AWS – CloudWatch
Amazon CloudWatch is a monitoring service for engineers.. CloudWatch provides you with data and actionable insights to monitor your applications, respond to system-wide performance changes, optimize resource utilization, and get a unified view of operational health. CloudWatch collects monitoring and operational data in the form of logs, metrics, and events, providing you with a unified view of AWS resources, applications, and services that run on AWS and on-premises servers. You can use CloudWatch to detect abnormal behavior in your environments, set alarms, visualize logs and metrics side by side, take automated actions, troubleshoot issues, and discover insights to keep your applications running smoothly.


CloudWatch performs 4 actions normally, first it collects log and metric data, then monitors the applications, then Acts according to the instructions, finally analyzes the collected log and metric data for further usage.
Events
AWS CloudWatch indicates a change in your environment. You can set up rules to respond to a change like a text message sent to you when your server is down.
Alarms
CloudWatch Alarms are used to monitor only metric data. You can set alarms in order to take actions by providing a condition in the metric data of a resource. Consider the CPU Utilization of the EC2 instance can be upto 75% and an Alarm should be evoked once it crosses the range.
There are 3 alarm states:
- OK – Within Threshold.
- ALARM – Crossed Threshold.
- INSUFFICIENT_DATA – Metric not available/ Missing data (Good, Bad, Ignore, Missing).
One of these states will be considered at each millisecond of using CloudWatch metric data
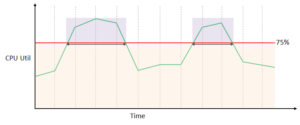
- When the CPU Utilization is 75% or lesser than 75% the Alarm state is at OK
- If it exceeds it is at ALARM you will notified
- Whenever there is no CPU Utilization data or incorrect data is produced, it will be called INSUFFIECIENT_DATA
Tail a log group from your computer. At the time of this writing, I am using aws cli v2.
- Open command line
- Get group name. Log groups are found under Cloudwatch service under Logs or run this command on the AWS CLI
-
aws logs describe-log-groups --log-group-name-prefix /ecs
The command above get all the log groups in the /ecs aws service. Here it will get all of the server log groups on ecs.
- Use the aws logs tail command
aws logs tail {log-group-name} --followExample – log api server on ecs
aws logs tail /ecs/backend-api --follow --format short
AWS – CloudFormation
August 5, 2019AWS – CodeBuild
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. With CodeBuild, you don’t need to provision, manage, and scale your own build servers. CodeBuild scales continuously and processes multiple builds concurrently, so your builds are not left waiting in a queue. You can get started quickly by using prepackaged build environments, or you can create custom build environments that use your own build tools. With CodeBuild, you are charged by the minute for the compute resources you use.
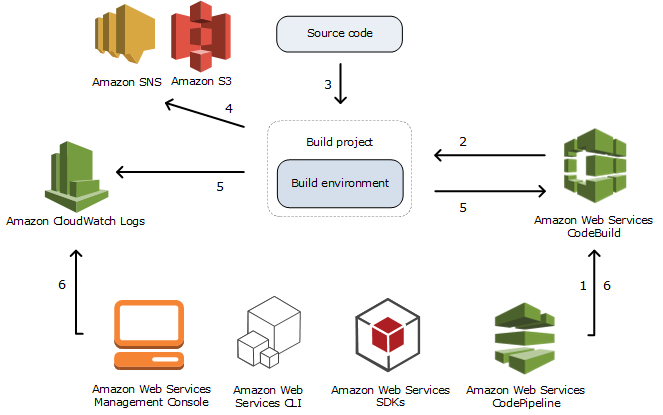
Retrieve environment variables from Secrets Manager
https://docs.aws.amazon.com/codebuild/latest/userguide/build-spec-ref.html#secrets-manager-build-spec
https://mpasierbski.com/post/aws-codebuild-secrets/
https://aws.amazon.com/about-aws/whats-new/2019/11/aws-codebuild-adds-support-for-aws-secrets-manager/
https://blog.shikisoft.com/define-environment-vars-aws-codebuild-buildspec/
AWS – CodePipeline
AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. CodePipeline automates the build, test, and deploy phases of your release process every time there is a code change, based on the release model you define. This enables you to rapidly and reliably deliver features and updates. You can easily integrate AWS CodePipeline with third-party services such as GitHub or with your own custom plugin. With AWS CodePipeline, you only pay for what you use. There are no upfront fees or long-term commitments.
Benefits
Rapid delivery – AWS CodePipeline automates your software release process, allowing you to rapidly release new features to your users. With CodePipeline, you can quickly iterate on feedback and get new features to your users faster.
Easy to integrate – AWS CodePipeline can easily be extended to adapt to your specific needs. You can use our pre-built plugins or your own custom plugins in any step of your release process. For example, you can pull your source code from GitHub, use your on-premises Jenkins build server, run load tests using a third-party service, or pass on deployment information to your custom operations dashboard.
How it works:

Set up
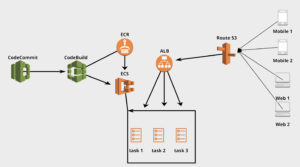
Codecommit
Code repository for you source code.
Codebuild
Codebuild will build and and deploy new code to a specified destination. Make sure that your codebuild role is able to perform actions on other aws services when your code is being built. For example you might want to push your build to S3 or ECR. In this case, you will have to add policy to your role to perform that.
buildSpec.yml file specifies how you want to build your code. It must be in the root folder of you project.
ECR
ECR stores docker images built by codebuild. These docker images have the latest code built in codebuild can can be deployed into ECS.
ECS
ECS has task definitions where you define what kind of services you might want to run.
Task Definition defines the following:
- Type of server to use(ec2 or fargate)
- VPC where the server where live
- Memory and CPU allocated to the server
- Port number of the server
- ECR image to deployed on the server
- Entrypoint endpoint that starts your server(java,-jar,-Dspring.profiles.active=dev,app.jar)
- Environment variables to pass into the server/container (spring.profiles.active=dev). You can store database credentials here which is better than storing in property files
- Cloudwatch log group for logging
Service defines the following:
- Number of servers to run
- Load balancer(ALB) to listen to
- Target Group
- Health check for servers
- Type of deployment(Rolling Update and Blue/Green)
- Security Group to use for the server
Note: Security group must enable ports where the server will listen to as well as the target group listens to. For example target group checks server health on port 80 and spring boot server listens on port 8080. Now in the security group, enable 80 and 8080 from anywhere.
ALB
Application load balancer handles requests and loads balance them to your tasks(servers). Load balancer has rules you can use for redirect or forward depending on path. This is also where you add certificate to your server. ALB can be configured to forward certain requests based on the url path to specific destination.
Route 53
Route 53 routes traffic to our ALB.
aws codepipeline list-pipelines
aws codepipeline get-pipeline-state --name MyFirstPipeline
Start the execution of a pipeline
aws codepipeline start-pipeline-execution --name MyFirstPipeline
Stop the execution of a pipeline
aws stop-pipeline-execution --pipeline-name MyFirstPipeline --pipeline-execution-id yes98sd00890
Build springboot project with Codebuild and deploy it to ECS
https://docs.aws.amazon.com/codepipeline/latest/userguide/ecs-cd-pipeline.html
Continuous Integration Best Practices 2018