Java Conditional Statements
What Are Conditional Statements?
Conditional statements are the decision-making backbone of every Java program. They allow your code to evaluate a condition and execute different blocks of code depending on whether that condition is true or false.
Think of it like real life. You wake up and check the weather:
- If it is raining, you grab an umbrella.
- Else if it is cold but dry, you wear a jacket.
- Else, you head out in a t-shirt.
Programming works the same way. Your code inspects a condition, and based on the result, it takes a specific path. Without conditional statements, every program would run the exact same instructions every time, which would make software pretty useless.
Java provides several tools for conditional logic:
if,if-else, andif-else if-elsechains- Nested
ifstatements - The
switchstatement (traditional and enhanced) - The ternary operator (
? :)
Let us walk through each one with clear examples.
Comparison Operators Recap
Before we dive in, remember that conditions are built using comparison operators. These operators compare two values and return a boolean result (true or false).
| Operator | Meaning | Example | Result |
|---|---|---|---|
== |
Equal to | 5 == 5 |
true |
!= |
Not equal to | 5 != 3 |
true |
> |
Greater than | 10 > 7 |
true |
< |
Less than | 3 < 8 |
true |
>= |
Greater than or equal to | 5 >= 5 |
true |
<= |
Less than or equal to | 4 <= 9 |
true |
For a deeper look at all Java operators, check out the Java Operators tutorial.
The if Statement
The if statement is the simplest form of conditional logic. It executes a block of code only when the condition evaluates to true. If the condition is false, the block is skipped entirely and execution continues after it.
Syntax
if (condition) {
// code executes only when condition is true
}
Always use curly braces {}, even for single-line bodies. It prevents bugs when you later add more lines and improves readability.
Example: Checking if a Number is Positive
int temperature = 35;
if (temperature > 30) {
System.out.println("It's a hot day! Stay hydrated.");
}
System.out.println("Have a great day!");
// Output:
// It's a hot day! Stay hydrated.
// Have a great day!
Here, temperature > 30 evaluates to true, so the message about staying hydrated is printed. The last line always prints regardless of the condition because it is outside the if block.
When to use: Use a standalone if when you only need to do something extra under a certain condition, and there is nothing special to do otherwise.
The if-else Statement
The if-else statement adds an alternative path. If the condition is true, the first block runs. If it is false, the else block runs instead. Exactly one of the two blocks will always execute.
Syntax
if (condition) {
// runs when condition is true
} else {
// runs when condition is false
}
Example: Checking Voting Eligibility
int age = 16;
if (age >= 18) {
System.out.println("You are eligible to vote.");
} else {
System.out.println("You are not eligible to vote yet.");
int yearsLeft = 18 - age;
System.out.println("You can vote in " + yearsLeft + " year(s).");
}
// Output:
// You are not eligible to vote yet.
// You can vote in 2 year(s).
Since age is 16, the condition age >= 18 is false, so Java skips the if block and executes the else block.
The if-else if-else Chain
When you have more than two possible outcomes, chain multiple conditions together using else if. Java evaluates each condition from top to bottom and executes the first block whose condition is true. If none match, the else block runs as a catch-all.
Syntax
if (condition1) {
// runs if condition1 is true
} else if (condition2) {
// runs if condition1 is false AND condition2 is true
} else if (condition3) {
// runs if condition1 and condition2 are false AND condition3 is true
} else {
// runs if none of the above conditions are true
}
Example 1: Grade Calculator
int score = 82;
char grade;
if (score >= 90) {
grade = 'A';
} else if (score >= 80) {
grade = 'B';
} else if (score >= 70) {
grade = 'C';
} else if (score >= 60) {
grade = 'D';
} else {
grade = 'F';
}
System.out.println("Score: " + score + " -> Grade: " + grade);
// Output:
// Score: 82 -> Grade: B
Key insight: The order of conditions matters. A score of 82 satisfies both score >= 70 and score >= 80, but because Java evaluates top to bottom and stops at the first match, it correctly assigns a 'B'. If you reversed the order and checked score >= 60 first, every passing score would get a 'D'.
Example 2: Age Group Classifier
int age = 30;
String ageGroup;
if (age < 0) {
ageGroup = "Invalid age";
} else if (age < 13) {
ageGroup = "Child";
} else if (age < 18) {
ageGroup = "Teenager";
} else if (age < 30) {
ageGroup = "Young Adult";
} else if (age < 60) {
ageGroup = "Adult";
} else {
ageGroup = "Senior";
}
System.out.println("Age: " + age + " -> Group: " + ageGroup);
// Output:
// Age: 30 -> Group: Adult
Nested if Statements
You can place an if statement inside another if statement. This is useful when a second decision only makes sense after a first condition is confirmed.
Example: Login Validation
String username = "admin";
String password = "secret123";
boolean isAccountLocked = false;
if (username.equals("admin")) {
if (password.equals("secret123")) {
if (!isAccountLocked) {
System.out.println("Login successful! Welcome, admin.");
} else {
System.out.println("Account is locked. Contact support.");
}
} else {
System.out.println("Incorrect password.");
}
} else {
System.out.println("User not found.");
}
// Output:
// Login successful! Welcome, admin.
A word of caution: Deeply nested if statements (3+ levels deep) become hard to read and maintain. When you find yourself nesting deeply, consider refactoring with guard clauses (covered in best practices below) or extracting logic into separate methods.
Logical Operators in Conditions
Logical operators let you combine multiple conditions into a single expression. This is often a cleaner alternative to nesting.
| Operator | Name | Description | Example |
|---|---|---|---|
&& |
AND | True if both conditions are true | age > 18 && hasID |
|| |
OR | True if at least one condition is true | isVIP || hasTicket |
! |
NOT | Reverses a boolean value | !isBlocked |
Example: Combining Conditions
int age = 25;
boolean hasLicense = true;
boolean isInsured = true;
boolean isSuspended = false;
// AND (&&) - all conditions must be true
if (age >= 16 && hasLicense && isInsured) {
System.out.println("You can drive.");
}
// OR (||) - at least one must be true
boolean isWeekend = false;
boolean isHoliday = true;
if (isWeekend || isHoliday) {
System.out.println("No work today!");
}
// NOT (!) - reverses the boolean
if (!isSuspended) {
System.out.println("Your account is active.");
}
// Combining AND, OR, NOT
if ((age >= 18 && hasLicense) && !isSuspended) {
System.out.println("Full driving privileges granted.");
}
// Output:
// You can drive.
// No work today!
// Your account is active.
// Full driving privileges granted.
Short-circuit evaluation: Java uses short-circuit evaluation with && and ||. With &&, if the first condition is false, Java does not evaluate the second condition because the overall result is already false. With ||, if the first condition is true, the second is skipped. This matters when the second condition has side effects or could throw an exception.
// Short-circuit prevents NullPointerException
String name = null;
// Safe: if name is null, the second condition is never evaluated
if (name != null && name.length() > 5) {
System.out.println("Long name: " + name);
} else {
System.out.println("Name is null or too short.");
}
// Output:
// Name is null or too short.
Traditional Switch Statement
The switch statement evaluates a single expression and matches it against a list of possible values (case labels). It is often a cleaner alternative to a long if-else if chain when you are comparing one variable against many known values.
Syntax
switch (expression) {
case VALUE1:
// code for VALUE1
break;
case VALUE2:
// code for VALUE2
break;
case VALUE3:
// code for VALUE3
break;
default:
// code if no case matches
break;
}
Important details:
- The syntax is
case VALUE:(value first, then colon). A common mistake is writingcase:VALUEwith the colon before the value, which is a syntax error. - The
breakkeyword exits the switch block. Without it, execution “falls through” into the next case. - The
defaultcase is optional but recommended. It handles any value not matched by acase.
Supported Types
The switch expression supports: byte, short, int, char, String (Java 7+), and enum types. It does not support long, float, double, or boolean.
Example: Day of the Week
String day = "WEDNESDAY";
switch (day) {
case "MONDAY":
System.out.println("Start of the work week.");
break;
case "TUESDAY":
case "WEDNESDAY":
case "THURSDAY":
System.out.println("Midweek - keep going!");
break;
case "FRIDAY":
System.out.println("TGIF! Almost the weekend.");
break;
case "SATURDAY":
case "SUNDAY":
System.out.println("Weekend - time to relax!");
break;
default:
System.out.println("Invalid day: " + day);
break;
}
// Output:
// Midweek - keep going!
Notice how TUESDAY, WEDNESDAY, and THURSDAY share the same code block. Since there is no break after case "TUESDAY":, execution falls through to the next case. This is intentional fall-through and is a legitimate use of the behavior.
Example: Using switch with int
int month = 3;
String monthName;
switch (month) {
case 1:
monthName = "January";
break;
case 2:
monthName = "February";
break;
case 3:
monthName = "March";
break;
case 4:
monthName = "April";
break;
case 5:
monthName = "May";
break;
case 6:
monthName = "June";
break;
case 7:
monthName = "July";
break;
case 8:
monthName = "August";
break;
case 9:
monthName = "September";
break;
case 10:
monthName = "October";
break;
case 11:
monthName = "November";
break;
case 12:
monthName = "December";
break;
default:
monthName = "Invalid month";
break;
}
System.out.println("Month " + month + " is " + monthName);
// Output:
// Month 3 is March
Fall-Through Behavior Explained
Fall-through is one of the most common sources of bugs in switch statements. If you forget a break, Java continues executing the next case’s code regardless of whether it matches.
// BUG: Missing break statements cause fall-through
int priority = 1;
switch (priority) {
case 1:
System.out.println("Critical");
// missing break! Falls through to case 2
case 2:
System.out.println("High");
// missing break! Falls through to case 3
case 3:
System.out.println("Medium");
break;
default:
System.out.println("Low");
break;
}
// Output (unintended!):
// Critical
// High
// Medium
Even though priority is 1, all three messages print because execution falls through from case 1 to case 2 to case 3 before hitting a break. This is why using break consistently is so important. The enhanced switch expression (covered next) eliminates this problem entirely.
Example: Using switch with enum
enum Season { SPRING, SUMMER, FALL, WINTER }
Season current = Season.SUMMER;
switch (current) {
case SPRING:
System.out.println("Flowers are blooming.");
break;
case SUMMER:
System.out.println("Time for the beach!");
break;
case FALL:
System.out.println("Leaves are changing color.");
break;
case WINTER:
System.out.println("Bundle up, it's cold.");
break;
}
// Output:
// Time for the beach!
Note: When using switch with enums, you do not prefix the enum name in the case labels. Write case SUMMER:, not case Season.SUMMER:.
Enhanced Switch Expression (Java 14+)
Java 14 introduced the switch expression as a standard feature (previewed in Java 12 and 13). It modernizes the switch with a cleaner syntax that eliminates fall-through bugs and allows the switch to return a value.
Key Differences from Traditional Switch
| Feature | Traditional Switch | Enhanced Switch Expression |
|---|---|---|
| Syntax | case VALUE: |
case VALUE -> |
| Fall-through | Yes (requires break) |
No fall-through |
| Multiple labels | Stacked cases | Comma-separated: case A, B, C -> |
| Returns a value | No | Yes |
break required |
Yes | No |
Arrow Syntax and Returning Values
import java.time.DayOfWeek;
DayOfWeek day = DayOfWeek.WEDNESDAY;
// Switch expression returns a value
String dayType = switch (day) {
case MONDAY, TUESDAY -> "Start of week";
case WEDNESDAY, THURSDAY -> "Midweek";
case FRIDAY -> "End of work week";
case SATURDAY, SUNDAY -> "Weekend";
};
System.out.println(day + " is: " + dayType);
// Output:
// WEDNESDAY is: Midweek
Notice:
- The arrow (
->) replaces the colon (:) and thebreakkeyword. - Multiple case labels are separated by commas instead of being stacked.
- The entire switch is an expression that returns a value, assigned to
dayType. - No fall-through is possible.
Using yield for Multi-Line Case Blocks
When a case needs to execute multiple lines of code before returning a value, wrap the code in a block {} and use the yield keyword to return the value.
int score = 85;
String result = switch (score / 10) {
case 10, 9 -> "Excellent";
case 8 -> {
System.out.println("Processing grade B...");
String detail = "Good job! You scored " + score;
System.out.println(detail);
yield "Good"; // 'yield' returns the value from this block
}
case 7 -> "Satisfactory";
case 6 -> "Needs Improvement";
default -> {
System.out.println("Score below 60.");
yield "Failing";
}
};
System.out.println("Result: " + result);
// Output:
// Processing grade B...
// Good job! You scored 85
// Result: Good
The yield keyword works like return but specifically for switch expression blocks. You cannot use return inside a switch expression — return would exit the enclosing method, not the switch.
Enhanced Switch as a Statement (No Return Value)
You can also use the arrow syntax without returning a value. This gives you the cleaner syntax and no fall-through, even when you do not need to assign a result.
String command = "START";
// Arrow syntax used as a statement (no value returned)
switch (command) {
case "START" -> System.out.println("Starting the engine...");
case "STOP" -> System.out.println("Stopping the engine...");
case "RESTART" -> {
System.out.println("Stopping...");
System.out.println("Starting...");
System.out.println("Engine restarted.");
}
default -> System.out.println("Unknown command: " + command);
}
// Output:
// Starting the engine...
Pattern Matching with Switch (Java 21+)
Java 21 introduced pattern matching for switch as a standard feature. This allows the switch to match against types (not just values), making it extremely powerful for handling polymorphic objects.
// Java 21+ Pattern Matching with switch
Object obj = "Hello, World!";
String description = switch (obj) {
case Integer i when i > 0 -> "Positive integer: " + i;
case Integer i -> "Non-positive integer: " + i;
case String s when s.isEmpty() -> "Empty string";
case String s -> "String of length " + s.length() + ": " + s;
case Double d -> "Double value: " + d;
case null -> "It's null!";
default -> "Unknown type: " + obj.getClass().getSimpleName();
};
System.out.println(description);
// Output:
// String of length 13: Hello, World!
Pattern matching with when guards lets you combine type checking and conditional logic in a single, readable expression. This replaces chains of instanceof checks followed by casting that were common in older Java code.
Ternary Operator (? :)
The ternary operator is a compact shorthand for a simple if-else that assigns a value. It is the only operator in Java that takes three operands.
Syntax
variable = (condition) ? valueIfTrue : valueIfFalse;
Examples
int age = 20;
// Ternary operator
String status = (age >= 18) ? "Adult" : "Minor";
System.out.println(status);
// Output: Adult
// Equivalent if-else
String status2;
if (age >= 18) {
status2 = "Adult";
} else {
status2 = "Minor";
}
// Ternary in method arguments
int a = 15, b = 22;
System.out.println("Max value: " + ((a > b) ? a : b));
// Output: Max value: 22
// Nested ternary (use sparingly - can hurt readability)
int score = 85;
String grade = (score >= 90) ? "A"
: (score >= 80) ? "B"
: (score >= 70) ? "C"
: (score >= 60) ? "D"
: "F";
System.out.println("Grade: " + grade);
// Output: Grade: B
Best practice: Use the ternary operator for simple, single-condition assignments. Avoid nesting ternary operators deeply — if the logic has more than two branches, use if-else if-else or a switch instead.
Best Practices
1. When to Use if-else vs switch
| Scenario | Use | Why |
|---|---|---|
| Comparing a single variable against many known values | switch |
Cleaner, more readable, better performance |
Range-based conditions (>, <, >=) |
if-else |
Switch cannot do range comparisons |
| Complex boolean expressions | if-else |
Switch evaluates a single expression |
| Two outcomes (true/false) | if-else or ternary |
Switch is overkill for binary decisions |
| Type checking (Java 21+) | switch with pattern matching |
Cleaner than instanceof chains |
2. Avoid Deep Nesting
Deeply nested conditions are hard to read, test, and maintain. Aim for a maximum nesting depth of 2 levels.
// BAD: Deeply nested - hard to read
public void processOrder(Order order) {
if (order != null) {
if (order.isValid()) {
if (order.hasStock()) {
if (order.paymentApproved()) {
// finally do something useful
ship(order);
} else {
System.out.println("Payment failed.");
}
} else {
System.out.println("Out of stock.");
}
} else {
System.out.println("Invalid order.");
}
} else {
System.out.println("Order is null.");
}
}
// GOOD: Guard clauses - flat and readable
public void processOrder(Order order) {
if (order == null) {
System.out.println("Order is null.");
return;
}
if (!order.isValid()) {
System.out.println("Invalid order.");
return;
}
if (!order.hasStock()) {
System.out.println("Out of stock.");
return;
}
if (!order.paymentApproved()) {
System.out.println("Payment failed.");
return;
}
// Happy path - no nesting!
ship(order);
}
3. The Guard Clause Pattern
A guard clause is an early return (or throw) that handles edge cases and invalid states at the top of a method. This keeps the main logic un-indented and easy to follow. As shown above, instead of wrapping everything in nested if blocks, check for failure conditions first and exit early.
4. Always Use Braces
Even for single-line if statements, always use curly braces. It prevents subtle bugs when you later add a second line to the block.
// BAD: No braces - easy to introduce bugs
if (isLoggedIn)
System.out.println("Welcome!");
loadDashboard(); // This ALWAYS runs! It is NOT inside the if.
// GOOD: Always use braces
if (isLoggedIn) {
System.out.println("Welcome!");
loadDashboard(); // Only runs when isLoggedIn is true
}
5. Additional Tips
- Put the most likely condition first in an
if-else ifchain for readability and (slight) performance gains. - Use
switchexpressions (Java 14+) over traditional switch whenever possible. They are safer (no fall-through) and more concise. - Compare Strings with
.equals(), never with==. The==operator compares object references, not the actual string content. - Prefer positive conditions for readability.
if (isValid)reads better thanif (!isInvalid). - Extract complex conditions into well-named boolean variables to self-document your code.
// Hard to read
if (user.getAge() >= 18 && user.hasVerifiedEmail() && !user.isBanned() && user.getSubscription().isActive()) {
grantAccess(user);
}
// Self-documenting with named booleans
boolean isAdult = user.getAge() >= 18;
boolean isVerified = user.hasVerifiedEmail();
boolean isInGoodStanding = !user.isBanned();
boolean hasActiveSubscription = user.getSubscription().isActive();
if (isAdult && isVerified && isInGoodStanding && hasActiveSubscription) {
grantAccess(user);
}
Complete Runnable Example
Here is a complete program that demonstrates all the conditional statement types covered in this tutorial. You can copy this into your IDE and run it.
public class ConditionalStatements {
public static void main(String[] args) {
// --- 1. if statement ---
int temperature = 35;
if (temperature > 30) {
System.out.println("1. It's hot outside!");
}
// --- 2. if-else ---
int age = 16;
if (age >= 18) {
System.out.println("2. You can vote.");
} else {
System.out.println("2. You cannot vote yet. " + (18 - age) + " years to go.");
}
// --- 3. if-else if-else ---
int score = 82;
String grade;
if (score >= 90) {
grade = "A";
} else if (score >= 80) {
grade = "B";
} else if (score >= 70) {
grade = "C";
} else if (score >= 60) {
grade = "D";
} else {
grade = "F";
}
System.out.println("3. Score " + score + " = Grade " + grade);
// --- 4. Logical operators ---
boolean hasLicense = true;
boolean isInsured = true;
if (age >= 16 && hasLicense && isInsured) {
System.out.println("4. You can drive.");
}
// --- 5. Traditional switch ---
String day = "FRIDAY";
switch (day) {
case "MONDAY":
case "TUESDAY":
case "WEDNESDAY":
case "THURSDAY":
System.out.println("5. Weekday");
break;
case "FRIDAY":
System.out.println("5. TGIF!");
break;
case "SATURDAY":
case "SUNDAY":
System.out.println("5. Weekend!");
break;
default:
System.out.println("5. Invalid day");
break;
}
// --- 6. Enhanced switch expression (Java 14+) ---
String dayType = switch (day) {
case "MONDAY", "TUESDAY", "WEDNESDAY", "THURSDAY" -> "Weekday";
case "FRIDAY" -> "Fri-yay!";
case "SATURDAY", "SUNDAY" -> "Weekend";
default -> "Unknown";
};
System.out.println("6. " + day + " is: " + dayType);
// --- 7. Ternary operator ---
String status = (age >= 18) ? "Adult" : "Minor";
System.out.println("7. Age " + age + " = " + status);
}
}
// Output:
// 1. It's hot outside!
// 2. You cannot vote yet. 2 years to go.
// 3. Score 82 = Grade B
// 4. You can drive.
// 5. TGIF!
// 6. FRIDAY is: Fri-yay!
// 7. Age 16 = Minor
Summary
| Statement | Use When |
|---|---|
if |
You need to do something only when a condition is true |
if-else |
You have two possible paths (true or false) |
if-else if-else |
You have multiple conditions to check in sequence |
Nested if |
A condition depends on another condition being true (use sparingly) |
Traditional switch |
Comparing one variable against many fixed values (pre-Java 14) |
Enhanced switch |
Same as above but cleaner, no fall-through, can return values (Java 14+) |
Pattern matching switch |
Matching against types and complex patterns (Java 21+) |
Ternary ? : |
Simple inline conditional assignment |
Conditional statements are fundamental to every Java program. Master these patterns and you will be able to express any decision-making logic cleanly and correctly.
Python Advanced – Machine Learning
Introduction to Machine Learning
Machine learning is a branch of artificial intelligence where systems learn patterns from data and make decisions without being explicitly programmed for every scenario. Instead of writing rules by hand, you feed data into an algorithm, and it figures out the rules on its own. That is the core idea.
If you have spent years writing deterministic code — if X then Y — machine learning flips that. You give it examples of X and Y, and it learns the mapping between them.
Types of Machine Learning
There are three main categories:
- Supervised Learning — You have labeled data. The model learns from input-output pairs. Think: predicting house prices given square footage, or classifying emails as spam or not spam. You know the answer during training, and the model learns to replicate it.
- Unsupervised Learning — No labels. The model finds hidden structure in data on its own. Think: customer segmentation, anomaly detection, or grouping similar documents together.
- Reinforcement Learning — The model learns by interacting with an environment and receiving rewards or penalties. Think: game-playing AI, robotics, self-driving cars. We will not cover this in depth here — it is its own world.
This tutorial focuses on supervised and unsupervised learning because that is where 90% of practical ML work happens in industry.
Why Python?
Python dominates machine learning for good reasons:
- Ecosystem — scikit-learn, TensorFlow, PyTorch, pandas, numpy. The library support is unmatched.
- Readability — ML code needs to be understood by data scientists, engineers, and sometimes business stakeholders. Python reads like pseudocode.
- Community — Every ML paper, tutorial, and Stack Overflow answer has a Python example. When you hit a wall, help is everywhere.
- Prototyping speed — You can go from idea to working model in hours, not days.
If you are coming from Java or C++, Python will feel loose. Embrace it. For ML work, the speed of iteration matters more than type safety.
Essential Libraries
Before writing any ML code, you need to know four libraries. These are your foundation:
NumPy
The numerical computing backbone of Python. It provides n-dimensional arrays and fast mathematical operations. Every ML library is built on top of NumPy under the hood.
pandas
Data manipulation and analysis. If your data lives in a CSV, database, or Excel file, pandas is how you load it, clean it, and transform it. Think of it as a programmable spreadsheet with serious power.
scikit-learn
The Swiss Army knife of classical machine learning. It provides consistent APIs for dozens of algorithms — regression, classification, clustering, dimensionality reduction, preprocessing, and model evaluation. If you are not doing deep learning, scikit-learn is probably all you need.
matplotlib
Data visualization. You need to see your data before modeling it, and you need to visualize your results after. matplotlib is the standard plotting library, and while it is not the prettiest out of the box, it gets the job done.
Installation
Install all four libraries in one command:
pip install scikit-learn pandas numpy matplotlib
If you are using a virtual environment (and you should be), activate it first:
python -m venv ml-env source ml-env/bin/activate # macOS/Linux ml-env\Scripts\activate # Windows pip install scikit-learn pandas numpy matplotlib
Verify the installation:
import sklearn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print(f"scikit-learn: {sklearn.__version__}")
print(f"pandas: {pd.__version__}")
print(f"numpy: {np.__version__}")
print(f"matplotlib: {plt.matplotlib.__version__}")
If that runs without errors, you are good to go.
The Machine Learning Workflow
Every ML project follows roughly the same pipeline. Memorize this — it will save you from chaos:
- Data Collection — Gather your data from files, APIs, databases, web scraping, or built-in datasets.
- Data Preprocessing — Clean the data. Handle missing values, remove duplicates, fix data types. This step takes 60-80% of your time. Seriously.
- Feature Selection/Engineering — Decide which columns (features) matter. Create new features from existing ones. Drop irrelevant noise.
- Train/Test Split — Split your data so you train on one portion and evaluate on another. Never evaluate on training data.
- Model Training — Pick an algorithm, fit it to your training data.
- Evaluation — Measure how well the model performs on unseen test data.
- Tuning — Adjust hyperparameters, try different algorithms, engineer better features.
- Deployment — Ship the model into production (API, batch job, embedded system).
Do not skip steps. Do not jump straight to model training. The quality of your data determines the quality of your model. Garbage in, garbage out.
Data Preprocessing with pandas
Preprocessing is where you will spend most of your time. Let us walk through the essentials.
Loading Data from CSV
import pandas as pd
# Load a CSV file into a DataFrame
df = pd.read_csv("housing_data.csv")
# Quick look at the data
print(df.head()) # First 5 rows
print(df.shape) # (rows, columns)
print(df.info()) # Column types, non-null counts
print(df.describe()) # Statistical summary
Always start with head(), info(), and describe(). They tell you what you are working with before you write a single line of ML code.
Handling Missing Values
Real-world data is messy. Missing values are everywhere. You have a few options:
import pandas as pd import numpy as np # Check for missing values print(df.isnull().sum()) # Option 1: Drop rows with any missing values df_cleaned = df.dropna() # Option 2: Drop rows where specific columns are missing df_cleaned = df.dropna(subset=["price", "bedrooms"]) # Option 3: Fill missing values with a constant df["bedrooms"] = df["bedrooms"].fillna(0) # Option 4: Fill with the mean (common for numerical columns) df["price"] = df["price"].fillna(df["price"].mean()) # Option 5: Fill with the median (better for skewed data) df["price"] = df["price"].fillna(df["price"].median()) # Option 6: Forward fill (use previous row's value) df["temperature"] = df["temperature"].fillna(method="ffill")
Which strategy to use depends on your data. If only 1-2% of rows have missing values, dropping them is fine. If 30% of a column is missing, you need to decide whether to fill it or drop the column entirely.
Feature Scaling
Many ML algorithms are sensitive to the scale of features. If one feature ranges from 0-1 and another from 0-1,000,000, the larger feature will dominate the model. Scaling fixes this.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import numpy as np
# Sample data
data = [[1500, 3, 10],
[2000, 4, 5],
[1200, 2, 15],
[1800, 3, 8]]
# StandardScaler: mean=0, std=1 (most common)
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print("StandardScaler result:")
print(scaled_data)
# MinMaxScaler: scales to [0, 1] range
min_max_scaler = MinMaxScaler()
normalized_data = min_max_scaler.fit_transform(data)
print("\nMinMaxScaler result:")
print(normalized_data)
StandardScaler centers data around zero with unit variance. Use it when your algorithm assumes normally distributed data (e.g., SVM, logistic regression). MinMaxScaler squeezes everything into [0, 1]. Use it when you need bounded values or your data is not normally distributed.
Encoding Categorical Variables
ML algorithms work with numbers, not strings. If you have a column like “color” with values [“red”, “blue”, “green”], you need to convert it to numbers.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import pandas as pd
import numpy as np
# Sample data
df = pd.DataFrame({
"color": ["red", "blue", "green", "red", "blue"],
"size": ["S", "M", "L", "M", "S"],
"price": [10, 20, 30, 15, 25]
})
# LabelEncoder: converts categories to integers
# Use for ordinal data (S < M < L) or target variables
label_encoder = LabelEncoder()
df["size_encoded"] = label_encoder.fit_transform(df["size"])
print(df)
# L=0, M=1, S=2
# OneHotEncoder: creates binary columns for each category
# Use for nominal data (red, blue, green have no order)
df_encoded = pd.get_dummies(df, columns=["color"], dtype=int)
print(df_encoded)
Rule of thumb: Use LabelEncoder when there is a natural order (small, medium, large). Use OneHotEncoding (or pd.get_dummies) when there is no order (red, blue, green). Using LabelEncoder on nominal data tricks the model into thinking blue > red, which is nonsense.
Supervised Learning
Supervised learning is the workhorse of ML. You have inputs (features) and outputs (labels), and the model learns the relationship between them.
Train/Test Split
Before training any model, split your data. This is non-negotiable.
from sklearn.model_selection import train_test_split
# X = features, y = target variable
# test_size=0.2 means 80% training, 20% testing
# random_state ensures reproducibility
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
Why 80/20? It is a reasonable default. With very large datasets, you can use 90/10. With small datasets, consider cross-validation instead (more on that later).
Linear Regression — Predicting House Prices
Linear regression finds the best straight line through your data. It is the simplest regression algorithm and a great starting point.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Create sample housing data
np.random.seed(42)
n_samples = 200
square_feet = np.random.randint(800, 3500, n_samples)
bedrooms = np.random.randint(1, 6, n_samples)
age = np.random.randint(0, 50, n_samples)
# Price formula with some noise
price = (square_feet * 150) + (bedrooms * 20000) - (age * 1000) + np.random.normal(0, 15000, n_samples)
df = pd.DataFrame({
"square_feet": square_feet,
"bedrooms": bedrooms,
"age": age,
"price": price
})
# Features and target
X = df[["square_feet", "bedrooms", "age"]]
y = df["price"]
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"RMSE: ${rmse:,.2f}")
print(f"R² Score: {r2:.4f}")
# See what the model learned
print(f"\nCoefficients:")
for feature, coef in zip(X.columns, model.coef_):
print(f" {feature}: {coef:.2f}")
print(f" Intercept: {model.intercept_:.2f}")
# Predict a new house
new_house = [[2000, 3, 10]] # 2000 sqft, 3 bed, 10 years old
predicted_price = model.predict(new_house)
print(f"\nPredicted price for new house: ${predicted_price[0]:,.2f}")
The R² score tells you how much variance the model explains. 1.0 is perfect, 0.0 means the model is no better than guessing the mean. In practice, anything above 0.7 is decent for a first model.
Logistic Regression — Classifying Iris Flowers
Despite its name, logistic regression is a classification algorithm. It predicts which category something belongs to. Let us use the famous Iris dataset — it is built into scikit-learn.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
# Load the Iris dataset
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
print("Features:", list(iris.feature_names))
print("Classes:", list(iris.target_names))
print(f"Samples: {len(X)}")
print(X.head())
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train logistic regression
model = LogisticRegression(max_iter=200, random_state=42)
model.fit(X_train, y_train)
# Predict
y_pred = model.predict(X_test)
# Evaluate
accuracy = accuracy_score(y_test, y_pred)
print(f"\nAccuracy: {accuracy:.2%}")
# Detailed classification report
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
The Iris dataset has 150 samples with 4 features (sepal length, sepal width, petal length, petal width) and 3 classes (setosa, versicolor, virginica). With logistic regression, you should get around 97-100% accuracy. It is a clean dataset — real-world data will not be this kind to you.
Decision Trees
Decision trees are intuitive — they split data based on feature thresholds, creating a tree of if-else rules. They work for both classification and regression.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load and split data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=42
)
# Train decision tree
tree_model = DecisionTreeClassifier(
max_depth=3, # Limit depth to prevent overfitting
random_state=42
)
tree_model.fit(X_train, y_train)
# Evaluate
y_pred = tree_model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2%}")
# Feature importance — which features matter most?
for name, importance in zip(iris.feature_names, tree_model.feature_importances_):
print(f" {name}: {importance:.4f}")
Decision trees are easy to interpret but prone to overfitting. Always set max_depth to limit complexity. In practice, ensemble methods like Random Forest (many decision trees voting together) outperform a single tree.
Model Evaluation
A model is only as good as its evaluation. Here are the metrics you need to know:
For Classification
from sklearn.metrics import (
accuracy_score, confusion_matrix,
classification_report, f1_score
)
# accuracy_score: percentage of correct predictions
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2%}")
# confusion_matrix: shows true positives, false positives, etc.
cm = confusion_matrix(y_test, y_pred)
print(f"\nConfusion Matrix:\n{cm}")
# classification_report: precision, recall, f1-score per class
report = classification_report(y_test, y_pred, target_names=iris.target_names)
print(f"\nClassification Report:\n{report}")
# f1_score: harmonic mean of precision and recall
# Use 'weighted' for multi-class problems
f1 = f1_score(y_test, y_pred, average="weighted")
print(f"F1 Score: {f1:.4f}")
Accuracy is misleading when classes are imbalanced. If 95% of emails are not spam, a model that always predicts "not spam" gets 95% accuracy but is useless. That is why you need precision, recall, and F1-score.
- Precision — Of everything the model predicted as positive, how many were actually positive?
- Recall — Of all actual positives, how many did the model catch?
- F1-Score — The balance between precision and recall. Use this as your primary metric for imbalanced datasets.
For Regression
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import numpy as np
# Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print(f"MSE: {mse:.2f}")
# Root Mean Squared Error (RMSE) — same units as target
rmse = np.sqrt(mse)
print(f"RMSE: {rmse:.2f}")
# Mean Absolute Error (MAE) — easier to interpret
mae = mean_absolute_error(y_test, y_pred)
print(f"MAE: {mae:.2f}")
# R² Score — how much variance the model explains
r2 = r2_score(y_test, y_pred)
print(f"R² Score: {r2:.4f}")
RMSE penalizes large errors more heavily than MAE. Use RMSE when big mistakes are costly. Use MAE when you want a straightforward "average error" number. R² gives you the big picture — 1.0 means the model explains all variance, 0.0 means it is no better than predicting the mean.
Unsupervised Learning — K-Means Clustering
When you do not have labels, unsupervised learning finds hidden patterns. K-Means is the simplest and most widely used clustering algorithm.
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
import numpy as np
# Generate sample data with 3 natural clusters
X, y_true = make_blobs(n_samples=300, centers=3, cluster_std=1.0, random_state=42)
# Scale the data (important for K-Means)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Apply K-Means clustering
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
kmeans.fit(X_scaled)
# Results
labels = kmeans.labels_ # Cluster assignment for each point
centers = kmeans.cluster_centers_ # Cluster center coordinates
inertia = kmeans.inertia_ # Sum of squared distances to nearest cluster
print(f"Cluster labels: {np.unique(labels)}")
print(f"Points per cluster: {np.bincount(labels)}")
print(f"Inertia: {inertia:.2f}")
# Predict cluster for new data
new_points = scaler.transform([[2.0, 3.0], [-1.0, -2.0]])
predictions = kmeans.predict(new_points)
print(f"New point cluster assignments: {predictions}")
The hardest part of K-Means is choosing the right number of clusters (K). The elbow method helps — plot inertia for different values of K and look for the "elbow" where adding more clusters stops helping:
import matplotlib.pyplot as plt
inertias = []
K_range = range(1, 10)
for k in K_range:
km = KMeans(n_clusters=k, random_state=42, n_init=10)
km.fit(X_scaled)
inertias.append(km.inertia_)
plt.figure(figsize=(8, 5))
plt.plot(K_range, inertias, "bo-")
plt.xlabel("Number of Clusters (K)")
plt.ylabel("Inertia")
plt.title("Elbow Method for Optimal K")
plt.grid(True)
plt.savefig("elbow_plot.png", dpi=100, bbox_inches="tight")
plt.show()
Data Visualization with matplotlib
You should always visualize your data before and after modeling. matplotlib is the standard tool for this.
Basic Plots
import matplotlib.pyplot as plt
import numpy as np
# Line plot
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.figure(figsize=(10, 6))
plt.plot(x, y, label="sin(x)", color="blue", linewidth=2)
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Simple Line Plot")
plt.legend()
plt.grid(True)
plt.savefig("line_plot.png", dpi=100, bbox_inches="tight")
plt.show()
Scatter Plot — Visualizing Clusters
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# Generate clustered data
X, y = make_blobs(n_samples=200, centers=3, cluster_std=1.2, random_state=42)
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, cmap="viridis", alpha=0.7, edgecolors="k")
plt.colorbar(scatter, label="Cluster")
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
plt.title("Scatter Plot of Clustered Data")
plt.grid(True, alpha=0.3)
plt.savefig("scatter_plot.png", dpi=100, bbox_inches="tight")
plt.show()
Confusion Matrix Heatmap
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
# Assuming y_test and y_pred are already defined
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(8, 6))
im = ax.imshow(cm, interpolation="nearest", cmap="Blues")
ax.figure.colorbar(im, ax=ax)
classes = iris.target_names
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=classes,
yticklabels=classes,
title="Confusion Matrix",
ylabel="Actual",
xlabel="Predicted")
# Display values in each cell
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, str(cm[i, j]),
ha="center", va="center",
color="white" if cm[i, j] > cm.max() / 2 else "black")
plt.tight_layout()
plt.savefig("confusion_matrix.png", dpi=100, bbox_inches="tight")
plt.show()
Practical Example: End-to-End ML Project
Let us put it all together. We will build a complete ML pipeline using the Iris dataset — from loading data to making predictions.
"""
End-to-End Machine Learning Project
Dataset: Iris (built into scikit-learn)
Task: Classify iris flowers into 3 species based on measurements
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# ============================================================
# STEP 1: Load and Explore the Data
# ============================================================
print("=" * 60)
print("STEP 1: Loading and Exploring Data")
print("=" * 60)
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["species"] = iris.target
df["species_name"] = df["species"].map(
{0: "setosa", 1: "versicolor", 2: "virginica"}
)
print(f"Dataset shape: {df.shape}")
print(f"\nFirst 5 rows:\n{df.head()}")
print(f"\nStatistical summary:\n{df.describe()}")
print(f"\nClass distribution:\n{df['species_name'].value_counts()}")
print(f"\nMissing values:\n{df.isnull().sum()}")
# ============================================================
# STEP 2: Data Preprocessing
# ============================================================
print("\n" + "=" * 60)
print("STEP 2: Preprocessing")
print("=" * 60)
# Separate features and target
X = df[iris.feature_names]
y = df["species"]
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f"Training set: {X_train.shape[0]} samples")
print(f"Test set: {X_test.shape[0]} samples")
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # Use transform, NOT fit_transform
# ============================================================
# STEP 3: Train Multiple Models
# ============================================================
print("\n" + "=" * 60)
print("STEP 3: Training Models")
print("=" * 60)
models = {
"Logistic Regression": LogisticRegression(max_iter=200, random_state=42),
"Decision Tree": DecisionTreeClassifier(max_depth=3, random_state=42),
"Random Forest": RandomForestClassifier(n_estimators=100, random_state=42),
}
results = {}
for name, model in models.items():
# Train
model.fit(X_train_scaled, y_train)
# Predict
y_pred = model.predict(X_test_scaled)
# Evaluate
accuracy = accuracy_score(y_test, y_pred)
results[name] = {"accuracy": accuracy, "predictions": y_pred}
# Cross-validation score (more robust than single split)
cv_scores = cross_val_score(model, X_train_scaled, y_train, cv=5)
print(f"\n{name}:")
print(f" Test Accuracy: {accuracy:.2%}")
print(f" Cross-Val Accuracy: {cv_scores.mean():.2%} (+/- {cv_scores.std():.2%})")
# ============================================================
# STEP 4: Detailed Evaluation of Best Model
# ============================================================
print("\n" + "=" * 60)
print("STEP 4: Detailed Evaluation")
print("=" * 60)
# Pick the best model
best_name = max(results, key=lambda k: results[k]["accuracy"])
best_pred = results[best_name]["predictions"]
print(f"\nBest model: {best_name}")
print(f"\nClassification Report:")
print(classification_report(y_test, best_pred, target_names=iris.target_names))
print(f"Confusion Matrix:")
print(confusion_matrix(y_test, best_pred))
# ============================================================
# STEP 5: Make Predictions on New Data
# ============================================================
print("\n" + "=" * 60)
print("STEP 5: Making Predictions")
print("=" * 60)
# Simulate new flower measurements
new_flowers = pd.DataFrame({
"sepal length (cm)": [5.1, 6.7, 5.8],
"sepal width (cm)": [3.5, 3.0, 2.7],
"petal length (cm)": [1.4, 5.2, 5.1],
"petal width (cm)": [0.2, 2.3, 1.9]
})
# Preprocess the same way as training data
new_flowers_scaled = scaler.transform(new_flowers)
# Get the best model object
best_model = models[best_name]
predictions = best_model.predict(new_flowers_scaled)
predicted_names = [iris.target_names[p] for p in predictions]
print("New flower predictions:")
for i, (_, row) in enumerate(new_flowers.iterrows()):
print(f" Flower {i+1}: {dict(row)} -> {predicted_names[i]}")
print("\nDone! Full pipeline complete.")
This is the pattern you will follow for every ML project. The specifics change — different datasets, different algorithms, different preprocessing — but the structure stays the same.
Common Pitfalls
These mistakes will burn you if you are not careful:
1. Overfitting
Your model memorizes the training data instead of learning general patterns. It performs great on training data and terribly on new data. Signs: high training accuracy, low test accuracy. Fix: use simpler models, add regularization, get more data, or use cross-validation.
2. Not Scaling Features
Algorithms like logistic regression, SVM, and K-Means are sensitive to feature scales. If one feature is in thousands and another is in decimals, the larger one dominates. Always scale your features — StandardScaler is a safe default.
3. Data Leakage
This is the silent killer. Data leakage happens when information from the test set leaks into the training process. The most common mistake: fitting your scaler on the entire dataset before splitting. Always fit_transform() on training data and transform() on test data.
# WRONG — data leakage! scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Learns from ALL data including test X_train, X_test = train_test_split(X_scaled, ...) # RIGHT — no leakage X_train, X_test = train_test_split(X, ...) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) # Learn from train only X_test_scaled = scaler.transform(X_test) # Apply same transformation
4. Ignoring Class Imbalance
If 95% of your data is class A and 5% is class B, the model will just predict A every time and get 95% accuracy. Fix: use stratified sampling, oversample the minority class (SMOTE), undersample the majority class, or use class weights in your model.
5. Evaluating on Training Data
Never report training accuracy as your model's performance. It is meaningless. Always evaluate on held-out test data that the model has never seen.
6. Jumping to Complex Models
Start with logistic regression or a simple decision tree. If a simple model gets 90% accuracy and a neural network gets 91%, the simple model wins — it is faster, more interpretable, and easier to maintain in production.
Best Practices
Habits that separate good ML practitioners from the rest:
- Always split your data — No exceptions. Use
train_test_splitor cross-validation. Never evaluate on training data. - Use cross-validation — A single train/test split can be misleading. K-fold cross-validation gives you a more reliable estimate of model performance.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5, scoring="accuracy")
print(f"CV Accuracy: {scores.mean():.2%} (+/- {scores.std():.2%})")
random_state everywhere. Pin your library versions. Document your preprocessing steps. Future you will thank present you.Pipeline ensures your preprocessing steps are applied consistently to training and test data.from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# Everything in one clean pipeline
pipe = Pipeline([
("scaler", StandardScaler()),
("classifier", LogisticRegression(max_iter=200))
])
pipe.fit(X_train, y_train)
accuracy = pipe.score(X_test, y_test)
print(f"Pipeline accuracy: {accuracy:.2%}")
Key Takeaways
- Machine learning is about learning patterns from data. Supervised learning uses labeled data, unsupervised learning finds hidden structure.
- The workflow is always the same: collect data, preprocess, split, train, evaluate, iterate.
- Preprocessing is 80% of the work. Handle missing values, scale features, encode categories properly.
- Start with scikit-learn. It covers regression, classification, clustering, and evaluation with a clean, consistent API.
- Always evaluate on unseen data. Train/test split and cross-validation are non-negotiable.
- Watch for data leakage. Fit your preprocessors on training data only.
- Start simple, add complexity only when needed. A logistic regression you understand beats a neural network you do not.
- Visualize everything. Your eyes catch patterns that metrics miss.
This tutorial gives you the foundation. From here, explore Random Forests, Gradient Boosting (XGBoost, LightGBM), Support Vector Machines, and eventually deep learning with TensorFlow or PyTorch. But master the basics first — they apply everywhere.
Regex
What is Regex?
Regex (short for Regular Expression) is a sequence of characters that defines a search pattern. Think of it as a mini-language specifically designed for matching, searching, extracting, and replacing text.
Here is a real-world analogy: imagine you are in a library looking for books. Instead of searching for one specific title, you tell the librarian: “Find me all books whose title starts with ‘Java’, has a number in the middle, and ends with ‘Guide’.” That description is essentially a regex — a template that matches multiple possibilities based on a pattern, not a fixed string.
In Java, regex is used everywhere:
- Validation — Check if user input matches an expected format (email, phone number, password)
- Search — Find all occurrences of a pattern in a large body of text
- Extraction — Pull specific pieces of data out of strings (dates from logs, numbers from reports)
- Replacement — Transform text by replacing matched patterns with new content
- Splitting — Break strings apart at complex delimiters
Without regex, tasks like “find all email addresses in a 10,000-line log file” would require dozens of lines of manual string parsing. With regex, it takes one line.
Java Regex Classes
Java provides regex support through the java.util.regex package, which contains three core classes:
| Class | Purpose | Key Methods |
|---|---|---|
Pattern |
A compiled representation of a regex pattern. Compiling is expensive, so you compile once and reuse. | compile(), matcher(), matches(), split() |
Matcher |
The engine that performs matching operations against a string using a Pattern. | matches(), find(), group(), replaceAll() |
PatternSyntaxException |
An unchecked exception thrown when a regex pattern has invalid syntax. | getMessage(), getPattern(), getIndex() |
The basic workflow for using regex in Java follows three steps:
- Compile the regex string into a
Patternobject - Create a Matcher by calling
pattern.matcher(inputString) - Execute a matching operation:
matches(),find(),lookingAt(), etc.
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexBasics {
public static void main(String[] args) {
// Step 1: Compile the pattern
Pattern pattern = Pattern.compile("Java");
// Step 2: Create a matcher for the input string
Matcher matcher = pattern.matcher("I love Java programming");
// Step 3: Execute matching operations
boolean found = matcher.find();
System.out.println("Found 'Java': " + found); // Found 'Java': true
// matches() checks if the ENTIRE string matches the pattern
boolean fullMatch = matcher.matches();
System.out.println("Entire string is 'Java': " + fullMatch); // Entire string is 'Java': false
// Reset and find the match position
matcher.reset();
if (matcher.find()) {
System.out.println("Match starts at index: " + matcher.start()); // Match starts at index: 7
System.out.println("Match ends at index: " + matcher.end()); // Match ends at index: 11
System.out.println("Matched text: " + matcher.group()); // Matched text: Java
}
}
}
There is an important distinction between three Matcher methods:
| Method | What it Checks | Example Pattern: "Java" |
|---|---|---|
matches() |
Does the entire string match the pattern? | "Java" returns true, "Java rocks" returns false |
find() |
Is the pattern found anywhere in the string? | "I love Java" returns true |
lookingAt() |
Does the beginning of the string match the pattern? | "Java rocks" returns true, "I love Java" returns false |
For quick one-off checks, you can skip the compile step and use the static Pattern.matches() method. However, this recompiles the pattern every time, so avoid it in loops or frequently called methods.
// Quick one-off match (compiles a new Pattern every call -- avoid in loops)
boolean isMatch = Pattern.matches("\\d+", "12345");
System.out.println("All digits: " + isMatch); // All digits: true
// Even quicker: String.matches() delegates to Pattern.matches()
boolean isDigits = "12345".matches("\\d+");
System.out.println("All digits: " + isDigits); // All digits: true
Basic Pattern Syntax
A regex pattern is built from two types of characters:
- Literal characters — Match themselves exactly. The pattern
catmatches the text “cat”. - Metacharacters — Special characters with special meaning. They are the building blocks of pattern logic.
Java has 14 metacharacters that have special meaning in regex. If you want to match these characters literally, you must escape them with a backslash (\).
| Metacharacter | Meaning | To Match Literally |
|---|---|---|
. |
Any single character (except newline by default) | \\. |
^ |
Start of string (or line in MULTILINE mode) | \\^ |
$ |
End of string (or line in MULTILINE mode) | \\$ |
* |
Zero or more of preceding element | \\* |
+ |
One or more of preceding element | \\+ |
? |
Zero or one of preceding element | \\? |
{ } |
Quantifier range (e.g., {2,5}) |
\\{ \\} |
[ ] |
Character class definition | \\[ \\] |
( ) |
Grouping and capturing | \\( \\) |
\ |
Escape character | \\\\ |
| |
Alternation (OR) | \\| |
Critical Java note: In Java strings, the backslash (\) is itself an escape character. So to write the regex \d (which means “a digit”), you must write "\\d" in Java code — the first backslash escapes the second one for Java, and the resulting \d is what the regex engine sees.
import java.util.regex.*;
public class MetacharacterEscaping {
public static void main(String[] args) {
// Without escaping: . matches ANY character
System.out.println("file.txt".matches("file.txt")); // true
System.out.println("fileXtxt".matches("file.txt")); // true -- oops, . matched 'X'
// With escaping: \\. matches only a literal dot
System.out.println("file.txt".matches("file\\.txt")); // true
System.out.println("fileXtxt".matches("file\\.txt")); // false -- correct!
// Matching a literal dollar sign in a price
Pattern price = Pattern.compile("\\$\\d+\\.\\d{2}");
System.out.println(price.matcher("$19.99").matches()); // true
System.out.println(price.matcher("$5.00").matches()); // true
System.out.println(price.matcher("19.99").matches()); // false -- missing $
// Use Pattern.quote() to treat an entire string as a literal
String userInput = "price is $10.00 (USD)";
String searchTerm = "$10.00";
Pattern literal = Pattern.compile(Pattern.quote(searchTerm));
Matcher m = literal.matcher(userInput);
System.out.println(m.find()); // true -- matched "$10.00" literally
}
}
Character Classes
A character class (also called a character set) matches a single character from a defined set. You define a character class by placing characters inside square brackets [].
Custom Character Classes
| Syntax | Meaning | Example | Matches |
|---|---|---|---|
[abc] |
Any one of a, b, or c | [aeiou] |
Any vowel |
[a-z] |
Any character in range a through z | [a-zA-Z] |
Any letter |
[0-9] |
Any digit 0 through 9 | [0-9a-f] |
Any hex digit |
[^abc] |
Any character except a, b, or c | [^0-9] |
Any non-digit |
[a-z&&[^aeiou]] |
Intersection: a-z but not vowels | [a-z&&[^aeiou]] |
Any consonant |
Predefined Character Classes
Java provides shorthand notation for commonly used character classes. These save typing and improve readability.
| Shorthand | Equivalent | Meaning |
|---|---|---|
\d |
[0-9] |
Any digit |
\D |
[^0-9] |
Any non-digit |
\w |
[a-zA-Z0-9_] |
Any word character (letter, digit, or underscore) |
\W |
[^a-zA-Z0-9_] |
Any non-word character |
\s |
[ \t\n\r\f] |
Any whitespace character |
\S |
[^ \t\n\r\f] |
Any non-whitespace character |
. |
(almost anything) | Any character except newline (unless DOTALL flag is set) |
Remember: in Java strings, you write \\d to produce the regex \d.
import java.util.regex.*;
public class CharacterClasses {
public static void main(String[] args) {
// Custom character class: match a vowel followed by a consonant
Pattern vc = Pattern.compile("[aeiou][^aeiou\\s\\d]");
Matcher m = vc.matcher("hello world");
while (m.find()) {
System.out.println("Found: " + m.group() + " at index " + m.start());
}
// Found: el at index 1
// Found: or at index 7
// \\d matches any digit
System.out.println("abc".matches("\\d+")); // false
System.out.println("123".matches("\\d+")); // true
// \\w matches word characters (letters, digits, underscore)
System.out.println("hello_world".matches("\\w+")); // true
System.out.println("hello world".matches("\\w+")); // false -- space is not a word char
// \\s matches whitespace
System.out.println("has spaces".matches(".*\\s.*")); // true
System.out.println("nospaces".matches(".*\\s.*")); // false
// . matches any character except newline
System.out.println("a".matches(".")); // true
System.out.println("1".matches(".")); // true
System.out.println("".matches(".")); // false -- needs exactly one char
// Ranges: hex digit check
Pattern hex = Pattern.compile("[0-9a-fA-F]+");
System.out.println(hex.matcher("1a2bFF").matches()); // true
System.out.println(hex.matcher("GHIJ").matches()); // false
// Negation: match non-digits
Matcher nonDigits = Pattern.compile("[^0-9]+").matcher("abc123def");
while (nonDigits.find()) {
System.out.println("Non-digit segment: " + nonDigits.group());
}
// Non-digit segment: abc
// Non-digit segment: def
}
}
Quantifiers
Quantifiers control how many times a preceding element must occur for a match. Without quantifiers, each element in a pattern matches exactly once.
Quantifier Reference
| Quantifier | Meaning | Example Pattern | Matches | Does Not Match |
|---|---|---|---|---|
* |
Zero or more | ab*c |
“ac”, “abc”, “abbc” | “adc” |
+ |
One or more | ab+c |
“abc”, “abbc” | “ac” |
? |
Zero or one (optional) | colou?r |
“color”, “colour” | “colouur” |
{n} |
Exactly n times | \\d{3} |
“123” | “12”, “1234” |
{n,} |
At least n times | \\d{2,} |
“12”, “123”, “1234” | “1” |
{n,m} |
Between n and m times | \\d{2,4} |
“12”, “123”, “1234” | “1”, “12345” |
Greedy vs Lazy Quantifiers
By default, all quantifiers are greedy — they match as much text as possible. Adding a ? after a quantifier makes it lazy (also called reluctant) — it matches as little text as possible.
| Greedy | Lazy | Behavior |
|---|---|---|
* |
*? |
Match as few as possible (zero or more) |
+ |
+? |
Match as few as possible (one or more) |
? |
?? |
Match zero if possible |
{n,m} |
{n,m}? |
Match n times if possible |
The difference matters most when your pattern has flexible parts and you need to control where the match stops.
import java.util.regex.*;
public class Quantifiers {
public static void main(String[] args) {
// Greedy vs Lazy demonstration
String html = "bold and more bold";
// Greedy: .* grabs as much as possible
Matcher greedy = Pattern.compile(".*").matcher(html);
if (greedy.find()) {
System.out.println("Greedy: " + greedy.group());
// Greedy: bold and more bold
// -- matched from first to LAST
}
// Lazy: .*? grabs as little as possible
Matcher lazy = Pattern.compile(".*?").matcher(html);
while (lazy.find()) {
System.out.println("Lazy: " + lazy.group());
}
// Lazy: bold
// Lazy: more bold
// -- matched each ... pair individually
// Exact count: match a US zip code (5 digits, optional -4 digits)
Pattern zip = Pattern.compile("\\d{5}(-\\d{4})?");
System.out.println(zip.matcher("90210").matches()); // true
System.out.println(zip.matcher("90210-1234").matches()); // true
System.out.println(zip.matcher("9021").matches()); // false
System.out.println(zip.matcher("902101234").matches()); // false
// Range: password length check (8 to 20 characters)
Pattern length = Pattern.compile(".{8,20}");
System.out.println(length.matcher("short").matches()); // false (5 chars)
System.out.println(length.matcher("justright").matches()); // true (9 chars)
System.out.println(length.matcher("a]".repeat(11)).matches()); // false (22 chars)
// Optional element: match "http" or "https"
Pattern protocol = Pattern.compile("https?://.*");
System.out.println(protocol.matcher("http://example.com").matches()); // true
System.out.println(protocol.matcher("https://example.com").matches()); // true
System.out.println(protocol.matcher("ftp://example.com").matches()); // false
}
}
Anchors and Boundaries
Anchors do not match characters — they match positions in the string. They assert that the current position in the string meets a certain condition.
| Anchor | Meaning | Example |
|---|---|---|
^ |
Start of string (or start of each line with MULTILINE flag) | ^Hello matches “Hello world” but not “Say Hello” |
$ |
End of string (or end of each line with MULTILINE flag) | world$ matches “Hello world” but not “world peace” |
\b |
Word boundary (between a word char and a non-word char) | \bcat\b matches “the cat sat” but not “concatenate” |
\B |
Non-word boundary (between two word chars or two non-word chars) | \Bcat\B matches “concatenate” but not “the cat sat” |
Word boundaries (\b) are one of the most useful anchors. A word boundary exists between a word character (\w) and a non-word character (\W), or at the start/end of the string if it begins/ends with a word character.
import java.util.regex.*;
public class AnchorsAndBoundaries {
public static void main(String[] args) {
// ^ and $ -- start and end anchors
System.out.println("Hello World".matches("^Hello.*")); // true
System.out.println("Say Hello".matches("^Hello.*")); // false
// Without anchors, find() looks anywhere in the string
Matcher m1 = Pattern.compile("error").matcher("An error occurred");
System.out.println(m1.find()); // true
// With anchors, matches() checks the entire string
System.out.println("An error occurred".matches("error")); // false -- not the whole string
System.out.println("error".matches("error")); // true
// \\b word boundary -- match whole words only
String text = "The cat scattered the catalog across the category";
Matcher wordCat = Pattern.compile("\\bcat\\b").matcher(text);
int count = 0;
while (wordCat.find()) {
System.out.println("Found whole word 'cat' at index " + wordCat.start());
count++;
}
System.out.println("Total matches: " + count);
// Found whole word 'cat' at index 4
// Total matches: 1
// -- "scattered", "catalog", and "category" were correctly excluded
// Without word boundary -- matches "cat" inside other words too
Matcher anyCat = Pattern.compile("cat").matcher(text);
count = 0;
while (anyCat.find()) {
count++;
}
System.out.println("Without boundary: " + count + " matches");
// Without boundary: 4 matches
// ^ and $ with MULTILINE flag -- match each line
String multiline = "First line\nSecond line\nThird line";
Matcher lineStarts = Pattern.compile("^\\w+", Pattern.MULTILINE).matcher(multiline);
while (lineStarts.find()) {
System.out.println("Line starts with: " + lineStarts.group());
}
// Line starts with: First
// Line starts with: Second
// Line starts with: Third
}
}
Groups and Capturing
Parentheses () in a regex serve two purposes: they group parts of the pattern together (so quantifiers or alternation can apply to the whole group), and they capture the matched text (so you can retrieve it later).
Capturing Groups
Each pair of parentheses creates a capturing group, numbered left-to-right starting at 1. Group 0 always refers to the entire match.
For the pattern (\\d{3})-(\\d{3})-(\\d{4}) matching “555-123-4567”:
group(0)= “555-123-4567” (entire match)group(1)= “555” (area code)group(2)= “123” (prefix)group(3)= “4567” (line number)
Named Groups
Numbered groups can be hard to read in complex patterns. Java supports named capturing groups using the syntax (?<name>...). You retrieve the value with matcher.group("name").
Non-Capturing Groups
Sometimes you need parentheses for grouping (e.g., to apply a quantifier to a group) but do not need to capture the matched text. Use (?:...) for a non-capturing group. This is slightly more efficient since the regex engine does not need to store the match.
Backreferences
A backreference refers back to a previously captured group within the same pattern. \\1 refers to the text matched by group 1, \\2 refers to group 2, and so on. This is useful for finding repeated patterns like duplicate words.
import java.util.regex.*;
public class GroupsAndCapturing {
public static void main(String[] args) {
// --- Numbered Capturing Groups ---
String phone = "Call me at 555-123-4567 or 800-555-0199";
Pattern phonePattern = Pattern.compile("(\\d{3})-(\\d{3})-(\\d{4})");
Matcher m = phonePattern.matcher(phone);
while (m.find()) {
System.out.println("Full match: " + m.group(0));
System.out.println("Area code: " + m.group(1));
System.out.println("Prefix: " + m.group(2));
System.out.println("Line number: " + m.group(3));
System.out.println();
}
// Full match: 555-123-4567
// Area code: 555
// Prefix: 123
// Line number: 4567
//
// Full match: 800-555-0199
// Area code: 800
// Prefix: 555
// Line number: 0199
// --- Named Capturing Groups ---
String dateStr = "2026-02-28";
Pattern datePattern = Pattern.compile(
"(?\\d{4})-(?\\d{2})-(?\\d{2})"
);
Matcher dm = datePattern.matcher(dateStr);
if (dm.matches()) {
System.out.println("Year: " + dm.group("year")); // Year: 2026
System.out.println("Month: " + dm.group("month")); // Month: 02
System.out.println("Day: " + dm.group("day")); // Day: 28
}
// --- Non-Capturing Groups ---
// Match "http" or "https" without capturing the "s"
Pattern url = Pattern.compile("(?:https?)://([\\w.]+)");
Matcher um = url.matcher("Visit https://example.com today");
if (um.find()) {
System.out.println("Full match: " + um.group(0)); // Full match: https://example.com
System.out.println("Domain: " + um.group(1)); // Domain: example.com
// group(1) is the domain, not "https" -- because (?:...) did not capture
}
// --- Backreferences: find duplicate words ---
String text = "This is is a test test of of duplicate words";
Pattern dupes = Pattern.compile("\\b(\\w+)\\s+\\1\\b", Pattern.CASE_INSENSITIVE);
Matcher dupeMatcher = dupes.matcher(text);
while (dupeMatcher.find()) {
System.out.println("Duplicate found: \"" + dupeMatcher.group() + "\"");
}
// Duplicate found: "is is"
// Duplicate found: "test test"
// Duplicate found: "of of"
}
}
Alternation and Lookaround
Alternation (OR)
The pipe character | acts as an OR operator. The pattern cat|dog matches either “cat” or “dog”. Alternation has the lowest precedence of any regex operator, so gray|grey matches “gray” or “grey”, not “gra” followed by “y|grey”.
To limit the scope of alternation, use parentheses: gr(a|e)y matches “gray” or “grey”.
Lookahead and Lookbehind
Lookaround assertions check if a pattern exists before or after the current position, but they do not consume characters (the match position does not advance). They are “zero-width assertions” — they assert a condition without including the matched text in the result.
| Syntax | Name | Meaning | Example |
|---|---|---|---|
(?=...) |
Positive lookahead | What follows must match | \\d+(?= dollars) matches “100” in “100 dollars” |
(?!...) |
Negative lookahead | What follows must NOT match | \\d+(?! dollars) matches “100” in “100 euros” |
(?<=...) |
Positive lookbehind | What precedes must match | (?<=\\$)\\d+ matches "50" in "$50" |
(? |
Negative lookbehind | What precedes must NOT match | (? matches "50" in "50" but not in "$50" |
Lookarounds are especially useful in password validation, where you need to check multiple conditions at the same position (e.g., must contain a digit AND a special character AND an uppercase letter).
import java.util.regex.*;
public class AlternationAndLookaround {
public static void main(String[] args) {
// --- Alternation ---
Pattern pet = Pattern.compile("cat|dog|bird");
String text = "I have a cat and a dog but no bird";
Matcher m = pet.matcher(text);
while (m.find()) {
System.out.println("Found pet: " + m.group());
}
// Found pet: cat
// Found pet: dog
// Found pet: bird
// Alternation with grouping
Pattern color = Pattern.compile("gr(a|e)y");
System.out.println(color.matcher("gray").matches()); // true
System.out.println(color.matcher("grey").matches()); // true
System.out.println(color.matcher("griy").matches()); // false
// --- Positive Lookahead: find numbers followed by "px" ---
Matcher lookahead = Pattern.compile("\\d+(?=px)").matcher("width: 100px; height: 50px; margin: 10em");
while (lookahead.find()) {
System.out.println("Pixel value: " + lookahead.group());
}
// Pixel value: 100
// Pixel value: 50
// -- "10" was excluded because it is followed by "em", not "px"
// --- Negative Lookahead: find numbers NOT followed by "px" ---
Matcher negLookahead = Pattern.compile("\\d+(?!px)").matcher("width: 100px; margin: 10em");
while (negLookahead.find()) {
System.out.println("Non-pixel: " + negLookahead.group());
}
// Non-pixel: 10
// Non-pixel: 10
// --- Positive Lookbehind: extract amounts after $ ---
Matcher lookbehind = Pattern.compile("(?<=\\$)\\d+\\.?\\d*").matcher("Price: $19.99 and $5.00");
while (lookbehind.find()) {
System.out.println("Amount: " + lookbehind.group());
}
// Amount: 19.99
// Amount: 5.00
// --- Password validation using multiple lookaheads ---
// At least 8 chars, one uppercase, one lowercase, one digit, one special char
Pattern strongPassword = Pattern.compile(
"^(?=.*[A-Z])" + // at least one uppercase
"(?=.*[a-z])" + // at least one lowercase
"(?=.*\\d)" + // at least one digit
"(?=.*[@#$%^&+=!])" + // at least one special character
".{8,}$" // at least 8 characters total
);
String[] passwords = {"Passw0rd!", "password", "SHORT1!", "MyP@ss12"};
for (String pw : passwords) {
boolean strong = strongPassword.matcher(pw).matches();
System.out.println(pw + " -> " + (strong ? "STRONG" : "WEAK"));
}
// Passw0rd! -> STRONG
// password -> WEAK
// SHORT1! -> WEAK
// MyP@ss12 -> STRONG
}
}
Common String Methods with Regex
Java's String class has several built-in methods that accept regex patterns. These are convenient for simple use cases where you do not need the full power of Pattern and Matcher.
| Method | What it Does | Returns |
|---|---|---|
String.matches(regex) |
Tests if the entire string matches the regex | boolean |
String.split(regex) |
Splits the string at each match of the regex | String[] |
String.split(regex, limit) |
Splits with a limit on the number of parts | String[] |
String.replaceAll(regex, replacement) |
Replaces all matches with the replacement | String |
String.replaceFirst(regex, replacement) |
Replaces only the first match | String |
Performance warning: Every call to these methods compiles a new Pattern internally. If you call them in a loop or frequently, compile the Pattern once yourself and use Matcher instead.
import java.util.Arrays;
public class StringRegexMethods {
public static void main(String[] args) {
// --- matches() -- checks the ENTIRE string ---
System.out.println("12345".matches("\\d+")); // true
System.out.println("123abc".matches("\\d+")); // false -- not all digits
System.out.println("hello".matches("[a-z]+")); // true
// --- split() -- break a string into parts ---
// Split on one or more whitespace characters
String sentence = "Split this string up";
String[] words = sentence.split("\\s+");
System.out.println(Arrays.toString(words));
// [Split, this, string, up]
// Split a CSV line (handles optional spaces after commas)
String csv = "Java, Python, C++, JavaScript";
String[] languages = csv.split(",\\s*");
System.out.println(Arrays.toString(languages));
// [Java, Python, C++, JavaScript]
// Split with a limit
String path = "com.example.project.Main";
String[] parts = path.split("\\.", 3); // at most 3 parts
System.out.println(Arrays.toString(parts));
// [com, example, project.Main]
// --- replaceAll() -- replace all matches ---
// Remove all non-alphanumeric characters
String dirty = "Hello, World! @2026";
String clean = dirty.replaceAll("[^a-zA-Z0-9]", "");
System.out.println(clean); // HelloWorld2026
// Normalize whitespace: replace multiple spaces/tabs with a single space
String messy = "too many spaces here";
String normalized = messy.replaceAll("\\s+", " ");
System.out.println(normalized); // too many spaces here
// --- replaceFirst() -- replace only the first match ---
String text = "error: file not found. error: permission denied.";
String result = text.replaceFirst("error", "WARNING");
System.out.println(result);
// WARNING: file not found. error: permission denied.
// Use captured groups in replacement with $1, $2, etc.
// Reformat dates from MM/DD/YYYY to YYYY-MM-DD
String date = "02/28/2026";
String reformatted = date.replaceAll("(\\d{2})/(\\d{2})/(\\d{4})", "$3-$1-$2");
System.out.println(reformatted); // 2026-02-28
}
}
Pattern Flags
Pattern flags modify how the regex engine interprets the pattern. You pass them as the second argument to Pattern.compile(), or embed them directly in the pattern using inline flag syntax.
| Flag Constant | Inline | Effect |
|---|---|---|
Pattern.CASE_INSENSITIVE |
(?i) |
Matches letters regardless of case. abc matches "ABC". |
Pattern.MULTILINE |
(?m) |
^ and $ match start/end of each line, not just the entire string. |
Pattern.DOTALL |
(?s) |
. matches any character including newline. |
Pattern.COMMENTS |
(?x) |
Whitespace and comments (# to end of line) in the pattern are ignored. Great for readability. |
Pattern.UNICODE_CASE |
(?u) |
Case-insensitive matching follows Unicode rules, not just ASCII. |
Pattern.LITERAL |
-- | The pattern is treated as a literal string (metacharacters have no special meaning). |
You can combine multiple flags using the bitwise OR operator (|).
import java.util.regex.*;
public class PatternFlags {
public static void main(String[] args) {
// --- CASE_INSENSITIVE ---
Pattern ci = Pattern.compile("java", Pattern.CASE_INSENSITIVE);
System.out.println(ci.matcher("JAVA").matches()); // true
System.out.println(ci.matcher("Java").matches()); // true
System.out.println(ci.matcher("jAvA").matches()); // true
// Same thing using inline flag (?i)
System.out.println("JAVA".matches("(?i)java")); // true
// --- MULTILINE ---
String log = "ERROR: disk full\nWARN: low memory\nERROR: timeout";
Pattern errorLines = Pattern.compile("^ERROR.*$", Pattern.MULTILINE);
Matcher m = errorLines.matcher(log);
while (m.find()) {
System.out.println(m.group());
}
// ERROR: disk full
// ERROR: timeout
// --- DOTALL ---
String html = "\nHello\nWorld\n";
// Without DOTALL, . does not match newlines
System.out.println(html.matches(".*")); // false
// With DOTALL, . matches everything including newlines
Pattern dotall = Pattern.compile(".*", Pattern.DOTALL);
System.out.println(dotall.matcher(html).matches()); // true
// --- COMMENTS -- write readable patterns ---
Pattern readable = Pattern.compile(
"\\d{3}" + // area code
"-" + // separator
"\\d{3}" + // prefix
"-" + // separator
"\\d{4}" // line number
);
System.out.println(readable.matcher("555-123-4567").matches()); // true
// Using COMMENTS flag with whitespace and # comments in the pattern itself
Pattern commented = Pattern.compile(
"(?x) " + // enable comments mode
"\\d{3} " + // area code
"- " + // dash separator
"\\d{3} " + // prefix
"- " + // dash separator
"\\d{4} " // line number
);
System.out.println(commented.matcher("555-123-4567").matches()); // true
// --- Combining multiple flags ---
Pattern combined = Pattern.compile(
"^error.*$",
Pattern.CASE_INSENSITIVE | Pattern.MULTILINE
);
Matcher cm = combined.matcher("Error: something\nERROR: another\ninfo: ok");
while (cm.find()) {
System.out.println("Found: " + cm.group());
}
// Found: Error: something
// Found: ERROR: another
}
}
Practical Validation Examples
One of the most common uses of regex is input validation. Below are battle-tested patterns for common formats, each broken down so you understand every part.
1. Email Validation
A simplified but practical email regex. Note that the full RFC 5322 email spec is extremely complex -- this pattern covers the vast majority of real-world addresses.
// Email: local-part@domain.tld
// ^ -- start of string
// [a-zA-Z0-9._%+-]+ -- local part: letters, digits, dots, underscores, %, +, -
// @ -- literal @ symbol
// [a-zA-Z0-9.-]+ -- domain: letters, digits, dots, hyphens
// \. -- literal dot before TLD
// [a-zA-Z]{2,} -- TLD: at least 2 letters (com, org, io, etc.)
// $ -- end of string
String emailRegex = "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$";
String[] emails = {"user@example.com", "first.last@company.co.uk", "invalid@", "@nodomain.com", "test@site.io"};
for (String email : emails) {
System.out.println(email + " -> " + (email.matches(emailRegex) ? "VALID" : "INVALID"));
}
// user@example.com -> VALID
// first.last@company.co.uk -> VALID
// invalid@ -> INVALID
// @nodomain.com -> INVALID
// test@site.io -> VALID
2. Phone Number (US)
Matches multiple common US phone formats: (555) 123-4567, 555-123-4567, 5551234567, +1-555-123-4567.
// US phone: optional country code, various separator formats
// ^ -- start
// (\\+1[- ]?)? -- optional +1 country code with optional separator
// \\(? -- optional opening parenthesis
// \\d{3} -- area code (3 digits)
// \\)? -- optional closing parenthesis
// [- ]? -- optional separator (dash or space)
// \\d{3} -- prefix (3 digits)
// [- ]? -- optional separator
// \\d{4} -- line number (4 digits)
// $ -- end
String phoneRegex = "^(\\+1[- ]?)?(\\(?\\d{3}\\)?[- ]?)?\\d{3}[- ]?\\d{4}$";
String[] phones = {"(555) 123-4567", "555-123-4567", "5551234567", "+1-555-123-4567", "123"};
for (String phone : phones) {
System.out.println(phone + " -> " + (phone.matches(phoneRegex) ? "VALID" : "INVALID"));
}
// (555) 123-4567 -> VALID
// 555-123-4567 -> VALID
// 5551234567 -> VALID
// +1-555-123-4567 -> VALID
// 123 -> INVALID
3. Password Strength
Uses lookaheads to enforce multiple rules simultaneously: minimum length, uppercase, lowercase, digit, and special character.
// Password must have:
// (?=.*[A-Z]) -- at least one uppercase letter
// (?=.*[a-z]) -- at least one lowercase letter
// (?=.*\\d) -- at least one digit
// (?=.*[@#$%^&+=!]) -- at least one special character
// .{8,20} -- between 8 and 20 characters total
String passwordRegex = "^(?=.*[A-Z])(?=.*[a-z])(?=.*\\d)(?=.*[@#$%^&+=!]).{8,20}$";
String[] passwords = {"Str0ng!Pass", "weakpassword", "SHORT1!", "NoSpecial1", "G00d@Pwd"};
for (String pw : passwords) {
System.out.println(pw + " -> " + (pw.matches(passwordRegex) ? "STRONG" : "WEAK"));
}
// Str0ng!Pass -> STRONG
// weakpassword -> WEAK (no uppercase, no digit, no special)
// SHORT1! -> WEAK (less than 8 chars)
// NoSpecial1 -> WEAK (no special character)
// G00d@Pwd -> STRONG
4. URL Validation
// URL: protocol://domain:port/path?query#fragment
// ^https?:// -- http or https
// [\\w.-]+ -- domain name
// (:\\d{1,5})? -- optional port (1-5 digits)
// (/[\\w./-]*)* -- optional path segments
// (\\?[\\w=&%-]*)? -- optional query string
// (#[\\w-]*)? -- optional fragment
// $
String urlRegex = "^https?://[\\w.-]+(:\\d{1,5})?(/[\\w./-]*)*(\\?[\\w=&%-]*)?(#[\\w-]*)?$";
String[] urls = {
"https://example.com",
"http://localhost:8080/api/users",
"https://site.com/page?name=test&id=5",
"ftp://invalid.com",
"https://example.com/path#section"
};
for (String url : urls) {
System.out.println(url + " -> " + (url.matches(urlRegex) ? "VALID" : "INVALID"));
}
// https://example.com -> VALID
// http://localhost:8080/api/users -> VALID
// https://site.com/page?name=test&id=5 -> VALID
// ftp://invalid.com -> INVALID
// https://example.com/path#section -> VALID
5. IP Address (IPv4)
// IPv4: four octets (0-255) separated by dots
// Each octet: 25[0-5] | 2[0-4]\\d | [01]?\\d{1,2}
// This handles: 0-9, 10-99, 100-199, 200-249, 250-255
String ipRegex = "^((25[0-5]|2[0-4]\\d|[01]?\\d{1,2})\\.){3}(25[0-5]|2[0-4]\\d|[01]?\\d{1,2})$";
String[] ips = {"192.168.1.1", "255.255.255.255", "0.0.0.0", "256.1.1.1", "192.168.1"};
for (String ip : ips) {
System.out.println(ip + " -> " + (ip.matches(ipRegex) ? "VALID" : "INVALID"));
}
// 192.168.1.1 -> VALID
// 255.255.255.255 -> VALID
// 0.0.0.0 -> VALID
// 256.1.1.1 -> INVALID (256 is out of range)
// 192.168.1 -> INVALID (only 3 octets)
6. Date Format (YYYY-MM-DD)
// Date: YYYY-MM-DD (basic format validation, not full calendar validation)
// \\d{4} -- 4-digit year
// - -- separator
// (0[1-9]|1[0-2]) -- month: 01-12
// - -- separator
// (0[1-9]|[12]\\d|3[01]) -- day: 01-31
String dateRegex = "^\\d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12]\\d|3[01])$";
String[] dates = {"2026-02-28", "2026-13-01", "2026-00-15", "2026-12-31", "26-01-01"};
for (String date : dates) {
System.out.println(date + " -> " + (date.matches(dateRegex) ? "VALID" : "INVALID"));
}
// 2026-02-28 -> VALID
// 2026-13-01 -> INVALID (month 13)
// 2026-00-15 -> INVALID (month 00)
// 2026-12-31 -> VALID
// 26-01-01 -> INVALID (2-digit year)
7. Credit Card Number
// Credit card: 13-19 digits, optionally separated by spaces or dashes every 4 digits
// Common formats: Visa (4xxx), Mastercard (5xxx), Amex (34xx/37xx)
String ccRegex = "^\\d{4}[- ]?\\d{4}[- ]?\\d{4}[- ]?\\d{1,7}$";
String[] cards = {"4111111111111111", "4111-1111-1111-1111", "4111 1111 1111 1111", "411", "1234567890123456789012"};
for (String card : cards) {
System.out.println(card + " -> " + (card.matches(ccRegex) ? "VALID FORMAT" : "INVALID FORMAT"));
}
// 4111111111111111 -> VALID FORMAT
// 4111-1111-1111-1111 -> VALID FORMAT
// 4111 1111 1111 1111 -> VALID FORMAT
// 411 -> INVALID FORMAT
// 1234567890123456789012 -> INVALID FORMAT
// Note: this only validates the FORMAT, not the actual card number.
// Use the Luhn algorithm for checksum validation.
8. Social Security Number (SSN)
// SSN format: XXX-XX-XXXX
// (?!000|666) -- area number cannot be 000 or 666
// (?!9) -- area number cannot start with 9
// \\d{3} -- 3-digit area number
// - -- separator
// (?!00)\\d{2} -- 2-digit group number (not 00)
// - -- separator
// (?!0000)\\d{4} -- 4-digit serial number (not 0000)
String ssnRegex = "^(?!000|666)(?!9\\d{2})\\d{3}-(?!00)\\d{2}-(?!0000)\\d{4}$";
String[] ssns = {"123-45-6789", "000-12-3456", "666-12-3456", "900-12-3456", "123-00-6789", "123-45-0000"};
for (String ssn : ssns) {
System.out.println(ssn + " -> " + (ssn.matches(ssnRegex) ? "VALID" : "INVALID"));
}
// 123-45-6789 -> VALID
// 000-12-3456 -> INVALID (area 000)
// 666-12-3456 -> INVALID (area 666)
// 900-12-3456 -> INVALID (area starts with 9)
// 123-00-6789 -> INVALID (group 00)
// 123-45-0000 -> INVALID (serial 0000)
Search and Replace
Beyond validation, regex is heavily used for searching text and performing replacements. The Matcher class gives you fine-grained control over the search and replace process.
Finding All Matches with find()
The find() method scans the input for the next match. Call it in a while loop to iterate through all matches.
import java.util.regex.*;
import java.util.ArrayList;
import java.util.List;
public class SearchAndReplace {
public static void main(String[] args) {
// --- Finding all matches ---
String text = "Contact us at support@company.com or sales@company.com. " +
"Personal: john.doe@gmail.com";
Pattern emailPattern = Pattern.compile("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}");
Matcher finder = emailPattern.matcher(text);
List emails = new ArrayList<>();
while (finder.find()) {
emails.add(finder.group());
System.out.println("Found email at [" + finder.start() + "-" + finder.end() + "]: " + finder.group());
}
// Found email at [17-36]: support@company.com
// Found email at [40-57]: sales@company.com
// Found email at [69-88]: john.doe@gmail.com
System.out.println("Total emails found: " + emails.size()); // Total emails found: 3
// --- Simple replaceAll ---
String censored = emailPattern.matcher(text).replaceAll("[REDACTED]");
System.out.println(censored);
// Contact us at [REDACTED] or [REDACTED]. Personal: [REDACTED]
// --- replaceFirst ---
String firstOnly = emailPattern.matcher(text).replaceFirst("[REDACTED]");
System.out.println(firstOnly);
// Contact us at [REDACTED] or sales@company.com. Personal: john.doe@gmail.com
}
}
Custom Replacement with appendReplacement / appendTail
When you need dynamic replacements (e.g., the replacement depends on the matched value), use appendReplacement() and appendTail(). This pair lets you build a result string incrementally, applying custom logic to each match.
import java.util.regex.*;
public class CustomReplacement {
public static void main(String[] args) {
// Convert all words to title case using appendReplacement
String input = "the quick brown fox jumps over the lazy dog";
Pattern wordPattern = Pattern.compile("\\b([a-z])(\\w*)");
Matcher m = wordPattern.matcher(input);
StringBuilder result = new StringBuilder();
while (m.find()) {
String titleCase = m.group(1).toUpperCase() + m.group(2);
m.appendReplacement(result, titleCase);
}
m.appendTail(result);
System.out.println(result);
// The Quick Brown Fox Jumps Over The Lazy Dog
// Mask credit card numbers: show only last 4 digits
String data = "Card: 4111-1111-1111-1111, Another: 5500-0000-0000-0004";
Pattern ccPattern = Pattern.compile("(\\d{4})[- ]?(\\d{4})[- ]?(\\d{4})[- ]?(\\d{4})");
Matcher ccMatcher = ccPattern.matcher(data);
StringBuilder masked = new StringBuilder();
while (ccMatcher.find()) {
String replacement = "****-****-****-" + ccMatcher.group(4);
ccMatcher.appendReplacement(masked, replacement);
}
ccMatcher.appendTail(masked);
System.out.println(masked);
// Card: ****-****-****-1111, Another: ****-****-****-0004
// Java 9+: Matcher.replaceAll with a Function
String prices = "Items cost $5 and $23 and $100";
Pattern pricePattern = Pattern.compile("\\$(\\d+)");
String doubled = pricePattern.matcher(prices).replaceAll(mr -> {
int amount = Integer.parseInt(mr.group(1));
return "\\$" + (amount * 2);
});
System.out.println(doubled);
// Items cost $10 and $46 and $200
}
}
Common Mistakes
Even experienced developers make regex mistakes. Here are the most frequent pitfalls and how to avoid them.
1. Forgetting to Double-Escape Backslashes in Java
This is the number one mistake for Java developers. In regex, \d means "digit." In a Java string, \d is not a valid escape sequence. You must write \\d so Java's string parser produces the single backslash that the regex engine expects.
// WRONG -- Java does not recognize \d as a string escape
// String pattern = "\d+"; // Compilation error!
// CORRECT -- double backslash to produce \d for the regex engine
String pattern = "\\d+";
// To match a literal backslash in text, you need FOUR backslashes:
// Java string: "\\\\" -> produces: \\ -> regex sees: \ (literal backslash)
String backslashPattern = "\\\\";
System.out.println("C:\\Users".matches(".*\\\\.*")); // true
2. Catastrophic Backtracking
Certain regex patterns can cause the engine to take an exponential amount of time on certain inputs. This happens when a pattern has nested quantifiers that can match the same characters in multiple ways.
// DANGEROUS -- nested quantifiers can cause catastrophic backtracking // String bad = "(a+)+b"; // On input "aaaaaaaaaaaaaaaaaac", the engine tries every possible way // to split the 'a's between the inner and outer groups before failing. // This can freeze your application. // SAFE -- flatten the nesting String safe = "a+b"; // This matches the same thing but without the exponential backtracking risk. // Another common danger: matching quoted strings with nested quantifiers // DANGEROUS: "(.*)*" // SAFE: "[^"]*" -- use negated character class instead
3. Overly Complex Patterns
If your regex is more than about 80 characters long, consider breaking the validation into multiple simpler steps. A 200-character regex that validates everything at once is nearly impossible to maintain.
// BAD -- one massive unreadable regex
// String nightmare = "^(?=.*[A-Z])(?=.*[a-z])(?=.*\\d)(?=.*[@#$%^&+=!])[a-zA-Z0-9@#$%^&+=!]{8,20}$";
// BETTER -- break into understandable steps
public static boolean isStrongPassword(String password) {
if (password == null) return false;
if (password.length() < 8 || password.length() > 20) return false;
if (!password.matches(".*[A-Z].*")) return false; // needs uppercase
if (!password.matches(".*[a-z].*")) return false; // needs lowercase
if (!password.matches(".*\\d.*")) return false; // needs digit
if (!password.matches(".*[@#$%^&+=!].*")) return false; // needs special char
return true;
}
// Easier to read, debug, and extend. Each rule is independently testable.
4. Testing Only the Happy Path
Always test your regex with edge cases: empty strings, very long strings, strings with special characters, and strings that are close to matching but should not.
// Testing an email regex -- you need ALL of these test cases
String emailRegex = "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$";
// Happy path
assert "user@example.com".matches(emailRegex); // standard email
assert "first.last@company.co.uk".matches(emailRegex); // dots and subdomains
// Edge cases that should FAIL
assert !"".matches(emailRegex); // empty string
assert !"@example.com".matches(emailRegex); // missing local part
assert !"user@".matches(emailRegex); // missing domain
assert !"user@.com".matches(emailRegex); // domain starts with dot
assert !"user@com".matches(emailRegex); // no TLD separator
assert !"user@@example.com".matches(emailRegex); // double @
// Edge cases that should PASS
assert "a@b.co".matches(emailRegex); // minimal valid email
assert "user+tag@gmail.com".matches(emailRegex); // plus addressing
5. Using matches() When You Meant find()
String.matches() and Matcher.matches() check if the entire string matches the pattern. If you want to check if the pattern appears anywhere in the string, use Matcher.find().
String text = "Error code: 404";
// WRONG -- matches() checks the ENTIRE string
System.out.println(text.matches("\\d+")); // false -- the entire string is not digits
// CORRECT -- find() searches for the pattern anywhere
Matcher m = Pattern.compile("\\d+").matcher(text);
System.out.println(m.find()); // true
System.out.println(m.group()); // 404
// If you must use matches(), wrap the pattern with .*
System.out.println(text.matches(".*\\d+.*")); // true -- but find() is cleaner
Best Practices
Follow these guidelines to write regex that is correct, readable, and performant.
1. Compile Patterns Once
The Pattern.compile() method is expensive. If you use the same regex multiple times (in a loop, in a method called frequently, etc.), compile it once and store it as a static final field.
public class UserValidator {
// GOOD -- compiled once, reused many times
private static final Pattern EMAIL_PATTERN =
Pattern.compile("^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$");
private static final Pattern PHONE_PATTERN =
Pattern.compile("^(\\+1[- ]?)?(\\(?\\d{3}\\)?[- ]?)?\\d{3}[- ]?\\d{4}$");
public static boolean isValidEmail(String email) {
return email != null && EMAIL_PATTERN.matcher(email).matches();
}
public static boolean isValidPhone(String phone) {
return phone != null && PHONE_PATTERN.matcher(phone).matches();
}
// BAD -- compiles a new Pattern on every call
// public static boolean isValidEmailBad(String email) {
// return email.matches("^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$");
// }
}
2. Use Named Groups for Readability
Named groups make your code self-documenting. Instead of remembering that group(3) is the year, use group("year").
3. Use Pattern.quote() for Literal Matching
When you are searching for user-supplied text that might contain regex metacharacters, use Pattern.quote() to escape everything automatically.
4. Keep Patterns Simple
If a regex grows beyond a readable length, consider breaking the validation into multiple steps or using a combination of regex and plain Java logic.
5. Comment Complex Patterns
Use Java string concatenation with comments, or the COMMENTS flag, to make complex patterns understandable.
6. Test with Edge Cases
Always test with: empty strings, null input, maximum-length input, strings with only special characters, strings that are "almost" valid, and internationalized input (if applicable).
7. Prefer Specific Patterns Over Greedy Wildcards
Instead of .* (which matches anything), use character classes that describe what you actually expect: [^"]* instead of .* inside quotes, \\d+ instead of .+ for numbers.
Best Practices Summary
| Practice | Do | Do Not |
|---|---|---|
| Compile patterns | static final Pattern P = Pattern.compile(...) |
str.matches("...") in a loop |
| Escape user input | Pattern.quote(userInput) |
Concatenate user input directly into regex |
| Name groups | (?<year>\\d{4}) |
(\\d{4}) then group(1) |
| Be specific | [^"]* between quotes |
.* between quotes |
| Handle null | Check null before matching |
Call .matches() on nullable values |
| Break complex logic | Multiple simple checks | One enormous regex |
| Test edge cases | Empty, long, special chars, near-misses | Test only the happy path |
Quick Reference Table
A comprehensive reference of all regex syntax elements covered in this tutorial.
| Category | Syntax | Meaning | Java String |
|---|---|---|---|
| Character Classes | [abc] |
Any of a, b, or c | "[abc]" |
[^abc] |
Not a, b, or c | "[^abc]" |
|
[a-z] |
Range a through z | "[a-z]" |
|
\d / \D |
Digit / Non-digit | "\\d" / "\\D" |
|
\w / \W |
Word char / Non-word char | "\\w" / "\\W" |
|
\s / \S |
Whitespace / Non-whitespace | "\\s" / "\\S" |
|
. |
Any character (except newline) | "." |
|
| Quantifiers | * |
Zero or more | "a*" |
+ |
One or more | "a+" |
|
? |
Zero or one | "a?" |
|
{n} |
Exactly n | "a{3}" |
|
{n,m} |
Between n and m | "a{2,5}" |
|
*? / +? |
Lazy (minimal) match | "a*?" / "a+?" |
|
| Anchors | ^ |
Start of string/line | "^" |
$ |
End of string/line | "$" |
|
\b |
Word boundary | "\\b" |
|
\B |
Non-word boundary | "\\B" |
|
| Groups | (...) |
Capturing group | "(abc)" |
(?:...) |
Non-capturing group | "(?:abc)" |
|
(?<name>...) |
Named group | "(?<name>abc)" |
|
\1 |
Backreference to group 1 | "\\1" |
|
| |
Alternation (OR) | "cat|dog" |
|
| Lookaround | (?=...) |
Positive lookahead | "(?=abc)" |
(?!...) |
Negative lookahead | "(?!abc)" |
|
(?<=...) |
Positive lookbehind | "(?<=abc)" |
|
(? |
Negative lookbehind | "(? |
|
| Flags | (?i) |
Case insensitive | Pattern.CASE_INSENSITIVE |
(?m) |
Multiline (^ $ match lines) | Pattern.MULTILINE |
|
(?s) |
Dotall (. matches newline) | Pattern.DOTALL |
|
(?x) |
Comments mode | Pattern.COMMENTS |
|
(?u) |
Unicode case | Pattern.UNICODE_CASE |
|
| -- | Literal (no metacharacters) | Pattern.LITERAL |
Complete Practical Example: Log Parser and Input Validator
This final example brings together everything we have learned. It is a complete, runnable program that demonstrates regex in two real-world scenarios: parsing structured log files and validating user input for a registration form.
import java.util.regex.*;
import java.util.*;
import java.util.stream.Collectors;
/**
* Complete Regex Example: LogParser and InputValidator
*
* Demonstrates:
* - Pattern compilation and reuse (static final)
* - Named capturing groups
* - Multiple validation patterns
* - find() with while loop for extraction
* - replaceAll for data masking
* - appendReplacement for custom replacement
* - Lookaheads for password validation
* - Word boundaries
* - Greedy vs lazy matching
* - Pattern flags
*/
public class RegexDemo {
// =========================================================================
// Part 1: Log Parser -- Extract structured data from log entries
// =========================================================================
// Pre-compiled patterns (compiled once, reused across all calls)
private static final Pattern LOG_PATTERN = Pattern.compile(
"(?\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2})" + // 2026-02-28 14:30:00
"\\s+\\[(?\\w+)]" + // [ERROR]
"\\s+(?[\\w.]+)" + // com.app.Service
"\\s+-\\s+(?.*)" // - The log message
);
private static final Pattern IP_PATTERN = Pattern.compile(
"\\b(?:(?:25[0-5]|2[0-4]\\d|[01]?\\d{1,2})\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d{1,2})\\b"
);
private static final Pattern ERROR_CODE_PATTERN = Pattern.compile(
"\\b[A-Z]{2,4}-\\d{3,5}\\b" // e.g., ERR-5001, HTTP-404
);
public static void parseLogEntries(String[] logLines) {
System.out.println("=== LOG PARSER RESULTS ===");
System.out.println();
Map levelCounts = new LinkedHashMap<>();
List errorMessages = new ArrayList<>();
for (String line : logLines) {
Matcher m = LOG_PATTERN.matcher(line);
if (m.matches()) {
String timestamp = m.group("timestamp");
String level = m.group("level");
String className = m.group("class");
String message = m.group("message");
// Count log levels
levelCounts.merge(level, 1, Integer::sum);
// Collect error messages
if ("ERROR".equals(level)) {
errorMessages.add(timestamp + " | " + className + " | " + message);
}
// Extract IP addresses from the message
Matcher ipMatcher = IP_PATTERN.matcher(message);
while (ipMatcher.find()) {
System.out.println(" IP found in log: " + ipMatcher.group()
+ " (from " + className + ")");
}
// Extract error codes from the message
Matcher codeMatcher = ERROR_CODE_PATTERN.matcher(message);
while (codeMatcher.find()) {
System.out.println(" Error code found: " + codeMatcher.group()
+ " (at " + timestamp + ")");
}
}
}
System.out.println();
System.out.println("Log Level Summary:");
levelCounts.forEach((level, count) ->
System.out.println(" " + level + ": " + count));
System.out.println();
System.out.println("Error Messages:");
errorMessages.forEach(msg -> System.out.println(" " + msg));
}
// =========================================================================
// Part 2: Input Validator -- Validate form fields for user registration
// =========================================================================
private static final Pattern EMAIL_PATTERN = Pattern.compile(
"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$"
);
private static final Pattern PHONE_PATTERN = Pattern.compile(
"^(\\+1[- ]?)?(\\(?\\d{3}\\)?[- ]?)?\\d{3}[- ]?\\d{4}$"
);
private static final Pattern PASSWORD_PATTERN = Pattern.compile(
"^(?=.*[A-Z])(?=.*[a-z])(?=.*\\d)(?=.*[@#$%^&+=!]).{8,20}$"
);
private static final Pattern USERNAME_PATTERN = Pattern.compile(
"^[a-zA-Z][a-zA-Z0-9_]{2,19}$" // starts with letter, 3-20 chars, only alphanumeric and _
);
private static final Pattern DATE_PATTERN = Pattern.compile(
"^(?\\d{4})-(?0[1-9]|1[0-2])-(?0[1-9]|[12]\\d|3[01])$"
);
public static Map validateRegistration(
String username, String email, String password, String phone, String birthDate) {
Map errors = new LinkedHashMap<>();
// Username validation
if (username == null || username.isEmpty()) {
errors.put("username", "Username is required");
} else if (!USERNAME_PATTERN.matcher(username).matches()) {
errors.put("username", "Must start with a letter, 3-20 chars, only letters/digits/underscore");
}
// Email validation
if (email == null || email.isEmpty()) {
errors.put("email", "Email is required");
} else if (!EMAIL_PATTERN.matcher(email).matches()) {
errors.put("email", "Invalid email format");
}
// Password validation with specific feedback
if (password == null || password.isEmpty()) {
errors.put("password", "Password is required");
} else {
List passwordIssues = new ArrayList<>();
if (password.length() < 8) passwordIssues.add("at least 8 characters");
if (password.length() > 20) passwordIssues.add("at most 20 characters");
if (!password.matches(".*[A-Z].*")) passwordIssues.add("an uppercase letter");
if (!password.matches(".*[a-z].*")) passwordIssues.add("a lowercase letter");
if (!password.matches(".*\\d.*")) passwordIssues.add("a digit");
if (!password.matches(".*[@#$%^&+=!].*")) passwordIssues.add("a special character (@#$%^&+=!)");
if (!passwordIssues.isEmpty()) {
errors.put("password", "Password needs: " + String.join(", ", passwordIssues));
}
}
// Phone validation
if (phone != null && !phone.isEmpty() && !PHONE_PATTERN.matcher(phone).matches()) {
errors.put("phone", "Invalid US phone format");
}
// Birth date validation
if (birthDate != null && !birthDate.isEmpty()) {
Matcher dm = DATE_PATTERN.matcher(birthDate);
if (!dm.matches()) {
errors.put("birthDate", "Invalid date format (use YYYY-MM-DD)");
} else {
int year = Integer.parseInt(dm.group("year"));
if (year > 2026 || year < 1900) {
errors.put("birthDate", "Year must be between 1900 and 2026");
}
}
}
return errors;
}
// =========================================================================
// Part 3: Data Masking -- Redact sensitive information from text
// =========================================================================
private static final Pattern SSN_IN_TEXT = Pattern.compile(
"\\b\\d{3}-\\d{2}-\\d{4}\\b"
);
private static final Pattern CC_IN_TEXT = Pattern.compile(
"\\b(\\d{4})[- ]?(\\d{4})[- ]?(\\d{4})[- ]?(\\d{4})\\b"
);
private static final Pattern EMAIL_IN_TEXT = Pattern.compile(
"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}"
);
public static String maskSensitiveData(String text) {
// Mask SSNs: 123-45-6789 -> ***-**-6789
String result = SSN_IN_TEXT.matcher(text).replaceAll(mr -> {
String ssn = mr.group();
return "***-**-" + ssn.substring(ssn.length() - 4);
});
// Mask credit cards: show only last 4 digits
Matcher ccMatcher = CC_IN_TEXT.matcher(result);
StringBuilder sb = new StringBuilder();
while (ccMatcher.find()) {
ccMatcher.appendReplacement(sb, "****-****-****-" + ccMatcher.group(4));
}
ccMatcher.appendTail(sb);
result = sb.toString();
// Mask emails: user@domain.com -> u***@domain.com
Matcher emailMatcher = EMAIL_IN_TEXT.matcher(result);
sb = new StringBuilder();
while (emailMatcher.find()) {
String email = emailMatcher.group();
int atIndex = email.indexOf('@');
String masked = email.charAt(0) + "***" + email.substring(atIndex);
emailMatcher.appendReplacement(sb, Matcher.quoteReplacement(masked));
}
emailMatcher.appendTail(sb);
return sb.toString();
}
// =========================================================================
// Main -- Run all demonstrations
// =========================================================================
public static void main(String[] args) {
// --- Part 1: Parse log entries ---
String[] logLines = {
"2026-02-28 14:30:00 [INFO] com.app.UserService - User login from 192.168.1.100",
"2026-02-28 14:30:05 [ERROR] com.app.PaymentService - Payment failed: ERR-5001 for IP 10.0.0.1",
"2026-02-28 14:30:10 [WARN] com.app.AuthService - Failed login attempt from 172.16.0.50",
"2026-02-28 14:30:15 [ERROR] com.app.OrderService - Order processing failed: HTTP-500 timeout",
"2026-02-28 14:30:20 [INFO] com.app.CacheService - Cache refreshed successfully",
"2026-02-28 14:30:25 [ERROR] com.app.DatabaseService - Connection lost: DB-1001 to 192.168.1.200"
};
parseLogEntries(logLines);
System.out.println();
System.out.println("========================================");
System.out.println();
// --- Part 2: Validate registration forms ---
System.out.println("=== REGISTRATION VALIDATION ===");
System.out.println();
// Test case 1: Valid registration
Map errors1 = validateRegistration(
"john_doe", "john@example.com", "MyP@ss123", "(555) 123-4567", "1990-06-15"
);
System.out.println("Test 1 (valid): " + (errors1.isEmpty() ? "PASSED" : "FAILED: " + errors1));
// Test case 2: Multiple validation failures
Map errors2 = validateRegistration(
"2bad", "not-an-email", "weak", "12345", "2026-13-45"
);
System.out.println("Test 2 (invalid):");
errors2.forEach((field, error) -> System.out.println(" " + field + ": " + error));
// Test case 3: Specific password feedback
Map errors3 = validateRegistration(
"alice", "alice@test.com", "onlylowercase", null, null
);
System.out.println("Test 3 (weak password):");
errors3.forEach((field, error) -> System.out.println(" " + field + ": " + error));
System.out.println();
System.out.println("========================================");
System.out.println();
// --- Part 3: Mask sensitive data ---
System.out.println("=== DATA MASKING ===");
System.out.println();
String sensitiveText = "Customer SSN: 123-45-6789, CC: 4111-1111-1111-1111, " +
"Email: john.doe@gmail.com, Alt SSN: 987-65-4321";
System.out.println("Original: " + sensitiveText);
System.out.println("Masked: " + maskSensitiveData(sensitiveText));
}
}
Output
=== LOG PARSER RESULTS === IP found in log: 192.168.1.100 (from com.app.UserService) IP found in log: 10.0.0.1 (from com.app.PaymentService) Error code found: ERR-5001 (at 2026-02-28 14:30:05) IP found in log: 172.16.0.50 (from com.app.AuthService) Error code found: HTTP-500 (at 2026-02-28 14:30:15) Error code found: DB-1001 (at 2026-02-28 14:30:25) IP found in log: 192.168.1.200 (from com.app.DatabaseService) Log Level Summary: INFO: 2 ERROR: 3 WARN: 1 Error Messages: 2026-02-28 14:30:05 | com.app.PaymentService | Payment failed: ERR-5001 for IP 10.0.0.1 2026-02-28 14:30:15 | com.app.OrderService | Order processing failed: HTTP-500 timeout 2026-02-28 14:30:25 | com.app.DatabaseService | Connection lost: DB-1001 to 192.168.1.200 ======================================== === REGISTRATION VALIDATION === Test 1 (valid): PASSED Test 2 (invalid): username: Must start with a letter, 3-20 chars, only letters/digits/underscore email: Invalid email format password: Password needs: at least 8 characters, an uppercase letter, a digit, a special character (@#$%^&+=!) phone: Invalid US phone format birthDate: Invalid date format (use YYYY-MM-DD) Test 3 (weak password): password: Password needs: an uppercase letter, a digit, a special character (@#$%^&+=!) ======================================== === DATA MASKING === Original: Customer SSN: 123-45-6789, CC: 4111-1111-1111-1111, Email: john.doe@gmail.com, Alt SSN: 987-65-4321 Masked: Customer SSN: ***-**-6789, CC: ****-****-****-1111, Email: j***@gmail.com, Alt SSN: ***-**-4321
Concepts Demonstrated
| # | Concept | Where Used |
|---|---|---|
| 1 | Pattern compilation and reuse | static final Pattern fields throughout |
| 2 | Named capturing groups | LOG_PATTERN: (?<timestamp>...), (?<level>...), (?<class>...), (?<message>...) |
| 3 | find() with while loop | IP address and error code extraction from log messages |
| 4 | matches() for full-string validation | All validators: email, phone, username, password, date |
| 5 | Lookaheads for password rules | PASSWORD_PATTERN uses (?=.*[A-Z]), (?=.*\\d), etc. |
| 6 | Word boundaries | SSN_IN_TEXT, CC_IN_TEXT, ERROR_CODE_PATTERN use \\b |
| 7 | appendReplacement / appendTail | Credit card and email masking with custom replacement logic |
| 8 | replaceAll with Function (Java 9+) | SSN masking: replaceAll(mr -> ...) |
| 9 | Matcher.quoteReplacement() | Email masking: prevents $ and \ in replacement from being interpreted |
| 10 | Numbered capturing groups | CC_IN_TEXT: group(4) to get last 4 digits |
| 11 | Group extraction for further processing | Date validation: extracting year for range check |
| 12 | Multiple regex patterns working together | Log parser uses 3 patterns; validator uses 5 patterns; masker uses 3 patterns |
| 13 | Breaking complex validation into steps | Password validation gives specific feedback per rule instead of one giant regex |
| 14 | Null-safe validation | All validators check for null before applying regex |
Chat System
A chat app performs different functions for different people. It is extremely important to nail down the exact requirements. For example, you do not want to design a system that focuses on group chat when the interviewer has one-on-one chat in mind. It is important to explore the feature requirements.
It is vital to agree on the type of chat app to design. In the marketplace, there are one-on-one chat apps like Facebook Messenger, WeChat, and WhatsApp, office chat apps that focus on group chat like Slack, or game chat apps, like Discord, that focus on large group interaction and low voice chat latency.
The first set of clarification questions should nail down what the interviewer has in mind exactly when she asks you to design a chat system. At the very least, figure out if you should focus on a one-on-one chat or group chat app.
Questions to ask for exact scope
What kind of chat app shall we design? 1 on 1 or group based? – It should support both 1 on 1 and group chat.
Is this a mobile app? Or a web app? Or both? – both
What is the scale of this app? A startup app or massive scale? – It should support 50 million daily active users (DAU).
For group chat, what is the group member limit? – A maximum of 100 people
What features are important for the chat app? Can it support attachment? – 1 on 1 chat, group chat, online indicator. The system only supports text messages.
Is there a message size limit? – Yes, text length should be less than 100,000 characters long.
Is end-to-end encryption required? – Not required for now but we will discuss that if time allows.
How long shall we store the chat history? – forever
These are the requirements based on the questions above:
- A one-on-one chat with low delivery latency
- Small group chat (max of 100 people)
- Online presence
- Multiple device support. The same account can be logged in to multiple accounts at the same time.
- Push notifications
Clients do not communicate directly with each other. Instead, each client connects to a chat service, which supports all the features mentioned above. Let us focus on fundamental operations. The chat service must support the following functions:
- Receive messages from other clients.
- Find the right recipients for each message and relay the message to the recipients.
- If a recipient is not online, hold the messages for that recipient on the server until she is online.

When a client intends to start a chat, it connects the chats service using one or more network protocols. For a chat service, the choice of network protocols is important.
Requests are initiated by the client for most client/server applications. This is also true for the sender side of a chat application. When the sender sends a message to the receiver via the chat service, it uses the time-tested HTTP protocol, which is the most common web protocol. In this scenario, the client opens a HTTP connection with the chat service and sends the message, informing the service to send the message to the receiver. However, the receiver side is a bit more complicated. Since HTTP is client-initiated, it is not trivial to send messages from the server. Over the years, many techniques are used to simulate a server-initiated connection: polling, long polling, and WebSocket.
Polling – polling is a technique that the client periodically asks the server if there are messages available. Depending on polling frequency, polling could be costly. It could consume precious server resources to answer a question that offers no as an answer most of the time.
Long Polling – in long polling, a client holds the connection open until there are actually new messages available or a timeout threshold has been reached. Once the client receives new messages, it immediately sends another request to the server, restarting the process. Long polling has a few drawbacks:
- Sender and receiver may not connect to the same chat server. HTTP based servers are usually stateless. If you use round robin for load balancing, the server that receives the message might not have a long-polling connection with the client who receives the message.
- A server has no good way to tell if a client is disconnected.
- It is inefficient. If a user does not chat much, long polling still makes periodic connections after timeouts.
Websocket – webSocket is the most common solution for sending asynchronous updates from server to client. WebSocket connection is initiated by the client. It is bi-directional and persistent. It starts its life as a HTTP connection and could be “upgraded” via some well-defined handshake to a WebSocket connection. Through this persistent connection, a server could send updates to a client.
- WebSocket connections generally work even if a firewall is in place. This is because they use port 80 or 443 which are also used by HTTP/HTTPS connections.
- Earlier we said that on the sender side HTTP is a fine protocol to use, but since WebSocket is bidirectional, there is no strong technical reason not to use it also for sending.
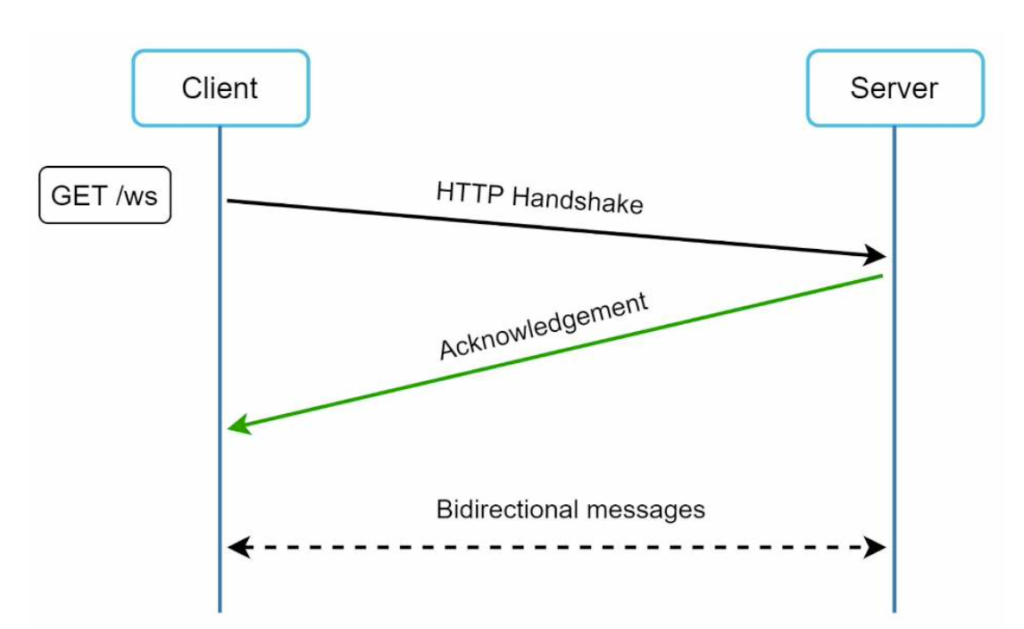
Scalability
No technologist would design such a scale in a single server. Single server design is a deal breaker due to many factors. The single point of failure is the biggest among them. We suggest having a presence server.
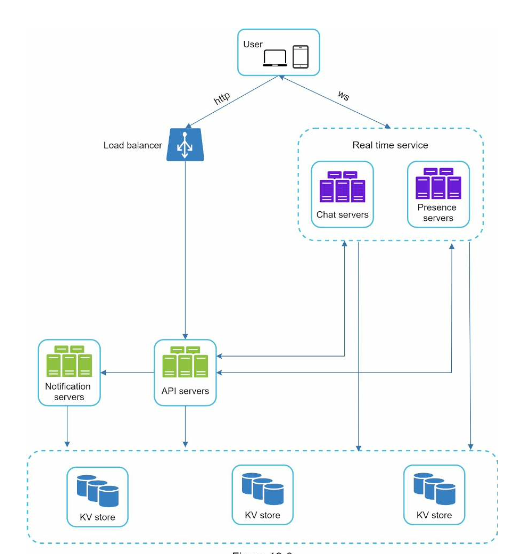
Here the client maintains a persistent WebSocket connection to a chat server for real-time messaging.
- Chat servers facilitate message sending/receiving.
- Presence servers manage online/offline status.
- API servers handle everything including user login, signup, change profile, etc.
- Notification servers send push notifications.
- Finally, the key-value store is used to store chat history. When an offline user comes online, she will see all her previous chat history.
Storage
Selecting the correct storage system that supports all of our use cases is crucial. We recommend key-value stores for the following reasons:
- Key-value stores allow easy horizontal scaling.
- Key-value stores provide very low latency to access data.
- Relational databases do not handle long tail of data well. When the indexes grow large, random access is expensive.
- Key-value stores are adopted by other proven reliable chat applications. For example, both Facebook messenger and Discord use key-value stores. Facebook messenger uses HBase, and Discord uses Cassandra.
One on One chat flow
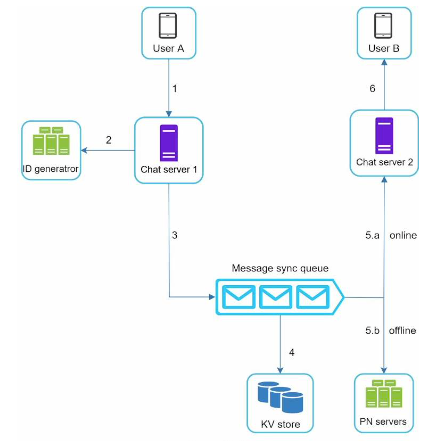
- User A sends a chat message to Chat server 1.
- Chat server 1 obtains a message ID from the ID generator.
- Chat server 1 sends the message to the message sync queue.
- The message is stored in a key-value store.
- If User B is online, the message is forwarded to Chat server 2 where User B is connected
- If User B is offline, a push notification is sent from push notification (PN) servers.
- Chat server 2 forwards the message to User B. There is a persistent WebSocket connection between User B and Chat server 2.
Message synchronization across multiple devices
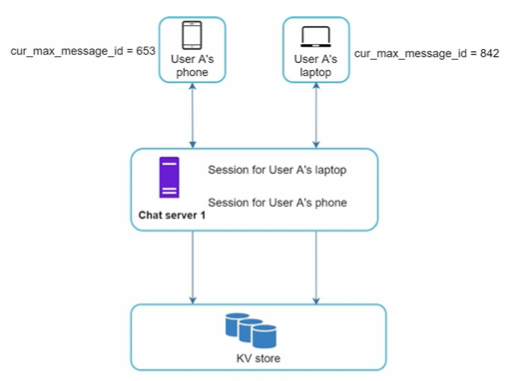
Each device maintains a variable called cur_max_message_id, which keeps track of the latest message ID on the device. Messages that satisfy the following two conditions are considered as news messages:
- The recipient ID is equal to the currently logged-in user ID.
- Message ID in the key-value store is larger than cur_max_message_id .
With distinct cur_max_message_id on each device, message synchronization is easy as each device can get new messages from the KV store.
Group chat
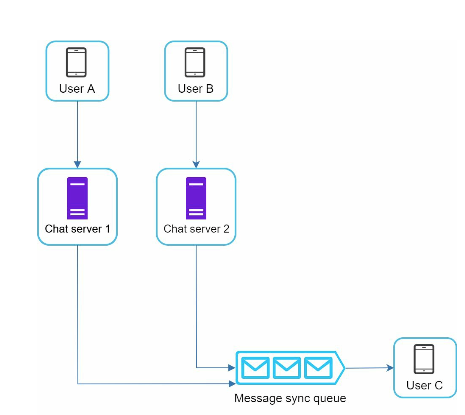
Unique ID Generator
In this chapter, you are asked to design a unique ID generator for a distributed system. Your first thought might be to use a primary key with the auto_increment attribute in a traditional database. However, auto_increment does not work in a distributed environment because a single database server is not large enough and generating unique IDs across multiple databases with minimal delay is challenging.
Here is an example.

Questions to ask for clear scope
What are the characteristics of unique IDs? – IDs must be unique and sortable.
For each new record, does ID increment by 1? – The ID increments by time but not necessarily only increments by 1. IDs created in the evening are larger than those created in the morning on the same day.
Do IDs only contain numerical values? – Yes, that is correct.
What is the ID length requirement? – IDs should fit into 64-bit.
What is the scale of the system? – The system should be able to generate 10,000 IDs per second.
Now here are the requirements gathered from questions above:
- IDs must be unique.
- IDs are numerical values only.
- IDs fit into 64-bit.
- IDs are ordered by date.
- Ability to generate over 10,000 unique IDs per second.
Solution

Datacenter IDs and machine IDs are chosen at the startup time, generally fixed once the system is up running. Any changes in datacenter IDs and machine IDs require careful review since an accidental change in those values can lead to ID conflicts. Timestamp and sequence numbers are generated when the ID generator is running.
Timestamp
The most important 41 bits make up the timestamp section. As timestamps grow with time, IDs are sortable by time. Figure below shows an example of how binary representation is converted to UTC. You can also convert UTC back to binary representation using a similar method.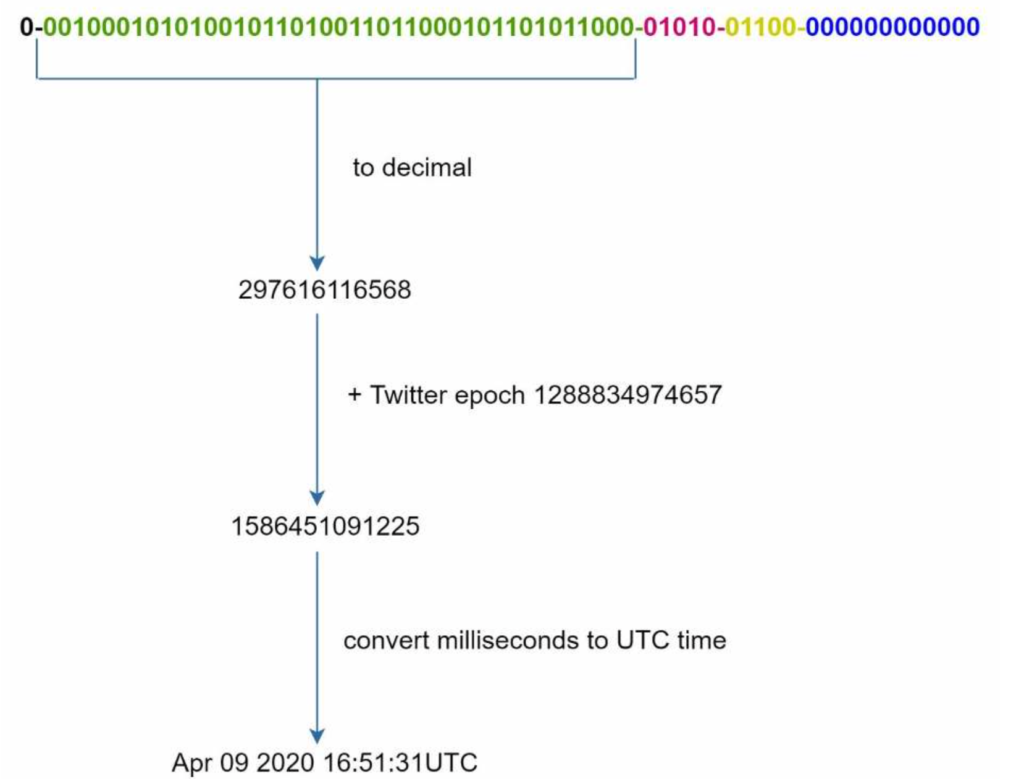
Sequence number
12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
There are other alternatives but they don’t work as well as the soluton above according to our requirements.
UUID is worth mentioning here as an alternative. If our requirements include that IDs are 128 bits long instead of 64 bits long or can be non-numeric then UUID will work.