Spring Data Many To Many Mapping
In this tutorial we will learn about how many to many works and what it does.
Many to many represents two entities that can have multiple instances on the other. For example here a user can have many roles(user,manager,admin,etc) and a role can have many users.
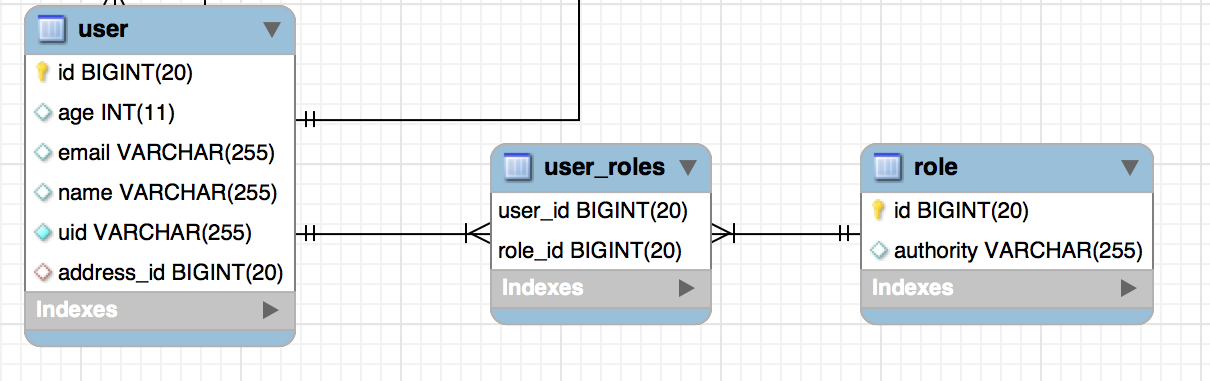
Note that one entity can have a many-to-many relationship with itself. A many-to-many relationship does not have to be with two separate entities. For example, a child can have two parents and a parent can have many children.
We now have to choose the parent and the child sides. In our
One the parent side we have a Set of roles annotated with the @ManyToMany annotation. We also use the @JoinTable annotation to
@ManyToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL)
@JoinTable(
name = "user_roles",
joinColumns = { @JoinColumn(name = "user_id") },
inverseJoinColumns = { @JoinColumn(name = "role_id") })
private Set<Role> roles;
package com.lovemesomecoding.user;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.ManyToMany;
import javax.persistence.OneToMany;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.address.Address;
import com.lovemesomecoding.laptop.Laptop;
import com.lovemesomecoding.order.Order;
import com.lovemesomecoding.role.Role;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
@JsonIgnoreProperties(value= {"users"})
@ManyToMany(fetch=FetchType.EAGER, cascade=CascadeType.ALL)
@JoinTable(
name = "user_roles",
joinColumns = { @JoinColumn(name = "user_id") },
inverseJoinColumns = { @JoinColumn(name = "role_id") })
private Set<Role> roles;
public User() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
On the child side of the relationship, we use the @ManyToMany annotation and also the mappedBy attribute.
@ManyToMany(mappedBy="roles", fetch=FetchType.EAGER) private Set<User> users;
package com.lovemesomecoding.role;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.ManyToMany;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.user.User;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "role")
public class Role implements Serializable {
private static final long serialVersionUID = 1L;
public static final String USER = "USER";
public static final String ADMIN = "ADMIN";
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "authority")
private String authority;
@ManyToMany(mappedBy="roles", fetch=FetchType.EAGER)
private Set<User> users;
public Role() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
Many-To-Many with a more complex associative table.
March 18, 2019Spring Data Many To One Mapping
The many to one mapping is from the one-to-many relationship. It is from the child side of the one-to-many relationship. Check out the one to many relationship here.
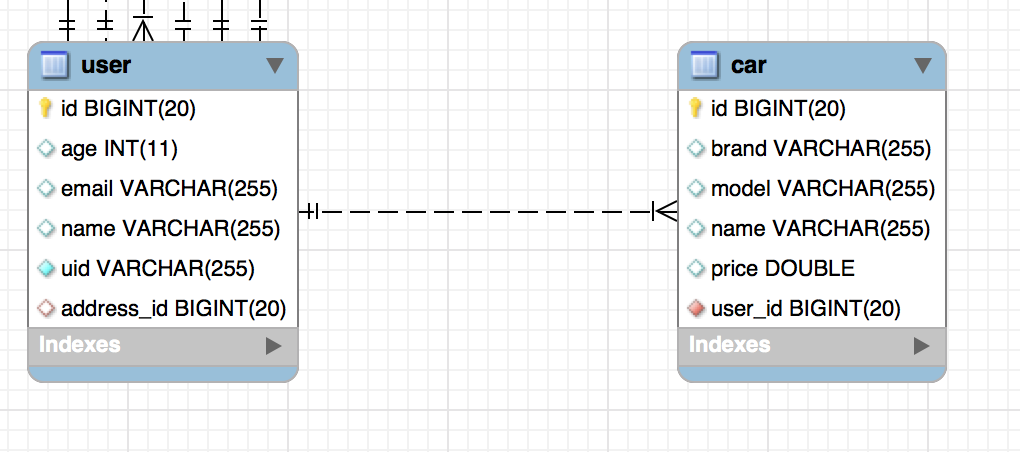
Many to one relationship mean that many instances of some entity can have a relationship with only one instance of another entity. For example, many cars can belong to only one person or user.
Many to One Bidirectional
package com.lovemesomecoding.car;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.user.User;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "car")
public class Car implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "brand")
private String brand;
@Column(name = "model")
private String model;
@Column(name = "price")
private Double price;
@JsonIgnoreProperties(value= {"cars"})
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "user_id", nullable=false)
private User user;
public Car() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
package com.lovemesomecoding.user;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.ManyToMany;
import javax.persistence.OneToMany;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.car.Car;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
@JsonIgnoreProperties(value= {"user"})
@OneToMany(mappedBy = "user", cascade=CascadeType.ALL, fetch=FetchType.EAGER)
private Set<Car> cars;
public User() {
super();
// TODO Auto-generated constructor stub
}
// getters and setters
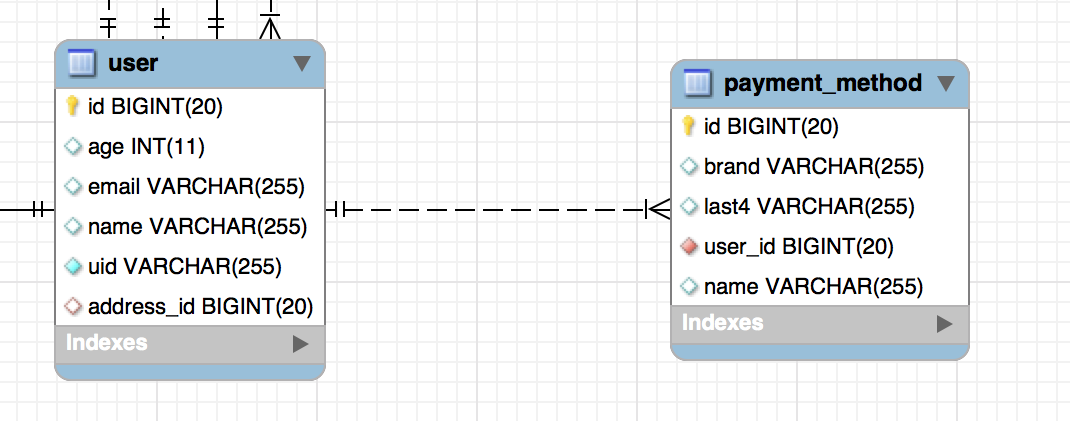
Many to One Unidirectional
It’s very useful to map an entity to another entity which does not map back. This is a perfect solution in a situation where you are not using the child class very often. For example, you have a
package com.lovemesomecoding.paymentmethod;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.user.User;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "payment_method")
public class PaymentMethod implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "brand")
private String brand;
@Column(name = "last4")
private String last4;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "user_id", nullable=false)
private User user;
public PaymentMethod() {
super();
// TODO Auto-generated constructor stub
}
// getters and setters
March 18, 2019 Spring Data One To Many Mapping
One-To-Many relationship is used widely in database operations. For exampel a user can have multiple cars or a user can have multiple computer screens to work with.
Our example is a user can have multiple orders as in a restaurant order. Let’s suppose you are asked to develop a pizza restaurant application where customers can order online. a User can have multiple orders.
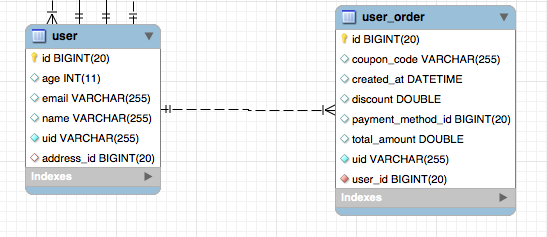
One-To-Many Bidirectional Relationship
// On the parent side which is the User class. @OneToMany(mappedBy="user",cascade=CascadeType.ALL,fetch=FetchType.EAGER) private Set<Order> orders;
// On the child side which is the Order class. @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "user_id", nullable=false) private User user;
package com.lovemesomecoding.user;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.order.Order;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
@JsonIgnoreProperties(value= {"user"})
@OneToMany(mappedBy = "user", cascade=CascadeType.ALL, fetch=FetchType.EAGER)
private Set<Order> orders;
public User() {
super();
// TODO Auto-generated constructor stub
}
// getters and setters
public void addOrder(Order order) {
if(this.orders == null){
this.orders = new HashSet<>();
}
this.orders.add(order);
}
}
package com.lovemesomecoding.order;
import java.io.Serializable;
import java.time.LocalDateTime;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import org.hibernate.annotations.CreationTimestamp;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.user.User;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user_order")
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "coupon_code")
private String couponCode;
@Column(name = "discount")
private Double discount;
@Column(name = "total_amount")
private Double totalAmount;
@Column(name = "payment_method_id")
private Long paymentMethodId;
@CreationTimestamp
@Column(name = "created_at")
private Date createdAt;
@JsonIgnoreProperties(value= {"orders"})
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "user_id", nullable=false)
private User user;
public Order() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
}
One-To-Many Unidirectional Relationship
It depends on the needs you might have. If you need to access orders from the User class then you use this below:
// On the parent side(User class) @OneToMany(cascade=CascadeType.ALL, fetch=FetchType.EAGER) private Set<Order> orders;
or if you need to access a user from the Order class then your use this below:
// On the child side(Order class) @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "user_id", nullable=false) private User user;
My preference and what I recommend is to use bidirectional. Using unidirectional will slow down your system as it creates an extra join for the
Use mappedBy on the @OneToMany otherwise, it will create a reference or associative table.
@JoinColumn is always on the owing side or the child side of the relationship.
March 18, 2019Spring Data One To One Mapping
One to One defines as one entity is related to a single instance of another entity.
Example of One to One
1. a user is related to a single address(home address).
2. a post has a post details table
3. a stock has a stock details table
4. an employee has a single computer
Let’s suppose we have to build a user management system. We are asked to create a user table, an address table, and a laptop table.
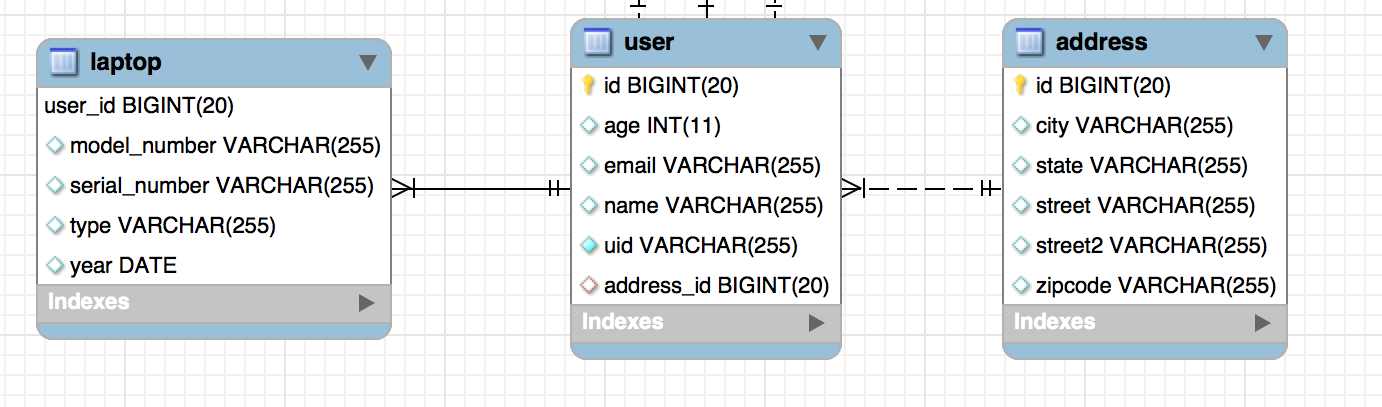
Unidirectional Relationship
In a unidirectional relationship, only one entity has a relationship field or property that refers to the other entity.
The user will have a one to one relationship with a home address. This relationship is
package com.lovemesomecoding.user;
import java.io.Serializable;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.address.Address;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
@JsonIgnoreProperties(value= {"address"})
@OneToOne(fetch=FetchType.LAZY, cascade=CascadeType.ALL)
@JoinColumn(name="address_id", updatable = false, nullable=false, unique=true)
private Address address;
public User() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
}
package com.lovemesomecoding.address;
import java.io.Serializable;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "address")
public class Address implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "street")
private String street;
@Column(name = "street2")
private String street2;
@Column(name = "city")
private String city;
@Column(name = "state")
private String state;
@Column(name = "zipcode")
private String zip;
public Address() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
}
Bidirectional Relationship
In a bidirectional relationship, each entity has a relationship field or property that refers to the other entity. The User class has a reference to the Laptop class and vice versa.
package com.lovemesomecoding.user;
import java.io.Serializable;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
import org.apache.commons.lang3.builder.ToStringBuilder;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.address.Address;
import com.lovemesomecoding.laptop.Laptop;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "uid", unique = true, nullable=false, updatable=false)
private String uid;
@Column(name = "name")
private String name;
@Column(name = "email")
private String email;
@Column(name = "age")
private int age;
@JsonIgnoreProperties(value= {"user"})
@OneToOne(fetch=FetchType.LAZY, cascade=CascadeType.ALL, mappedBy="user")
private Laptop laptop;
public User() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
}
Note here that I used the @MapsId annotation so that the Laptop class will use the User class id value as its
package com.lovemesomecoding.laptop;
import java.io.Serializable;
import java.time.LocalDate;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.MapsId;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import com.lovemesomecoding.user.User;
@JsonInclude(value = Include.NON_NULL)
@Entity
@Table(name = "laptop")
public class Laptop implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@Column(name = "id", nullable = false, updatable = false, unique = true)
private Long id;
@Column(name = "type")
private String type;
@Column(name = "serial_number")
private String serialNumber;
@Column(name = "model_number")
private String modelNumber;
@Column(name = "year")
private LocalDate year;
@JsonIgnoreProperties(value= {"laptop"})
@OneToOne
@JoinColumn(name="user_id")
@MapsId
private User user;
public Laptop() {
super();
// TODO Auto-generated constructor stub
}
// setters and getters
}
Check out the source code in Github
March 18, 2019