Spring Data JPA Annotations
@Entity
@Entity anotation declares a class as an entity.
@Table(name="tbl_sky")
@Table anotation defines the table, catalog, and schema name for your entity.
@Id
@Id defines the unique identifier for your entity.
@Column
@Column defines a column and its characteristics such as column name, column updatable or not, etc
@GeneratedValue
@GeneratedValue defines how the id column is generated.
@OnDelete defines what orphan tables should do on delete
@OnDelete(action = OnDeleteAction.CASCADE)
Spring Data Configuration
1.Create a spring boot project. Spring Initializer
For dependencies, select the following,
a. JPA
b. MySQL Driver
c. Web
<!-- spring data --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <!-- spring web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- mysql driver --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency>
Import your project to your favorite IDE. I am using Spring suite tool for this tutorial.
2. Add these configurations to your application.properties file.
spring.datasource.url=jdbc:mysql://localhost:3306/spring_data?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=UTC spring.datasource.username=root spring.datasource.password= spring.datasource.name=spring_data spring.datasource.driver-class-name=com.mysql.jdbc.Driver
Note: createDatabaseIfNotExist=true will create your database if it does not exist. It’s for development only.
3. Create a database in your localhost called spring_data. I am using MySQL Workbench.
4. Create a User class
package com.lovemesomecoding.user;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
public User() {
super();
// TODO Auto-generated constructor stub
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
5. Create a UserRepository interface that implements JpaRepository
package com.lovemesomecoding.user;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
That is all the configuration we have to do. As you can see, spring boot makes it easy for us to get up and running. There is not a lot of configurations to do before writing code. It’s one of the reasons why I love spring boot.
Checkout Source Code On Github
Introduction To Spring Data JPA
Hi and welcome to my Spring Data JPA tutorial. This tutorial is not for a beginner programmer. If you are new to programming and you want to learn about database checkout my SQL tutorial. If you are new to programming and you want to learn how code is connected and managing database data check out my java database tutorial.
This tutorial is for those who are interested in learning about what an ORM or Object Relational Mapping is.
Requirements for this tutorial:
a. Have a strong understanding of Java
b. Understand basic SQL operations
Url Shortener
Here we are going to design a url shortener system.
Questions for clear scope
Can you give an example of how a URL shortener work? – https://www.systeminterview.com/q=chatsystem&c=loggedin&v=v3&l=long
What is the traffic volume? – 100 million URLs are generated per day.
How long is the shortened URL? – as short as possible
What characters are allowed in the shortened URL? – Shortened URL can be a combination of numbers (0-9) and characters (a-z, A- Z).
Can shortened URLs be deleted or updated? – For simplicity, let us assume shortened URLs cannot be deleted or updated.
Here are the basic use cases:
- URL shortening: given a long URL => return a much shorter URL
- URL redirecting: given a shorter URL => redirect to the original URL
- High availability, scalability, and fault tolerance considerations
Solution with Base 62 conversion
Base conversion is an approach commonly used for URL shorteners. Base conversion helps to convert the same number between its different number representation systems. Base 62 conversion is used as there are 62 possible characters for hashValue.
Conversion of 11157 to base 62
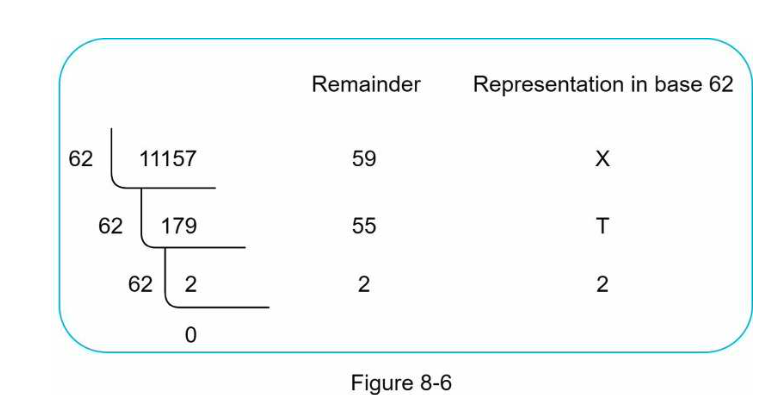
The short url is https://tinyurl.com/2TX
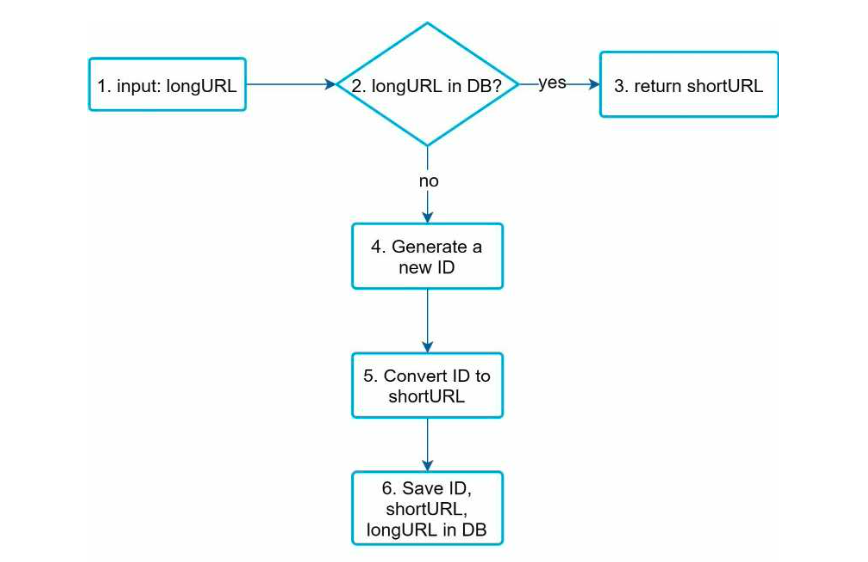
- longURL is the input.
- The system checks if the longURL is in the database.
- If it is, it means the longURL was converted to shortURL before. In this case, fetch the shortURL from the database and return it to the client.
- If not, the longURL is new. A new unique ID (primary key) Is generated by the unique ID generator.
- Convert the ID to shortURL with base 62 conversion.
- Create a new database row with the ID, shortURL, and longURL.
To make the flow easier to understand, let us look at a concrete example.
- Assuming the input longURL is: https://en.wikipedia.org/wiki/Systems_design • Unique ID generator returns ID: 2009215674938.
- Convert the ID to shortURL using the base 62 conversion. ID (2009215674938) is converted to “zn9edcu”.
- Save ID, shortURL, and longURL to the database

Comparison of Hash solution vs Base 62 conversion
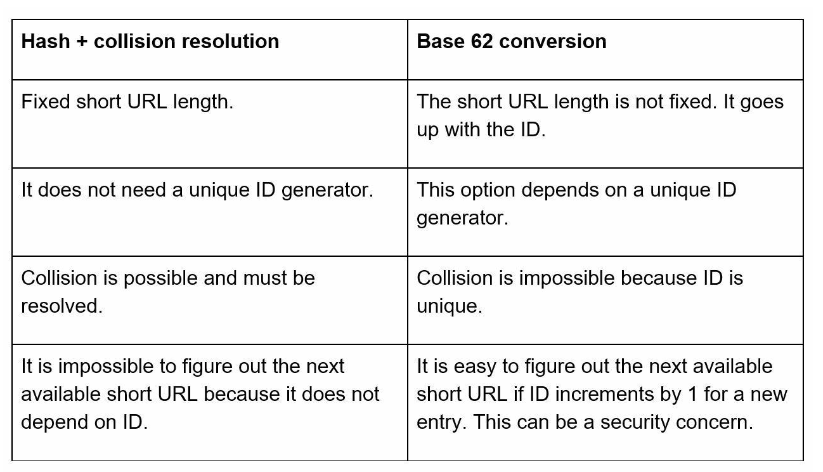
As you can see Base 62 conversion is the clear winner.
Java For Loop
What Are Loops?
A loop is a programming construct that repeats a block of code as long as a specified condition remains true. Without loops, you would have to write the same line of code hundreds or thousands of times to perform repetitive tasks.
Think of it this way: imagine you are a teacher grading 30 exams. You do not write 30 separate instructions like “grade exam 1,” “grade exam 2,” and so on. Instead, you follow one instruction: “Pick up the next exam and grade it. Repeat until there are no more exams.” That is exactly how a loop works in programming.
Java provides four types of loops, each suited to different situations:
- for loop — when you know exactly how many times to iterate
- enhanced for loop (for-each) — when you want to iterate over every element in a collection or array
- while loop — when the number of iterations depends on a condition evaluated before each pass
- do-while loop — when the loop body must execute at least once before checking the condition
Let us explore each one in detail with practical, runnable examples.
1. The For Loop
The for loop is the most commonly used loop in Java. It is ideal when you know in advance how many times the loop should execute. It packs three expressions into one compact line: initialization, condition, and update.
Syntax
for (initialization; condition; update) {
// statement(s) executed on each iteration
}
How It Works — Step by Step
- Initialization — Runs once when the loop starts. Typically declares and initializes a counter variable (e.g.,
int i = 0). - Condition — Evaluated before each iteration. If
true, the loop body executes. Iffalse, the loop terminates immediately. - Loop body — The statement(s) inside the curly braces execute.
- Update — Runs after the loop body completes. Usually increments or decrements the counter.
- Control returns to step 2.
Example: Counting Up
for (int i = 1; i <= 5; i++) {
System.out.println("Count: " + i);
}
// Output:
// Count: 1
// Count: 2
// Count: 3
// Count: 4
// Count: 5
Example: Counting Down
for (int i = 5; i >= 1; i--) {
System.out.println("Countdown: " + i);
}
// Output:
// Countdown: 5
// Countdown: 4
// Countdown: 3
// Countdown: 2
// Countdown: 1
Example: Stepping by 2 (Even Numbers)
for (int i = 0; i <= 10; i += 2) {
System.out.println("Even: " + i);
}
// Output:
// Even: 0
// Even: 2
// Even: 4
// Even: 6
// Even: 8
// Even: 10
Example: Looping Through an Array
The traditional for loop gives you direct access to the index, which is useful when you need to know the position of each element or when you need to modify elements in place.
String[] languages = {"Java", "Python", "JavaScript", "Go", "Rust"};
for (int i = 0; i < languages.length; i++) {
System.out.println("Language #" + (i + 1) + ": " + languages[i]);
}
// Output:
// Language #1: Java
// Language #2: Python
// Language #3: JavaScript
// Language #4: Go
// Language #5: Rust
Example: Sum of Numbers
A common pattern is accumulating a result across iterations. Here we compute the sum of the first 100 positive integers.
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
System.out.println("Sum of 1 to 100: " + sum);
// Output:
// Sum of 1 to 100: 5050
2. Enhanced For Loop (For-Each)
Introduced in Java 5, the enhanced for loop (also called for-each) provides a cleaner, more readable way to iterate over arrays and collections. It eliminates the need for an index variable and removes the risk of off-by-one errors.
Syntax
for (DataType variable : arrayOrCollection) {
// use variable
}
Read it as: "for each element in the array or collection, do something."
Example: Iterating Over an Array
int[] scores = {95, 87, 76, 92, 88};
for (int score : scores) {
System.out.println("Score: " + score);
}
// Output:
// Score: 95
// Score: 87
// Score: 76
// Score: 92
// Score: 88
Example: Iterating Over a List (Collection)
import java.util.List;
import java.util.ArrayList;
List<String> cities = new ArrayList<>();
cities.add("New York");
cities.add("London");
cities.add("Tokyo");
cities.add("Sydney");
for (String city : cities) {
System.out.println("City: " + city);
}
// Output:
// City: New York
// City: London
// City: Tokyo
// City: Sydney
Example: Iterating Over a Map
import java.util.Map;
import java.util.HashMap;
Map<String, Integer> ages = new HashMap<>();
ages.put("Alice", 30);
ages.put("Bob", 25);
ages.put("Charlie", 35);
for (Map.Entry<String, Integer> entry : ages.entrySet()) {
System.out.println(entry.getKey() + " is " + entry.getValue() + " years old");
}
Limitations of For-Each
The enhanced for loop is convenient, but it has limitations you should be aware of:
- No index access — You cannot directly know which iteration number you are on. If you need the index, use a traditional
forloop. - Cannot modify elements in place — The loop variable is a copy. Assigning a new value to it does not change the original array or collection element.
- Forward-only, single pass — You cannot iterate backwards or skip elements.
int[] numbers = {1, 2, 3, 4, 5};
// This does NOT modify the original array
for (int num : numbers) {
num = num * 2; // modifies the local copy only
}
// The array is unchanged
for (int num : numbers) {
System.out.print(num + " ");
}
// Output: 1 2 3 4 5
// To actually modify elements, use a traditional for loop
for (int i = 0; i < numbers.length; i++) {
numbers[i] = numbers[i] * 2;
}
for (int num : numbers) {
System.out.print(num + " ");
}
// Output: 2 4 6 8 10
3. While Loop
The while loop repeats a block of code as long as its condition evaluates to true. Unlike the for loop, it does not have built-in initialization or update expressions, making it ideal for situations where you do not know in advance how many iterations are needed.
Syntax
while (condition) {
// statement(s)
// update the condition variable to avoid infinite loop
}
The condition is checked before each iteration. If the condition is false from the start, the loop body never executes.
Example: Basic While Loop
int count = 1;
while (count <= 5) {
System.out.println("Count: " + count);
count++;
}
// Output:
// Count: 1
// Count: 2
// Count: 3
// Count: 4
// Count: 5
Example: Input Validation
A common real-world use of while is validating user input. You keep asking until the user provides a valid response. Since you do not know how many attempts the user will need, a while loop is the right choice.
import java.util.Scanner;
Scanner scanner = new Scanner(System.in);
int age = -1;
System.out.print("Enter your age (1-120): ");
age = scanner.nextInt();
while (age < 1 || age > 120) {
System.out.print("Invalid age. Please enter a value between 1 and 120: ");
age = scanner.nextInt();
}
System.out.println("Your age is: " + age);
Example: Processing Until a Sentinel Value
Another classic use case is reading values until a special "sentinel" value signals the end. Think of it like reading lines from a file until you reach the end-of-file marker.
import java.util.Scanner;
Scanner scanner = new Scanner(System.in);
int total = 0;
int number;
System.out.println("Enter numbers to sum (enter 0 to finish):");
number = scanner.nextInt();
while (number != 0) {
total += number;
number = scanner.nextInt();
}
System.out.println("Total sum: " + total);
// Example interaction:
// Enter numbers to sum (enter 0 to finish):
// 10
// 20
// 30
// 0
// Total sum: 60
Example: Finding Greatest Common Divisor (Euclid's Algorithm)
The while loop is natural for algorithms where the number of steps depends on the input values.
int a = 48;
int b = 18;
System.out.println("Finding GCD of " + a + " and " + b);
while (b != 0) {
int temp = b;
b = a % b;
a = temp;
}
System.out.println("GCD: " + a);
// Output:
// Finding GCD of 48 and 18
// GCD: 6
4. Do-While Loop
The do-while loop is similar to the while loop with one key difference: it checks the condition after executing the loop body, which guarantees the body runs at least once. This makes it perfect for scenarios like displaying a menu where the user must see the options before making a choice.
Syntax
do {
// statement(s) - always executes at least once
} while (condition);
Note the semicolon after the while(condition). This is required and is a common source of syntax errors.
While vs. Do-While
// while - condition checked BEFORE execution
// If condition is false initially, body never runs
int x = 10;
while (x < 5) {
System.out.println("This will NOT print");
}
// do-while - condition checked AFTER execution
// Body always runs at least once
int y = 10;
do {
System.out.println("This WILL print once, even though y >= 5");
} while (y < 5);
// Output:
// This WILL print once, even though y >= 5
Example: Menu-Driven Program
The do-while loop is the natural choice for menu systems. You want to display the menu, process the user's choice, and repeat until they choose to exit.
import java.util.Scanner;
Scanner scanner = new Scanner(System.in);
int choice;
do {
System.out.println("\n===== Calculator Menu =====");
System.out.println("1. Add");
System.out.println("2. Subtract");
System.out.println("3. Multiply");
System.out.println("4. Divide");
System.out.println("5. Exit");
System.out.print("Enter your choice: ");
choice = scanner.nextInt();
switch (choice) {
case 1:
System.out.println("You selected Add");
// perform addition logic
break;
case 2:
System.out.println("You selected Subtract");
// perform subtraction logic
break;
case 3:
System.out.println("You selected Multiply");
// perform multiplication logic
break;
case 4:
System.out.println("You selected Divide");
// perform division logic
break;
case 5:
System.out.println("Goodbye!");
break;
default:
System.out.println("Invalid choice. Try again.");
}
} while (choice != 5);
Example: Input Validation with Do-While
Compare this to the while version above. The do-while version is more concise because you do not need a separate read before the loop.
import java.util.Scanner;
Scanner scanner = new Scanner(System.in);
int age;
do {
System.out.print("Enter your age (1-120): ");
age = scanner.nextInt();
} while (age < 1 || age > 120);
System.out.println("Your age is: " + age);
5. Nested Loops
A nested loop is a loop inside another loop. The inner loop completes all of its iterations for each single iteration of the outer loop. If the outer loop runs m times and the inner loop runs n times, the total number of inner-loop executions is m × n.
Example: Multiplication Table
System.out.println("Multiplication Table (1-5):");
System.out.println("-----------------------------");
for (int i = 1; i <= 5; i++) {
for (int j = 1; j <= 5; j++) {
System.out.printf("%4d", i * j);
}
System.out.println();
}
// Output:
// Multiplication Table (1-5):
// -----------------------------
// 1 2 3 4 5
// 2 4 6 8 10
// 3 6 9 12 15
// 4 8 12 16 20
// 5 10 15 20 25
Example: 2D Array Traversal
Nested loops are essential for working with two-dimensional arrays (matrices). The outer loop iterates over rows, and the inner loop iterates over columns.
int[][] matrix = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
System.out.println("Matrix contents:");
for (int row = 0; row < matrix.length; row++) {
for (int col = 0; col < matrix[row].length; col++) {
System.out.printf("%4d", matrix[row][col]);
}
System.out.println();
}
// Output:
// Matrix contents:
// 1 2 3
// 4 5 6
// 7 8 9
// Finding the sum of all elements
int sum = 0;
for (int[] row : matrix) {
for (int value : row) {
sum += value;
}
}
System.out.println("Sum of all elements: " + sum);
// Output: Sum of all elements: 45
Example: Pattern Printing (Triangle of Stars)
Pattern printing is a classic exercise that demonstrates how nested loops work. Pay close attention to how the inner loop's limit depends on the outer loop's variable.
// Right triangle
int rows = 5;
for (int i = 1; i <= rows; i++) {
for (int j = 1; j <= i; j++) {
System.out.print("* ");
}
System.out.println();
}
// Output:
// *
// * *
// * * *
// * * * *
// * * * * *
System.out.println();
// Inverted triangle
for (int i = rows; i >= 1; i--) {
for (int j = 1; j <= i; j++) {
System.out.print("* ");
}
System.out.println();
}
// Output:
// * * * * *
// * * * *
// * * *
// * *
// *
6. Loop Control Statements
Java provides three statements that alter the normal flow of a loop: break, continue, and labeled versions of both for nested loops.
break — Exit the Loop Early
The break statement immediately terminates the innermost loop and transfers control to the statement after the loop.
// Search for a value in an array
String[] names = {"Alice", "Bob", "Charlie", "Diana", "Edward"};
String target = "Charlie";
int foundIndex = -1;
for (int i = 0; i < names.length; i++) {
if (names[i].equals(target)) {
foundIndex = i;
break; // no need to continue searching
}
}
if (foundIndex != -1) {
System.out.println("Found '" + target + "' at index " + foundIndex);
} else {
System.out.println("'" + target + "' not found");
}
// Output: Found 'Charlie' at index 2
continue — Skip the Current Iteration
The continue statement skips the rest of the current iteration and jumps to the next one. The loop does not terminate; it simply moves on to the next cycle.
// Print only odd numbers from 1 to 10
for (int i = 1; i <= 10; i++) {
if (i % 2 == 0) {
continue; // skip even numbers
}
System.out.println("Odd: " + i);
}
// Output:
// Odd: 1
// Odd: 3
// Odd: 5
// Odd: 7
// Odd: 9
Labeled break and continue (For Nested Loops)
In nested loops, a plain break or continue only affects the innermost loop. To break out of or continue an outer loop, you use a label. A label is an identifier followed by a colon, placed before a loop.
// Labeled break: search a 2D array and exit both loops when found
int[][] grid = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
int searchValue = 5;
outerLoop:
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
if (grid[i][j] == searchValue) {
System.out.println("Found " + searchValue + " at position [" + i + "][" + j + "]");
break outerLoop; // breaks out of BOTH loops
}
}
}
// Output: Found 5 at position [1][1]
// Labeled continue: skip the rest of the outer loop's current iteration
outerLoop:
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 3; j++) {
if (j == 2) {
continue outerLoop; // skip to next i
}
System.out.println("i=" + i + ", j=" + j);
}
}
// Output:
// i=1, j=1
// i=2, j=1
// i=3, j=1
// (j=2 and j=3 are never reached because continue outerLoop skips them)
7. Infinite Loops
An infinite loop is a loop whose condition never becomes false, so it runs forever. In most cases, an infinite loop is a bug caused by forgetting to update the loop variable or writing a condition that can never be satisfied. However, there are legitimate use cases for intentional infinite loops.
Accidental Infinite Loop (Bug)
// BUG: i is always >= 1 because it starts at 1 and increments
for (int i = 1; i >= 1; i++) {
System.out.println("i is " + i);
// This will run until i overflows Integer.MAX_VALUE
}
// BUG: forgot to increment count
int count = 0;
while (count < 10) {
System.out.println("Stuck forever...");
// count++ is missing!
}
Intentional Infinite Loops
Some programs are designed to run continuously until an external event or explicit break stops them. Game loops, server listeners, and event processors are common examples.
// Server-style loop: process requests until shutdown command
import java.util.Scanner;
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("Enter command (type 'quit' to exit): ");
String command = scanner.nextLine();
if (command.equalsIgnoreCase("quit")) {
System.out.println("Shutting down...");
break;
}
System.out.println("Processing command: " + command);
}
// Game loop pattern (pseudocode)
// while (true) {
// processInput();
// updateGameState();
// render();
// if (gameOver) break;
// }
All three loop types can express an infinite loop:
// Infinite for loop
for (;;) {
// runs forever
break; // unless you break
}
// Infinite while loop (most common and readable)
while (true) {
// runs forever
break; // unless you break
}
// Infinite do-while loop
do {
// runs forever
break; // unless you break
} while (true);
8. Common Mistakes
Even experienced developers make loop-related mistakes. Being aware of these pitfalls will save you debugging time.
Off-by-One Errors
The most frequent loop bug. It happens when your loop runs one time too many or one time too few, usually because of confusion between < and <= or between starting at 0 vs. 1.
String[] fruits = {"Apple", "Banana", "Cherry"};
// BUG: ArrayIndexOutOfBoundsException
// Array indices go from 0 to length-1, but <= goes one too far
for (int i = 0; i <= fruits.length; i++) { // should be < not <=
System.out.println(fruits[i]);
}
// CORRECT
for (int i = 0; i < fruits.length; i++) {
System.out.println(fruits[i]);
}
Modifying a Collection While Iterating
Adding or removing elements from a collection while iterating over it with a for-each loop throws a ConcurrentModificationException. Use an Iterator with its remove() method instead, or collect items to remove and do it after the loop.
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
names.add("Diana");
// BUG: ConcurrentModificationException
// for (String name : names) {
// if (name.startsWith("C")) {
// names.remove(name); // CANNOT modify collection during for-each
// }
// }
// CORRECT: Use Iterator.remove()
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
String name = iterator.next();
if (name.startsWith("C")) {
iterator.remove(); // safe removal during iteration
}
}
System.out.println(names);
// Output: [Alice, Bob, Diana]
// ALTERNATIVE: Use removeIf() (Java 8+)
// names.removeIf(name -> name.startsWith("C"));
Semicolon After the For Statement
Accidentally placing a semicolon right after the for statement creates an empty loop body. The intended body then executes only once, after the loop completes.
// BUG: semicolon makes the loop body empty
for (int i = 0; i < 5; i++); // <-- this semicolon is the entire loop body
{
System.out.println("This prints only once, not 5 times");
}
// CORRECT
for (int i = 0; i < 5; i++) {
System.out.println("Iteration: " + i);
}
Using == Instead of .equals() for Strings in Conditions
String[] words = {"hello", "world", "java"};
String target = new String("java");
// BUG: == compares references, not content
for (String word : words) {
if (word == target) {
System.out.println("Found with =="); // may not print
}
}
// CORRECT: .equals() compares content
for (String word : words) {
if (word.equals(target)) {
System.out.println("Found with .equals()"); // prints correctly
}
}
9. Best Practices
Following these guidelines will make your loops cleaner, safer, and more maintainable.
Choose the Right Loop Type
| Scenario | Best Loop | Why |
|---|---|---|
| Known number of iterations | for |
All loop logic in one line |
| Iterating over every element | for-each |
Cleanest syntax, no index bugs |
| Unknown iterations, check first | while |
May not execute at all |
| Must execute at least once | do-while |
Condition checked after body |
| Functional style, transformations | Streams | Declarative, chainable |
Keep Loop Bodies Small
If your loop body exceeds 10-15 lines, consider extracting the body into a separate method. This improves readability and makes the code easier to test.
// Instead of a large loop body...
for (Order order : orders) {
// 20+ lines of processing logic
}
// Extract into a method
for (Order order : orders) {
processOrder(order);
}
private void processOrder(Order order) {
// processing logic here
}
Prefer For-Each When You Do Not Need the Index
The enhanced for loop is not just shorter — it eliminates an entire class of bugs (wrong index, off-by-one). Always use it when you simply need to process each element.
List<String> names = List.of("Alice", "Bob", "Charlie");
// Verbose and error-prone
for (int i = 0; i < names.size(); i++) {
System.out.println(names.get(i));
}
// Clean and safe
for (String name : names) {
System.out.println(name);
}
Consider Streams for Functional Style (Java 8+)
For data transformation and filtering, Java Streams offer a declarative alternative to loops. They are especially powerful when chaining multiple operations.
import java.util.List;
import java.util.stream.Collectors;
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// Traditional loop: filter even numbers and double them
List<Integer> result = new ArrayList<>();
for (int num : numbers) {
if (num % 2 == 0) {
result.add(num * 2);
}
}
System.out.println(result);
// Output: [4, 8, 12, 16, 20]
// Stream equivalent: more concise and declarative
List<Integer> streamResult = numbers.stream()
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.collect(Collectors.toList());
System.out.println(streamResult);
// Output: [4, 8, 12, 16, 20]
Avoid Recomputing Values in the Condition
// Inefficient: size() is called on every iteration
for (int i = 0; i < expensiveList.size(); i++) {
// ...
}
// Better: compute once
int size = expensiveList.size();
for (int i = 0; i < size; i++) {
// ...
}
// Note: For ArrayList, size() is O(1) so this is a micro-optimization.
// But for custom data structures with expensive size calculations, it matters.
10. Quick Reference Summary
| Loop Type | Syntax | When to Use |
|---|---|---|
| for | for (init; cond; update) { } |
Known number of iterations, need index |
| for-each | for (Type x : collection) { } |
Iterate all elements, no index needed |
| while | while (cond) { } |
Unknown iterations, may not run at all |
| do-while | do { } while (cond); |
Must run at least once |
| Control Statement | Effect |
|---|---|
break |
Exit the current loop immediately |
continue |
Skip to the next iteration |
break label |
Exit the labeled outer loop |
continue label |
Skip to the next iteration of the labeled outer loop |