MySQL View
Views are virtual tables what consist of columns and rows from real tables within a database. Views don’t contain the data they display. Views are practically for read-only but some databases allow updating on views.
Here is how you create a view.
CREATE VIEW view_name AS SELECT column_name1, column_name2, ... FROM table_name WHERE condition;
You can just JOINs if needed to generate your SELECT statement. Here is how views are created.
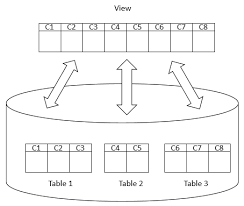
Advantages of Views
- A database view simplifies the complexity of a query. The underlying view might consist of a complex query like multiple joins and subqueries so calling a view by a simple select statement really helps reduce the code you have to write.
- A database view can have calculated columns.
- A database view can be created based off of another view.
Disadvantages of Views
- Table dependency.
- Slowness in performance if views are derived from other views.
- Views cannot have indexes. Only the underlying tables have indexes.
- If you rename a column name on the underlying table, MySQL does not throw an exception.
- Views based on complex queries such as JOINs and sub queries are not updatable. Simple select statement views are updatable.
Views and tables share the same namespace so views cannot be named the same name of an existing table.
Negotiating Salary
Few skills will impact your lifetime earnings as a software engineer more than knowing how to negotiate your salary. A single negotiation can mean tens of thousands of dollars per year — and that compounds over your career. Yet most developers accept the first offer they receive, leaving significant money on the table.
Do Your Research Before the Conversation
Walking into a negotiation without data is like deploying to production without testing. You need to know your market value before you can advocate for it. Use levels.fyi for detailed compensation breakdowns by company, level, and location. Cross-reference with Glassdoor and Blind. Look at total compensation — base salary, equity, signing bonus, and annual bonus.
For example, if you are a mid-level backend engineer interviewing at a Series B startup, check what comparable companies are paying. Having three to five data points gives you a defensible range rather than an arbitrary number.
Handle the “What Are Your Salary Expectations?” Question
This question comes up early, often from a recruiter on a screening call. The goal is to avoid anchoring yourself too low.
Deflect to their range: “I’d love to understand the full scope of the role first. Could you share the budgeted range for this position?” Many companies are now legally required to disclose this in states like California, Colorado, and New York.
Give a researched range: If pressed, say: “Based on my research, I’d expect total compensation in the range of $160K to $190K, but I’m flexible depending on the full package.” Set the bottom of your range at or above what you would actually accept.
Negotiate the Full Package, Not Just Base Salary
Base salary is only one piece. Think of compensation as a system with multiple levers. When a company says the base is firm, explore other components:
Equity: Ask for additional RSUs or a higher stock option grant. At public companies, this can be worth more than base over time.
Signing bonus: Often the easiest thing to negotiate because it is a one-time cost. If you are leaving unvested equity, frame the signing bonus as offsetting that loss.
Remote work and flexibility: The ability to work remotely has real financial value — savings on commute, relocation, and time.
PTO and professional development: Additional vacation days or learning stipends are low-cost to employers but high-value to you.
Timing Matters More Than You Think
The best time to negotiate is when the company has already decided they want you. After you receive a written offer, you have the most leverage. For performance reviews, start the conversation four to six weeks before the review cycle — give your manager time to advocate internally.
If you have a competing offer, use it respectfully: “I have received another offer at $X. I prefer your company because of the team and mission, but I want to make sure the compensation is competitive.” This is providing data, not making a threat.
Practice the Conversation
Negotiation is a skill, and you get better with practice. Before the call, rehearse your key points. Know your target number, your walk-away number, and two or three reasons why you are worth it — specific projects shipped, revenue impacted, systems improved.
Keep your tone collaborative. Phrases like “I’d like to find something that works for both of us” keep the conversation productive. The recruiter or hiring manager is often your ally — they want to close the hire.
Know When to Walk Away
Having a clear walk-away number protects you from accepting something you will resent. If a company cannot meet your minimum after good-faith negotiation, thank them and move on. Your leverage only increases as your skills and experience grow.
Key Takeaway
Salary negotiation is not about being aggressive — it is about being prepared. Do your research, understand the full compensation picture, time your ask wisely, and practice the conversation. A well-negotiated offer at the start of your career can be worth hundreds of thousands of dollars over a decade. You owe it to yourself to ask.
August 7, 2019Spring Boot Testing
When it comes to testing, you must follow Test Driven Development principles which have great practices to keep your code and logic clean. One important thing to remember about testing, You must not include logic in your tests.
Rules of Test Driven Development
- Don’t write production code without a failing test first.
- Write only enough test code to fail.
- Write minimal test code to make the failing test pass.
Integration Testing
Integration testing allows you to spin up the server, hook up all components of your application, and you make a call to the endpoint. When this happens, you able to hit the flow of logic the endpoint is meant to execute. You can mock 3rd party api calls if you want.
For example. Let’s say you have an Activity entity. You have an endpoint that exposes a search for activities. This is how it is set up.
@RunWith(SpringRunner.class)
@SpringBootTest
@DirtiesContext
public class ControllerTest {
private MockMvc mockMvc;
@Autowired
private ObjectMapper objectMapper;
@Resource
private WebApplicationContext webApplicationContext;
@Autowired
private Filter springSecurityFilterChain;
@MockBean
private UserCacheService userCacheService;
@Before
public void setUp() {
mockMvc = MockMvcBuilders.webAppContextSetup(webApplicationContext).addFilters(springSecurityFilterChain).build();
ApiTokenSession apiTokenSession = new ApiTokenSession();
apiTokenSession.setPrimary(true);
apiTokenSession.setUserUuid("adminUuid");
apiTokenSession.setUserAuthorities(Arrays.asList("USER"));
apiTokenSession.setExpiredAt(DateUtils.addDays(new Date(), 1));
apiTokenSession.setDeviceId("test_agent");
when(userCacheService.findApiSessionToken("admin_token")).thenReturn(Optional.of(sideCarApiTokenSessionAdmin));
}
@Transactional
@Test
public void searchActivity_with_includes() throws Exception {
String memberUuid = "test-member-uuid-0e045fb7-038a-49e1-b49f-b0b1cec70939";
Activity activity = new Activity();
// account,member
activity.setEntityName("member");
activity.setDescription("A profile for {{entity}} was created by {{actor}}");
activity.setEntityUuid(memberUuid);
activity.setEntityLabel("Test");
activity.setType("CREATE");
activityRepository.saveAndFlush(activity);
activity = new Activity();
// account,member,expense
activity.setEntityName("member");
activity.setDescription("{{actor}} edited member {{entity}}");
activity.setEntityUuid(memberUuid);
activity.setEntityLabel("Zen Smith ASO-T");
activity.setType("EDIT");
activityRepository.saveAndFlush(activity);
activity = new Activity();
// account,member,expense
activity.setEntityName("member");
activity.setDescription("{{actor}} deleted member {{entity}}");
activity.setEntityUuid(memberUuid);
activity.setEntityLabel("Zen Smith ASO-T");
activity.setType("DELETE");
activityRepository.saveAndFlush(activity);
// @formatter:off
RequestBuilder requestBuilder = MockMvcRequestBuilders.get("/activity/search")
.header("token", "admin_token")
.param("entityName", "member")
.param("entityUuid", memberUuid)
.param("includeTypes", "CREATE","DELETE","EDIT")
.accept(MediaType.APPLICATION_JSON_UTF8);
MvcResult result = this.mockMvc.perform(requestBuilder)
.andDo(MockMvcResultHandlers.print())
.andExpect(MockMvcResultMatchers.status().isOk()).andReturn();
String contentAsString = result.getResponse().getContentAsString();
CustomPage<Activity> activityResult = objectMapper.readValue(contentAsString, new TypeReference<CustomPage<Activity>>() {});
assertThat(activityResult).isNotNull();
List<Activity> activities = activityResult.getContent();
log.info("activities={}",activities);
assertThat(activities).isNotNull();
assertThat(activities.size()).isGreaterThan(0);
Optional<Activity> optActivity= activities.stream().filter(actvty -> actvty.getType().equals("CREATE") && actvty.getEntityUuid().equals(memberUuid)).findFirst();
assertThat(optActivity.isPresent()).isTrue();
optActivity= activities.stream().filter(actvty -> actvty.getType().equals("EDIT") && actvty.getEntityUuid().equals(memberUuid)).findFirst();
assertThat(optActivity.isPresent()).isTrue();
optActivity= activities.stream().filter(actvty -> actvty.getType().equals("DELETE") && actvty.getEntityUuid().equals(memberUuid)).findFirst();
assertThat(optActivity.isPresent()).isTrue();
// @formatter:on
}
}
Testing endpoints(just the controller web layer) with MockMvc and Mockito
- Use MockMvc to mock the endpoint call.
- Use @MockBean to mock service interface and Mockiot.when() method to mock service calls.
- Use mockMvc.perform to perform endpoint calls.
- Use and andExpect() method to verify endpoint response.
- Use Mockito.verify() method to verify service calls.
@RunWith(SpringRunner.class)
@WebMvcTest(UserController.class)
public class UserRestControllerTest {
@Autowired
private MockMvc mockMvc;
@MockBean
private UserService userService;
@Test
public void testUserSave() throws Exception {
User user = new User("kinga", "kaveinga", 21, "kinga@gmail.com");
User savedUser = new User(1, "kinga", "kaveinga", 21, "kinga@gmail.com");
/**
* thenReturn or doReturn() are used to specify a value to be returned <br/>
* upon method invocation.
*/
when(userService.save(user)).thenReturn(savedUser);
this.mockMvc.perform(post("/users").contentType(MediaType.APPLICATION_JSON).content(user.toJson()))
.andDo(print())
.andExpect(status().isOk())
.andExpect(jsonPath("$.firstName", is("kinga")))
.andExpect(jsonPath("$.id", is(1)));
verify(userService, times(1)).save(user);
verifyNoMoreInteractions(userService);
}
@Test
public void testGetUserById() throws Exception {
User mockUser = new User("folau", 21, "fkaveinga@gmail.com");
when(userService.getById(1)).thenReturn(mockUser);
this.mockMvc.perform(get("/users/1").contentType(MediaType.APPLICATION_JSON))
.andDo(print())
.andExpect(status().isOk())
.andExpect(content().contentType(MediaType.APPLICATION_JSON_UTF8))
.andExpect(jsonPath("$.firstName", is("folau")))
.andExpect(jsonPath("$.age", is(21)));
}
@Test
public void testGetAllUsers() throws Exception {
List<User> users = Arrays.asList(new User("folaulau", 21, "folaulau@gmail.com"), new User("kinga", 21, "kinga@gmail.com"));
when(userService.getAll()).thenReturn(users);
this.mockMvc.perform(get("/users").contentType(MediaType.APPLICATION_JSON))
.andDo(print())
.andExpect(status().isOk())
.andExpect(jsonPath("$[0].firstName", is("folaulau")))
.andExpect(jsonPath("$[0].age", is(21)));
}
@Test
public void testUpdateUser() throws Exception {
User user = new User("kinga", "kaveinga", 21, "kinga@gmail.com");
User savedUser = new User(1, "kinga", "kaveinga", 21, "kinga@gmail.com");
when(userService.update(user)).thenReturn(savedUser);
this.mockMvc.perform(patch("/users/update").contentType(MediaType.APPLICATION_JSON).content(user.toJson()))
.andDo(print())
.andExpect(status().isOk())
.andExpect(jsonPath("$.firstName", is("kinga")))
.andExpect(jsonPath("$.id", is(1)));
}
@Test
public void testRemoveUser() throws Exception {
long id = 1;
when(userService.remove(id)).thenReturn(true);
this.mockMvc.perform(delete("/users/" + id)).andDo(print()).andExpect(status().isOk()).andExpect(MockMvcResultMatchers.content().string("true"));
}
}
Unit Testing business logic with Mockito
- Mock objects with the when() method
- Verify that methods are called correctly within the logic you are testing. Use the verify() method.
- Use AssertThat utility methods to check expected test result.
@Test
public void testSignUp() throws Exception {
log.info("testSignUp()");
User user = ConstantUtils.generateUser();
when(userDAO.save(any(User.class))).thenReturn(user);
when(userNtcService.sendWelcomeEmail(any(User.class))).thenReturn(true);
User signedUpUser = userService.signUp(user);
InOrder inOrder = Mockito.inOrder(userDAO, userNtcService);
inOrder.verify(userDAO, times(1)).save(userCaptor.capture());
assertEquals(user, signedUpUser);
log.info("user captor email={}", userCaptor.getValue().getEmail());
assertThat(userCaptor.getValue()).isSameAs(signedUpUser);
log.info("testSignUp() - passed\n\n");
}
Testing DAO(Database Access Object)
- Use @Transactional so that database changes will be rolled back.
@RunWith(SpringRunner.class)
@DataJpaTest
public class UserRepositoryTest {
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
private UserRepository userRepository;
List<User> testUsers = new ArrayList<User>();
@Before
public void setup() {
for (int i = 0; i < 7; i++) {
User user = ConstantUtils.generateUser();
user = userRepository.saveAndFlush(user);
testUsers.add(user);
// log.info("user={}",ObjectUtils.toJson(user));
}
System.out.println("\n");
}
@Transactional
@Test
public void testSaveUser() {
User user = ConstantUtils.generateUser();
log.info("user={}", ObjectUtils.toJson(user));
User savedUser = userRepository.saveAndFlush(user);
log.info("savedUser={}", ObjectUtils.toJson(savedUser));
assertNotNull(savedUser);
log.info("savedUser==user -> {}", savedUser == user);
assertEquals(user, savedUser);
long count = userRepository.count();
log.info("count={}", count);
assertEquals(8, count);
log.info("\n\ntestSave passed\n");
}
@Transactional
@Test
public void testFindByName() throws InterruptedException, ExecutionException {
log.info("testFindByName({})", testUsers.get(0).getFirstName());
String lastName = testUsers.get(0).getLastName();
List<User> savedUsers = userRepository.findByLastName(lastName);
log.info(savedUsers.toString());
assertNotNull(savedUsers);
assertNotEquals(savedUsers.size(), 0);
log.info("\n\ntestFindByName passed\n");
}
@Transactional
@Test
public void testFindByEmail() throws InterruptedException, ExecutionException {
log.info("testFindByEmail({})", testUsers.get(0).getEmail());
User savedUser = userRepository.findByEmail(testUsers.get(0).getEmail());
assertNotNull(savedUser);
assertNotEquals(savedUser.getId().longValue(), 0);
System.out.println(savedUser.toString());
log.info("\n\ntestFindByEmail passed\n");
}
}
Spy
Spy is a wrapper which is used to override method(s) and return value(s) and ignore logic with those methods.
- Use @Spy on the service to spy or Mockito.spy() method.
- Use lenient().doReturn(returnedValue).when(service).method();
@Spy
private UserService spyUserService = new UserServiceImp();
@Test
public void test_SignUpWithPlanAndSpy() throws Exception {
log.info("test_SignUpWithPlanAndSpy()");
User user = null;
double planAmount = 200.0;
Plan plan = new Plan(1L, planAmount, user);
planAmount = 500.0;
Plan savedPlan = new Plan(1L, planAmount, user);
// This call is not actually made. Execution flow does not get within the signUpForPlan(check the log within the
// method)
lenient().doReturn(savedPlan).when(spyUserService).signUpForPlan(plan);
assertThat(savedPlan.getAmount()).isEqualTo(planAmount);
log.info("test_SignUpWithPlanAndSpy() - passed!");
}
AWS – Secrets Manager
This service has been a blessing for me in terms of hiding credentials from being exposed to hackers. This is what Secrets Manager does from the official site.
“AWS Secrets Manager helps you protect secrets needed to access your applications, services, and IT resources. The service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Users and applications retrieve secrets with a call to Secrets Manager APIs, eliminating the need to hardcode sensitive information in plain text. Secrets Manager offers secret rotation with built-in integration for Amazon RDS, Amazon Redshift, and Amazon DocumentDB. Also, the service is extensible to other types of secrets, including API keys and OAuth tokens. In addition, Secrets Manager enables you to control access to secrets using fine-grained permissions and audit secret rotation centrally for resources in the AWS Cloud, third-party services, and on-premises.”
How to implement:
Include this dependency in your pom file.
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-secretsmanager</artifactId> </dependency>
Configure an AWSSecretsManager bean or object.
@Configuration
public class DevConfig {
private Logger log = LoggerFactory.getLogger(this.getClass());
@Autowired
private AWSSecretsManagerUtils awsSecretsManagerUtils;
@Bean
public AWSCredentialsProvider amazonAWSCredentialsProvider() {
return DefaultAWSCredentialsProviderChain.getInstance();
}
@Bean
public AWSSecretsManager awsSecretsManager() {
AWSSecretsManager awsSecretsManager = AWSSecretsManagerClientBuilder
.standard()
.withCredentials(amazonAWSCredentialsProvider())
.withRegion(Regions.US_WEST_2)
.build();
return awsSecretsManager;
}
@Bean
public HikariDataSource dataSource() {
//log.debug("DB SECRET: {}", dbSecret.toJson());
DbSecret dbSecret = awsSecretsManagerUtils.getDbSecret();
log.info("Configuring dev datasource...");
Integer port = 3306;
String host = dbSecret.getHost();
String username = dbSecret.getUsername();
String password = dbSecret.getPassword();
String dbName = "springboot-course-tshirt";
String url = "jdbc:mysql://" + host + ":" + port + "/" + dbName + "?useUnicode=true&characterEncoding=utf8&useSSL=false";
HikariConfig config = new HikariConfig();
config.setJdbcUrl(url);
config.setUsername(username);
config.setPassword(password);
HikariDataSource hds = new HikariDataSource(config);
hds.setMaximumPoolSize(30);
hds.setMinimumIdle(20);
hds.setMaxLifetime(1800000);
hds.setConnectionTimeout(30000);
hds.setIdleTimeout(600000);
return hds;
}
}
Use the service by retrieving a mysql server database.
@Component
public class AWSSecretsManagerUtils {
private Logger log = LoggerFactory.getLogger(AWSSecretsManagerUtils.class);
@Value("${datasource.secret.name}")
private String dataSourceSecretName;
@Autowired
private AWSSecretsManager awsSecretsManager;
public DbSecret getDbSecret() {
return DbSecret.fromJson(getCredentials(dataSourceSecretName));
}
private String getCredentials(String secretId) {
GetSecretValueRequest getSecretValueRequest = new GetSecretValueRequest();
getSecretValueRequest.setSecretId(secretId);
GetSecretValueResult getSecretValueResponse = null;
try {
getSecretValueResponse = awsSecretsManager.getSecretValue(getSecretValueRequest);
} catch (Exception e) {
log.error("Exception, msg: ", e.getMessage());
}
if (getSecretValueResponse == null) {
return null;
}
ByteBuffer binarySecretData;
String secret;
// Decrypted secret using the associated KMS CMK
// Depending on whether the secret was a string or binary, one of these fields
// will be populated
if (getSecretValueResponse.getSecretString() != null) {
log.info("secret string");
secret = getSecretValueResponse.getSecretString();
} else {
log.info("secret binary secret data");
binarySecretData = getSecretValueResponse.getSecretBinary();
secret = binarySecretData.toString();
}
return secret;
}
}
public class DbSecret {
private String username;
private String password;
private String engine;
private String host;
private String dbInstanceIdentifier;
public DbSecret() {
this(null,null,null,null,null);
}
public DbSecret(String username, String password, String engine, String host,
String dbInstanceIdentifier) {
super();
this.username = username;
this.password = password;
this.engine = engine;
this.host = host;
this.dbInstanceIdentifier = dbInstanceIdentifier;
}
// setters and getters
public String toJson() {
try {
return ObjectUtils.getObjectMapper().writeValueAsString(this);
} catch (JsonProcessingException e) {
System.out.println("JsonProcessingException, msg: " + e.getLocalizedMessage());
return "{}";
}
}
public static DbSecret fromJson(String json) {
try {
return ObjectUtils.getObjectMapper().readValue(json, DbSecret.class);
} catch (IOException e) {
System.out.println("From Json Exception: "+e.getLocalizedMessage());
return null;
}
}
}
aws secretsmanager list-secrets --profile {profile-name}
aws secretsmanager get-secret-value --secret-id {secretName or ARN} --profile {profile-name}
React with Bootstrap
Install Bootstrap
npm install --save bootstrap
Include bootstrap.css in the index.js
import 'bootstrap/dist/css/bootstrap.css';