and configure a new object to be managed by the container.
@Configuration
public class AppConfig {
@Bean
public UserService userService() {
return new UserService();
}
@Bean
public UserService userService(UserRepository userRepository) {
// userRepository will be automatically resolved by the Spring container
// it can be used for constructing UserService bean
return new UserService(userRepository);
}
}
Note here that the bean’s name will be the same as the method name.
@Autowired private UserService userService;
If you want a different name you can change the name of the bean like this.
@Bean(name="userBean")
public UserService userService() {
return new UserService();
}
...
@Autowired
private UserService userBean;
or you can do this.
@Bean
public UserService userService() {
return new UserService();
}
...
@Autowired
@Qualifier("userService")// the name of the bean
private UserService userBean;
or
@Resource(name="userService")// the name of the bean
private UserService userBean;
can you describe dependency injection using annotations (@Component, @Autowired)?
@Component annotation is used to mark a class as a Bean. You use @Component together with @ComponentScan which scans classes within a package and provides metadata for the IoC container to create beans. @Component will set the bean name derived from the class name, but if you need to set the name explicitly you just need to supply it in the brackets like @Component(“beanName”).
@Configuration
@ComponentScan(basePackages= {"bean.package"})
class AppConfig {
}
or
@Configuration
@ComponentScan(basePackageClasses={UserService.class})
class AppConfig {
}
@Autowired is used to provide a reference of a bean to be used. Instead of an explicit definition of a bean dependency, it is possible to ask Spring to provide dependencies automatically. This is called auto wiring. @Autowired can be used at constructors, methods, and fields.
For auto wiring Spring does this:
- Spring tries to resolve candidates by the type first.
- If multiple candidates exist, Spring tries to resolve the dependency by its name
- If multiple candidates are found, and Spring cannot decide which should be used, an exception is thrown
- If no candidates are found, an exception is thrown
- It is possible to auto-wire beans collection of the given type
- If ambiguity exists, we can specify autowire candidate by the @Qualifier or @Primary annotation
- It is possible to use Java 8 Optional for optional dependencies
@RestController
public class UserController {
@Autowired
private UserService userService;
}
Spring allows for using @Named and @ManagedBean instead of @Component. Spring also allows you to use @Inject and @Resource instead of @Autowired.
can you describe component scanning, Stereotypes, and Meta-Annotations?
Spring allows marking your class as a bean ready for component-scanning using the following annotations:
- @Component – most generic stereotype annotation. Other annotations are specializations of the @Component annotation. Use it, when more specific annotation does not fit for your purpose.
- @Service – marks a class as a member of the service layer.
- @Repository – for beans that represent a DAO. It marks a class as a member of the repository layer. All exception thrown from this class will be wrapped and translated to the Springs
- @Controller – marks a class as an annotated controller. Methods of such class will be used for handling of the incoming http requests.
You can use in all the above cases the @Component annotation but using a specific annotation may be a better idea due to automatic translation of exceptions (in @Repository case) and future possible meanings in Spring.
Spring can automatically detect your stereotype classes and instantiate beans defined inside those classes. To allow autodetection, it is needed to add the @ComponentScan annotation on your @Configuration class.
By default, components will be searched from the package, where @ComponentScan annotation is defined. If you want to scan for the components from other packages, you can define base package with @ComponentScan(“com.springcertified”)
It is possible to create composed annotations by joining several annotations together. Such meta-annotations can simplify your code and make it more readable. As an example, here is definition of the @RequestScope annotation. As you can see, it is based on the more generic @Scope annotation:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Scope(WebApplicationContext.SCOPE_REQUEST)
public @interface RequestScope {
/**
* Alias for {@link Scope#proxyMode}.
* <p>Defaults to {@link ScopedProxyMode#TARGET_CLASS}.
*/
@AliasFor(annotation = Scope.class)
ScopedProxyMode proxyMode() default ScopedProxyMode.TARGET_CLASS;
}
can you describe scopes for Spring beans? What is the default scope?
The scope is like a prescript, which defines the way how the bean instances are created from the bean definitions. With the Java-based configuration, it’s possible to set the bean scope with the following annotation on the bean method:
@Scope("prototype")
@Bean
public UserService userService() {
return new UserService();
}
Basic Scopes
- singleton – the default scope for the beans. Will ensure that only one instance of the bean will be created per current IoC container (Spring container). Used for stateless beans.
- prototype – any number of bean instances may be created. Used for stateful beans. For this type of beans configured destruction lifecycle callbacks are not called. User must clean up this type of objects and release the resources that they are holding; usually using custom bean post-processor for that.
Additional beans for web application
- request – a bean instance will be created per each HTTP request. @RequestScope may be used with @Component to assign this scope.
- session – one instance per HTTP Session lifecycle. @SessionScope may be used with @Component to assign this scope.
- globalSession – one instance per HTTP global Session. Usually only valid when used in a Portlet context
- application – one instance per ServletContext. @ApplicationScope may be used with @Component to assign this scope.
- websocket – one instance per WebSocket
Are beans lazily or eagerly instantiated by default? How do you alter this behavior?
Beans are eagerly instantiated by default. This way, Spring is able to recognize issues in the configuration very early – usually during application startup. If you want to instantiate bean lazily, you can change it with the proper configuration.
@Bean
@Lazy
public UserService userService() {
return new UserService();
}
If you want to have all beans initialized in lazy fashion, you don’t have to specify lazy initialization for the every bean. You can alter the behavior by the configuration of the lazy initialization for all beans.
@Configuration
@ComponentScan(lazyInit = true)
class AppConfig {
@Bean
public UserService userService() {
return new UserService();
}
}
If you have a lazy bean instantiated within a non-lazy bean than that lazy bean will be an eager instantiated bean.
What is a property source? How would you use @PropertySource?
Property source is a set of properties. Properties are usually added to the application in the form of the standard Java property files. Spring application usually has multiple property sources registered. Some of them are registered by default, but usually every application adds own property source.
server.port=9090 # devtools spring.devtools.livereload.enabled=true spring.devtools.restart.enabled=true
To access a property value you need to use the property key. For example to get the server.port. Spring will search property sources hierarchically and returns the desired property value for server.port.
@Value("${server.port}")
private int portNumber;
Property sources are searched in the following order:
- ServletConfig parameters (if applicable — for example, in case of a DispatcherServlet context)
- ServletContext parameters (web.xml context-param entries)
- JNDI environment variables (java:comp/env/ entries)
- JVM system properties (-D command-line arguments)
- JVM system environment (operating system environment variables)
- You can also add your own property file using @PropertySource.
@Configuration
@PropertySource("classpath:app.properties")
public class AppConfig {
@Autowired
Environment env;
@Bean
public UserService userService() {
UserService userService = new UserService();
userService.setPort(env.getProperty("server.port"));
return userService;
}
}
What is a BeanFactoryPostProcessor and what is it used for? When is it invoked?
BeanFactoryPostProcessor is an interface that allows for defining customizing BeanDefinitions for future beans before those beans are created. The BeanFactoryPostProcessor is a special kind of object registered in ApplicationContext . Its main purpose is to alter BeanFactory before the beans are instantiated. That means, that BeanFactoryPostProcessor operates on raw bean definitions, not on the bean instances.
Why would you define a static @Bean method?
To ensure, that it will be ready in such an early stage, you should register it via static bean method. The static method declaration will avoid the requirement to have the declaring class to be instantiated. When defining a method that returns a bean of BeanFactoryPostProcessor type it is best to declare it as static because of the fact that this type of beans requires very early initialization and thus the must not be affected by @Autowire, @PostConstruct and @Value annotations from a @Configuration annotated class.
What is a ProperySourcesPlaceholderConfigurer used for?
The PropertySourcesPlaceholderConfigurer is Springs internal implementation of the BeanFactoryPostProcessor . Its main purpose is to resolve ${…} placeholders within bean definition property values and @Value annotations with appropriate values loaded from the property sources.
public class UserService {
private int concurentUsers;
@Value("${app.configuration.concurent.users}")
public void setConcurentUsers(int concurentUsers) {
this.concurentUsers = concurentUsers;
}
}
The PropertySourcesPlaceholderConfigurer iterates over all bean definitions before they are created. When property defined via ${…} is found, it is replaced by the appropriate value from the property sources. When no such property is found, an exception is thrown. This bean is used for defining the location of the properties file to be used in assigning values to bean properties. But it also allows for searching the required value in the system and/or environment variables.
What is a BeanPostProcessor and how is it different to a BeanFactoryPostProcessor? What do they do? When are they called?
What is an initialization method and how is it declared on a Spring bean?
Initialization method is a special method, which is called by the ApplicationContext during the bean initialization phase. Consider the following class. It contains a method named doInitialization , which performs custom steps we want to execute when the bean is initialized
@Bean(initMethod = "doInitialization")
public void userService() {
return new UserService();
}
...
public UserService {
public UserService() {
// normal constructor
}
public void doInitialization() {
//... perform some init steps
}
}
What is a destroy method, how is it declared and when is it called?
If you want to execute some cleanup code when the bean is destroyed, you can configure the so-called destroy method. Consider following class containing doCleanup method.
@Bean(destroyMethod = "doCleanup")
public void userService() {
return new UserService();
}
...
public UserService {
public UserService() {
// normal constructor
}
public void doCleanup() {
//... perform some cleanup steps
}
}
Note that destroy callbacks are never called on Prototype scoped beans.
Consider how you enable JSR-250 annotations like @PostConstruct and @PreDestroy? When/how will they get called?
It is possible to define initialization and destroy callbacks by using @PostConstruct and @PreDestroy annotations. Those annotations are not part of the Spring framework, but they are defined directly in Java language as part of JSR-250 specification request.
Spring recognizes those annotations with the help of the CommonAnnotationBeanPostProcessor . The purpose of this bean post processor is to find bean methods annotated with @PostConstruct and @PreDestroy annotations, and register desired callbacks within ApplicationContext.
The CommonAnnotationBeanPostProcessor will be registered automatically when component scan is turned on, or it can be added to the bean configuration manually if component scan is not used. Usage of the annotations is then pretty straightforward.
public class UserService {
public UserService() {}
@PostConstruct
protected void initialize() {
// initialization code
}
@PreDestroy
protected void destroy() {
// destroy code
}
}
How else can you define an initialization or destruction method for a Spring bean?
Register initialization and destroy callbacks is to implement InitializingBean and DisposableBean interfaces.
The InitializingBean interface contains a single method named afterPropertiesSet() .
public class UserService implements InitializingBean {
public UserService() {
@Override
public void afterPropertiesSet() throws Exception {
// initialization code
}
}
The DisposableBean interface contains a single method named destroy(). Remember, that destroy callbacks are not triggered on the prototype-scoped beans.
public class UserService implements DisposableBean {
public UserService() { }
@Override
public void destroy() throws Exception {
// destroy code
}
}
What does component scanning do?
Component scanning scans a package or a set of packages for classes that are annotated with @Component, @Controller, @Service and @Repository and configure those classes as beans. These beans will be added automatically to the ApplicationContext without you, the developer, having to declare them explicitly using @Bean in a @Configuration or in an XML configuration metadata file. By using @ComponentScan you are scanning the package that corresponds to the package of the current @Configuration. In case you need to specify a custom package or more packages you have to use:
// scan package where this class is in
@Configuration
@ComponentScan
public class AppConfig {
}
// scan com.foo and com.boo packages
@Configuration
@ComponentScan(basePackages={"com.foo","com.boo"})
public class AppConfig {
}
// scan UserServiceImp.class and PaymentMethodServiceImp.class classes
@ComponentScan(basePackageClasses={UserServiceImp.class, PaymentMethodServiceImp.class})
public class AppConfig {
}
What is the behavior of the annotation @Autowired with regards to field injection, constructor injection and method injection?
@Autowired tries to find a matching bean by type and inject it at the place on annotation – that may be a constructor, a method (not only setter, but usually setter) and field.
In case no bean is found an exception will be thrown; to skip this you can set the required attribute of @Autowired to false, and in that case you have to pay attention to possible null values related exceptions.
In case of ambiguity there are 2 approaches:
- @Primary annotation to identify a “preferable” bean among different implementations of an interface
- @Qualifier annotation to indicate directly the preferred bean.
What do you have to do, if you would like to inject something into a private field? How does this impact testing?
It does not matter because Spring uses reflection or setter methods to assign values to beans. So it does not matter whether you use private or public fields.
How does the @Qualifier annotation complement the use of @Autowired?
@Autowiring + @Qualifier combination is used to identify or inject a bean by name. This combination can be used but it is better to use @Resource when trying to inject by name.
@Component("staff")
public Staff implements Person {}
@Component("employee")
public Manager implements Person {}
@Component
public PayrollService {
@Autowired
@Qualifier("employee")
private final Person person;
}
What is a proxy object and what are the two different types of proxies Spring can create?
Proxy objects are objects that replace beans that should be injected in a singleton bean but are themselves lazily instantiable. For example in a singleton bean, you have a dependency on a session scoped bean. In this case at the container startup, Spring will instantiate the singleton bean and during this process, it will already need the bean that is session scoped. So here we have a problem. So we can benefit from a proxy object that will mimic the bean that we actually need. But here comes another problem. Our dependency may be defined as an interface or as a class. So for each case one of the two types of proxies will be created:
- Interface proxy(created by Spring itself)
- Class proxy(generated by CGLib)
Interface proxy is created by Spring itself while class proxy is generated by CGLib.
@Component
@Scope(proxyMode = ScopedProxyMode.INTERFACES, scopeName = "session")
public class UserServiceImp implements UserService{
}
○ What are the limitations of these proxies (per type)?
Limitation of Interface type
– Proxied class must implement interfaces
Limitation of Class type
– Proxied class must provide a default constructor
– Final methods won’t allow for using CGLib proxying
– Resulting proxy is final (you cannot proxy a proxy)
○ What is the power of a proxy object and where are the disadvantages?
What are the advantages of Java Config? What are the limitations?
Biggest advantage of JavaConfig is type safety or compile-time check. Another advantage is the possibility to use someone other’s classes. The limitation is that you cannot change the configuration dynamically – you have to rebuild the project.
Search is much simpler, refactoring will be bliss. Finding a bean definition will be far easier.
XML based on configuration can quickly grow big. Yes, we can split and import but still.
What does the @Bean annotation do?
@Bean annotation is used on methods that will return beans as return types. It is used to indicate that a method produces a bean to be managed by the Spring container. Typically @Bean is used in configuration classes. Bean methods may reference other @Bean methods in the same class by calling them directly.
@Configuration
public class AppConfig {
@Bean
public FooService fooService() {
return new FooService(fooRepository());
}
@Bean
public FooRepository fooRepository() {
return new JdbcFooRepository();
}
}
What is the default bean id if you only use @Bean? How can you override this?
In a configuration class, the name of the bean in case you use @Bean on a method will instantiate a bean with the name matching the method name.
You can override this by using the name attribute of the @Bean annotation to name your bean to a name.
@Bean(name="memberService")
public UserService userService() {
return new UserServiceImp();
}
Why are you not allowed to annotate a final class with @Configuration
Spring requires for subclassing classes(Spring creates dynamic proxies) annotated with @Configuration (for example to check if a bean exists before calling for its creation). But a final class cannot be extended so you cannot make a proxy of a final class.
○ How do @Configuration annotated classes support singleton beans?
○ Why can’t @Bean methods be final either?
because bean methods must be proxied and final methods can be extended.
How do you configure profiles?, What are possible use cases where they might be useful?
You use @Profile to configure beans to behave according to a particular environment. Like for example you might want to use certain endpoints in dev to short cut testing but in prod you cannot have those endpoints.
Can you use @Bean together with @Profile?
Yes you can. @Profile can be used on a configuration class or bean method.
@Configuration
@Profile("dev")
public class AppConfig {
}
....
@Profile("dev")
@Bean
public FooService fooService() {
return new FooService(fooRepository());
}
Can you use @Component together with @Profile?
Yes you can.
@Profile("dev")
@Component
public class UserServiceImp implements UserService {
}
How many profiles can you have?
Multiple profiles can be activated at once.
How do you inject scalar/literal values into Spring beans?
Depending on the beans wiring style you can use different methods to inject scalar/literal values:
- for Java-based configurations: use @Value annotation at constructor arguments, over properties and at setter methods
- for XML-based configurations: c-namespace for constructors and p-namespace for properties
@Component
public class SomeBean{
@Value("Some title") //at property
private String title;
private String author;
@Value("Hemingway")
public setAuthor(String authorName){
this.author = authorName;
}
private int price;
public SomeBean(@Value("14")int newprice){ // ! int value is set
with quotes !
this.price = newPrice;}
}
}
What is @Value used for?
This annotation is used for assigning some value to a bean field. It can be used at different levels
- constructor
- setter
- field
It is not accessible in a BeanFactoryPostProcessor and BeanPostProcessor by the time it is applied using a BeanPostProcessor.
What is Spring Expression Language (SpEL for short)?
SpEL is an expression language that allows you to query and manipulate an object graph at runtime.
@Component
public class UserService{
@Value("#{account.name}")
private String name;
}
...
@Bean
public Account account() {
return new Account("John","john@gmail.com");
}
What is the Environment abstraction in Spring?
Environment interface represents Spring abstraction for the environment. It deals with 2 aspects of a Spring application:
- profiles and
- properties from different sources (properties files, system and JVM properties etc.)
For a bean to interact with environment you can either make it EnvironmentAware or autowire the Environment.
Where can properties in the environment come from – there are many sources for properties – check the documentation if not sure. Spring Boot adds even more.
What can you reference using SpEL?
SpEL can reference beans, system variables, system properties.
@Bean
public PaymentMethod paymentMethod() {
PaymentMethod paymentMethod = new PaymentMethod();
paymentMethod.setName("Visa");
return paymentMethod;
}
...
@Value("#{paymentMethod.name}")
private String name;// Visa
What is the difference between $ and # in @Value expressions?
$ is used for placeholders from property files or system property files
# is used for SpEL
@Value("${springboot.profile}") //will populate field with value from properties file
private String profile;
@Value("#{userService.name}") // will populate field with value from otherBean bean someBeanField field
private String name;
Docker Guide
What is docker?
Getting Started
Download docker and install it on your computer
- Link to developer guide – https://docs.docker.com/ee/
- Select the docker option based on your operation system. In my case, I selected Docker for desktop mac. Then from there should be a link to download the docker executable onto your computer.
- You will have to create a docker account to download docker.
- Install docker by double-clicking on the executable your downloaded and follow instructions.
Docker commands
You are going to use the command-line interface to work with Docker.
docker images
– list out all the images in your computer
docker ps -a
– list out all the running containers on your computer
docker rmi imageId
– delete or remove an image.
docker stop containerId
– stop a running container
docker rm containerId
– delete a container
docker pull image: tag
– pull an image from a docker registry(docker hub or AWS ECR).
docker pull mysql
Run docker container automatically
Use these tags
-dit --restart unless-stopped
docker run -p outside-port:internal-port –name container-name -dit –restart unless-stopped -d image_name:image_tag
– run docker container with the port where the container will use both externally and internally, the name of the container, the image, and tag being used, and a command to make sure the container will restart if it stops.
– -d means that to run container in background and print container ID
docker run -p outside-port:internal-port --name container-name -dit --restart unless-stopped -d image_name:image_tag
docker run -p 8080:8080 --name springboot-hello-0-0-1 -dit --restart unless-stopped -d springboot-hello:0-0-1
Push up a docker image to aws docker registry
1. Login to aws ECR from your computer
aws ecr get-login-password --profile folauk110
2. Build image
docker build -t project .
3. Tag image
docker tag project:latest remote-ecr-url/project:latest
4. Push image to remote registry
docker push remote-ecr-url/project:latest
docker exec -it {container-name} sh
or
docker exec -it {container-name} sh /bin/bash
Pull redis docker image
docker pull redis
Run redis docker container
docker run --name container-redis -dit --restart unless-stopped -p 6379:6379 -d redis
Set keys and values in redis
First, ssh into the redis container.
docker exec -it container-redis sh
Second, use the redis-cli
redis-cli
127.0.0.1:6379> set docker great OK 127.0.0.1:6379> get docker "great" 127.0.0.1:6379> set name objectrocket OK 127.0.0.1:6379> get name "objectrocket"
Install Elasticsearch using docker
Pull elasticsearch docker image
Make sure to use the right version that your code and Kibana is using.
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.1.0
Run elasticsearch docker container
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch -e "discovery.type=single-node" -dit --restart unless-stopped -d docker.elastic.co/elasticsearch/elasticsearch:7.1.0Add Elasticsearch Password
-e ELASTIC_PASSWORD=MagicWord
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch -e "discovery.type=single-node" -e ELASTIC_PASSWORD=DDloadjes233j -dit --restart unless-stopped -d docker.elastic.co/elasticsearch/elasticsearch:7.1.0
Pull kibana docker image
Make sure to use the right version that your code and elasticsearch is using.
docker pull docker.elastic.co/kibana/kibana:7.1.0
Run kibana docker container
docker run --link elasticsearch:elasticsearch -dit --restart unless-stopped --name kibana -p 5601:5601 docker.elastic.co/kibana/kibana:7.1.0
Access kibana locally by going on http://localhost:5601/app/kibana
Add Elasticsearch Password
# add elasticsearch password -e ELASTICSEARCH_PASSWORD=DDloadjes233j Example docker run --link elasticsearch:elasticsearch -e ELASTICSEARCH_PASSWORD=DDloadjes233j -dit --restart unless-stopped --name kibana -p 5601:5601 docker.elastic.co/kibana/kibana:7.1.0
# pull image docker pull docker.elastic.co/logstash/logstash:7.15.0 # run container docker run -dit --restart unless-stopped --name logstash -v ~/pipeline/:/usr/share/logstash/pipeline/ docker.elastic.co/logstash/logstash:7.15.0
docker pull docker.elastic.co/logstash/logstash:7.15.0
Postgresql with docker
#pull image docker pull postgres:12.6 #run docker container docker run --name postgres --restart unless-stopped -p 5432:5432 -e POSTGRES_PASSWORD=test -v /Users/folaukaveinga/Software/postgres/data:/var/lib/postgresql/data -d postgres:12.6
Ubuntu with docker
Sometimes when you want to play or learn linux you want to have a linux OS to play with. With docker you can pull a ubuntu docker image and run it locally.
docker pull ubuntu
Run a ubuntu container
docker run -it ubuntu /bin/bash
You will be in the root folder of the ubuntu container right away after running the above command.
docker container restart [OPTIONS] CONTAINER [CONTAINER...] // -t or --time represents seconds to wait for stop before killing the container docker container restart -t 5 bee0a80b1424
View logs of a docker container
docker logs [OPTIONS] CONTAINER // Follow log output -f or --follow docker logs -f asdfwers
Terminate process(PID) command
If you ever run multiple java projects (microservices) on eclipse. Most of the time you want to start them up all at the same time and luckily eclipse has this feature. Unfortunately what Eclipse doesn’t have is a way to stop or kill all of you java projects(processes) all at the same time. This is useful when you want fresh and clean instances for all my microservices and not have any process in a stale state.
To terminate all of your projects or java processes, do this:
- Open up terminal and type in this command “killall java”
- Or open terminal within your eclipse. Open Eclipse, right-click on a project in the Package Explorer panel, hover over Show in, select terminal, and type in this command “killall java”