AWS – Codecommit
AWS CodeCommit is a fully-managed source control service that hosts secure Git-based repositories. It makes it easy for teams to collaborate on code in a secure and highly scalable ecosystem. CodeCommit eliminates the need to operate your own source control system or worry about scaling its infrastructure. You can use CodeCommit to securely store anything from source code to binaries, and it works seamlessly with your existing Git tools.
AWS CodeCommit eliminates the need to host, maintain, back up, and scale your own source control servers. The service automatically scales to meet the growing needs of your project.
AWS CodeCommit helps you collaborate on code with teammates via pull requests, branching, and merging. You can implement workflows that include code reviews and feedback by default, and control who can make changes to specific branches.
AWS CodeCommit supports all Git commands and works with your existing Git tools. You can keep using your preferred development environment plugins, continuous integration/continuous delivery systems, and graphical clients with CodeCommit.
AWS CodeCommit automatically encrypts your files in transit and at rest. CodeCommit is integrated with AWS Identity and Access Management (IAM) allowing you to customize user-specific access to your repositories.
Set up permission for codecommit
AWS Codecommit Developer Guide
August 5, 2019AWS – Kinesis
August 5, 2019AWS – ElasticBeanstalk
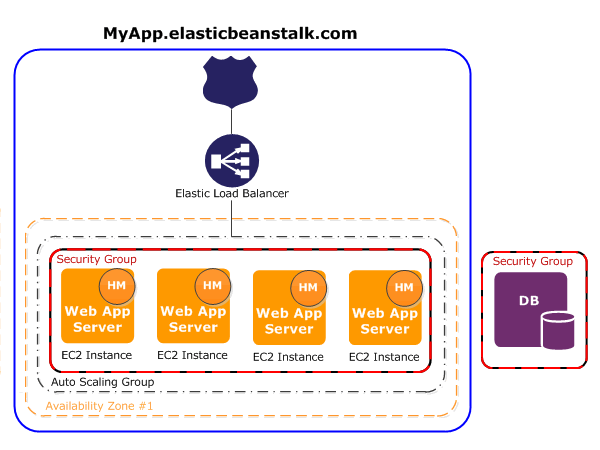
AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS.
You can simply upload your code and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring. At the same time, you retain full control over the AWS resources powering your application and can access the underlying resources at any time.
There is no additional charge for Elastic Beanstalk – you pay only for the AWS resources needed to store and run your applications.
Elastic Beanstalk automatically scales your application up and down based on your application’s specific need using easily adjustable Auto Scaling settings. For example, you can use CPU utilization metrics to trigger Auto Scaling actions. With Elastic Beanstalk, your application can handle peaks in workload or traffic while minimizing your costs.
AWS Elastic Beanstalk Developer Guide
August 5, 2019AWS – SNS
SNS is a publisher/subscriber messaging service. SNS makes easier for you to set up, operate, and send notifications from the cloud. It pushes notifications to Apple, Google, Fire OS, and Windows devices. Besides pushing notifications to mobile devices, SNS can also deliver messages to SMS text message, email (SES), SQS, or to any HTTP endpoint.
SNS notifications can trigger Lambda functions which take the notifications as payloads.
Amazon SNS isn’t currently compatible with FIFO queues but standard queues can subscribe to a topic. When you subscribe an Amazon SQS queue to an Amazon SNS topic, Amazon SNS uses HTTPS to forward messages to Amazon SQS.
SNS provides topics where subscribers can subscribe to and receive notifications. One topic can support deliveries to multiple endpoint types. Like for example if you group together iOS, Android, and SMS into a topic, when you publish to that topic all devices will get the same message.
SNS text messaging offers 100 free messages every month. Once you have gone over 100 messages then you will be charged with $0.00645 a message. This price varies from phone company to phone company.
Create a topic
@Override
public String createTopic(String name) {
final CreateTopicRequest createTopicRequest = new CreateTopicRequest(name);
CreateTopicResult createTopicResult = amazonSNS.createTopic(createTopicRequest);
return createTopicResult.getTopicArn();
}
Subscribe to a topic
@Override
public boolean subscribePhone(String topicArn, String phone) {
final SubscribeRequest subscribeRequest = new SubscribeRequest(topicArn, "sms", "+1"+phone);
amazonSNS.subscribe(subscribeRequest);
return true;
}
@Override
public boolean subscribeEmail(String topicArn, String email) {
final SubscribeRequest subscribeRequest = new SubscribeRequest(topicArn, "email", email);
amazonSNS.subscribe(subscribeRequest);
return true;
}
@Override
public boolean subscribeQueue(String topicArn, String queueUrl) {
String subscriptionArn = Topics.subscribeQueue(amazonSNS, amazonSQS, topicArn, queueUrl);
return (subscriptionArn!=null && subscriptionArn.isEmpty()==false) ? true : false;
}
Unsubscribe from a topic
@Override
public boolean unsubscribe(String subscriptionArn) {
UnsubscribeRequest unsubscribeRequest = new UnsubscribeRequest(subscriptionArn);
UnsubscribeResult unsubscribeResult = amazonSNS.unsubscribe(unsubscribeRequest);
return (unsubscribeResult!=null) ? true : false;
}
Send a message to a topic
@Override
public boolean sendMsgToTopic(String topicArn, String msg) {
final PublishRequest publishRequest = new PublishRequest(topicArn, msg);
final PublishResult publishResponse = amazonSNS.publish(publishRequest);
return (publishResponse.getMessageId()!=null) ? true : false;
}
Send an SMS message to a phone
@Override
public boolean text(String phone, String message) {
PublishResult result = amazonSNS.publish(new PublishRequest()
.withMessage(message)
.withPhoneNumber("+1"+phone)
.withMessageAttributes(new HashMap<String, MessageAttributeValue>()));
return (result.getMessageId()!=null) ? true : false;
}
August 5, 2019 AWS – SES
Amazon Simple Email Service (Amazon SES) is a cloud-based email sending service designed to help digital marketers and application developers send marketing, notification, and transactional emails. It is a reliable, cost-effective service for businesses of all sizes that use email to keep in contact with their customers.
You can use our SMTP interface or one of the AWS SDKs to integrate Amazon SES directly into your existing applications. You can also integrate the email sending capabilities of Amazon SES into the software you already use, such as ticketing systems and email clients.
Use cases:
- Send transactional emails – Keep your customers up-to-date by sending automated emails, such as purchase confirmations, shipping notifications, order status updates, and policy change notices.
- Send notification – Keep your users informed by sending timely information, including system health reports, application alerts, and workflow status updates.
- Send marketing communication – Promote your products and services by sending advertisements, newsletters, special offers, and any other type of high-quality content your customers want to see.
- Receive incoming email – Close the loop on your email program by using Amazon SES to receive email. Incoming email can be delivered automatically to an Amazon S3 bucket. You can use AWS Lambda to execute custom code when messages are received, or use Amazon SNS to deliver notifications when you receive incoming messages that contain certain keywords.

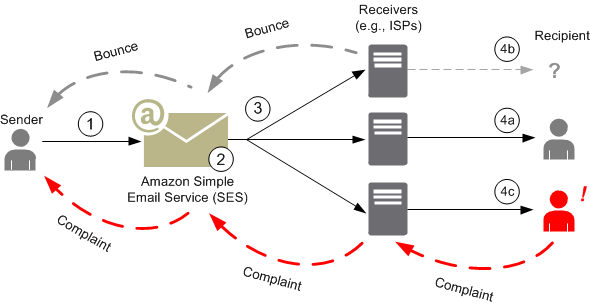
Bounce – If your recipient’s receiver (for example, an ISP) fails to deliver your message to the recipient, the receiver bounces the message back to Amazon SES. Amazon SES then notifies you of the bounced email through email or through Amazon Simple Notification Service (Amazon SNS), depending on how you have your system set up.
- Hard bounce – A persistent email delivery failure. For example, the mailbox does not exist. Amazon SES does not retry hard bounces, with the exception of DNS lookup failures. We strongly recommend that you do not make repeated delivery attempts to email addresses that hard bounce.

- Soft bounce – A temporary email delivery failure. For example, the mailbox is full, there are too many connections (also called throttling), or the connection times out. Amazon SES retries soft bounces multiple times. If the email still cannot be delivered, then Amazon SES stops retrying it.

Amazon SES notifies you of hard bounces and soft bounces that will no longer be retried. However, only hard bounces count toward your bounce rate and the bounce metric.
Bounces can also be synchronous or asynchronous. A synchronous bounce occurs while the email servers of the sender and receiver are actively communicating. An asynchronous bounce occurs when a receiver initially accepts an email message for delivery and then subsequently fails to deliver it to the recipient.
Complaint – Most email client programs provide a button labeled “Mark as Spam,” or similar, which moves the message to a spam folder, and forwards it to the ISP. Additionally, most ISPs maintain an abuse address (e.g., abuse@example.net), where users can forward unwanted email messages and request that the ISP take action to prevent them. In both of these cases, the recipient is making a complaint. If the ISP concludes that you are a spammer, and Amazon SES has a feedback loop set up with the ISP, then the ISP will send the complaint back to Amazon SES. When Amazon SES receives such a complaint, it forwards the complaint to you either by email or by using an Amazon SNS notification, depending on how you have your system set up. We recommend that you do not make repeated delivery attempts to email addresses that generate complaints.

Suppression List – The Amazon SES suppression list is a list of recipient email addresses that have recently caused a hard bounce for any Amazon SES customer. If you try to send an email through Amazon SES to an address that is on the suppression list, the call to Amazon SES succeeds, but Amazon SES treats the email as a hard bounce instead of attempting to send it. Like any hard bounce, suppression list bounces count towards your sending quota and your bounce rate. An email address can remain on the suppression list for up to 14 days. If you are sure that the email address that you’re trying to send to is valid, you can submit a suppression list removal request.
Verification – Unfortunately, it’s possible for a spammer to falsify an email header and spoof the originating email address so that it appears as though the email originated from a different source. To maintain trust between ISPs and Amazon SES, Amazon SES needs to ensure that its senders are who they say they are. You are therefore required to verify all email addresses from which you send emails through Amazon SES to protect your sending identity. You can verify email addresses by using the Amazon SES console or by using the Amazon SES API. You can also verify entire domains. If your account is still in the Amazon SES sandbox, you also need to verify all recipient addresses except for addresses provided by the Amazon SES mailbox simulator.
Sending Limits – If an ISP detects sudden, unexpected spikes in the volume or rate of your emails, the ISP might suspect you are a spammer and block your emails. Therefore, every Amazon SES account has a set of sending limits to regulate the number of email messages that you can send and the rate at which you can send them. These sending limits help you to gradually ramp up your sending activity to protect your trustworthiness with ISPs.
When a client makes a request to Amazon SES, Amazon SES constructs an email message compliant with the Internet Message Format specification. An email consists of a header, a body, and an envelop:
- Header—Contains routing instructions and information about the message. Examples are the sender’s address, the recipient’s address, the subject, and the date. The header is analogous to the information at the top of a postal letter, though it can contain many other types of information, such as the format of the message.
- Body—Contains the text of the message itself.
- Envelope—Contains the actual routing information that is communicated between the email client and the mail server during the SMTP session. This email envelope information is analogous to the information on a postal envelope. The routing information of the email envelope is usually the same as the routing information in the email header, but not always. For example, when you send a blind carbon copy (BCC), the actual recipient address (derived from the envelope) is not the same as the “To” address that is displayed in the recipient’s email client, which is derived from the header.
The following is a simple example of an email. The header is followed by a blank line and then the body of the email. The envelope isn’t shown because it is communicated between the client and the mail server during the SMTP session, rather than a part of the email itself.
Received: from abc.smtp-out.amazonses.com (123.45.67.89) by in.example.com (87.65.43.210); Fri, 17 Dec 2010 14:26:22 From: "Andrew" <andrew@example.com>; To: "Bob" <bob@example.com> Date: Fri, 17 Dec 2010 14:26:21 -0800 Subject: Hello Message-ID: <61967230-7A45-4A9D-BEC9-87CBCF2211C9@example.com> Accept-Language: en-US Content-Language: en-US Content-Type: text/plain; charset="us-ascii" Content-Transfer-Encoding: quoted-printable MIME-Version: 1.0 Hello, I hope you are having a good day. -Andrew
If you are sending an email message to a large number of recipients, then it makes sense to send it in both HTML and text. Some recipients will have HTML-enabled email clients, so that they can click embedded hyperlinks in the message. Recipients using text-based email clients will need you to include URLs that they can copy and open using a web browser.
import com.amazonaws.regions.Regions;
import com.amazonaws.services.simpleemail.AmazonSimpleEmailService;
import com.amazonaws.services.simpleemail.AmazonSimpleEmailServiceClientBuilder;
import com.amazonaws.services.simpleemail.model.Body;
import com.amazonaws.services.simpleemail.model.Content;
import com.amazonaws.services.simpleemail.model.Destination;
import com.amazonaws.services.simpleemail.model.Message;
import com.amazonaws.services.simpleemail.model.SendEmailRequest;
public class AmazonSESSample {
// Replace sender@example.com with your "From" address.
// This address must be verified with Amazon SES.
static final String FROM = "sender@example.com";
// Replace recipient@example.com with a "To" address. If your account
// is still in the sandbox, this address must be verified.
static final String TO = "recipient@example.com";
// The configuration set to use for this email. If you do not want to use a
// configuration set, comment the following variable and the
// .withConfigurationSetName(CONFIGSET); argument below.
static final String CONFIGSET = "ConfigSet";
// The subject line for the email.
static final String SUBJECT = "Amazon SES test (AWS SDK for Java)";
// The HTML body for the email.
static final String HTMLBODY = "<h1>Amazon SES test (AWS SDK for Java)</h1>"
+ "<p>This email was sent with <a href='https://aws.amazon.com/ses/'>"
+ "Amazon SES</a> using the <a href='https://aws.amazon.com/sdk-for-java/'>"
+ "AWS SDK for Java</a>";
// The email body for recipients with non-HTML email clients.
static final String TEXTBODY = "This email was sent through Amazon SES "
+ "using the AWS SDK for Java.";
public static void main(String[] args) throws IOException {
try {
AmazonSimpleEmailService client =
AmazonSimpleEmailServiceClientBuilder.standard()
// Replace US_WEST_2 with the AWS Region you're using for
// Amazon SES.
.withRegion(Regions.US_WEST_2).build();
SendEmailRequest request = new SendEmailRequest()
.withDestination(
new Destination().withToAddresses(TO))
.withMessage(new Message()
.withBody(new Body()
.withHtml(new Content()
.withCharset("UTF-8").withData(HTMLBODY))
.withText(new Content()
.withCharset("UTF-8").withData(TEXTBODY)))
.withSubject(new Content()
.withCharset("UTF-8").withData(SUBJECT)))
.withSource(FROM)
// Comment or remove the next line if you are not using a
// configuration set
.withConfigurationSetName(CONFIGSET);
client.sendEmail(request);
System.out.println("Email sent!");
} catch (Exception ex) {
System.out.println("The email was not sent. Error message: "
+ ex.getMessage());
}
}
}
August 5, 2019